
 |
人工智能领域正在经历一场深刻的变革。随着深度学习模型的规模呈指数级增长,我们正面临着前所未有的计算挑战。当前最先进的语言模型动辄包含数千亿个参数,这种规模的模型训练已经远远超出了单机系统的处理能力。在这个背景下,分布式机器学习系统已经成为支撑现代人工智能发展的关键基础设施。
分布式机器学习的演进
在深度学习早期,研究人员通常使用单个GPU就能完成模型训练。随着研究的深入,模型架构变得越来越复杂,参数量急剧增长。这种增长首先突破了单GPU的内存限制,迫使研究人员开始探索模型并行等技术。仅仅解决内存问题是不够的。训练时间的持续增长很快成为另一个瓶颈,这促使了数据并行训练方案的发展。
现代深度学习面临的挑战更为严峻。数据规模已经从最初的几个GB扩展到TB甚至PB级别,模型参数量更是达到了数千亿的规模。在这种情况下,即使采用最基础的分布式训练方案也无法满足需求。我们需要一个全方位的分布式训练系统,它不仅要解决计算和存储的问题,还要处理数据管理、通信优化、容错机制等多个层面的挑战。
分布式训练的核心问题
在构建分布式训练系统时,面临着几个根本性的挑战。首先是通信开销问题。在传统的数据并行训练中,每个计算节点都需要频繁地同步模型参数和梯度。随着节点数量的增加,通信开销会迅速成为系统的主要瓶颈。这要求我们必须采用各种优化技术,如梯度压缩、通信计算重叠等,来提高通信效率。
同步策略的选择是另一个关键问题。同步SGD虽然能保证训练的确定性,但可能因为节点间的速度差异导致整体训练速度受限于最慢的节点。而异步SGD虽然能提高系统吞吐量,但可能引入梯度延迟,影响模型收敛。在实际系统中,常常需要在这两种策略间寻找平衡点。
内存管理也同样至关重要。现代深度学习模型的参数量和中间激活值大小已经远超单个设备的内存容量。这要求我们必须精心设计参数分布策略,合理规划计算和存储资源。近年来兴起的ZeRO优化技术就是解决这一问题的典型方案,它通过对优化器状态、梯度和模型参数进行分片,显著降低了每个设备的内存需求。
分布式训练的基本范式
分布式训练最基本的范式是数据并行。这种方式的核心思想是将训练数据分散到多个计算节点,每个节点维护完整的模型副本,通过参数服务器或集合通信来同步梯度信息。数据并行的优势在于实现简单、扩展性好,但它要求每个节点都能存储完整的模型参数。
当模型规模超过单个设备的内存容量时,需要转向模型并行方案。模型并行的核心是将模型参数分布到多个设备上,每个设备只负责部分参数的计算和存储。这种方式虽然能够处理超大规模模型,但实现复杂度较高,且需要精心设计以平衡计算负载和减少设备间通信。
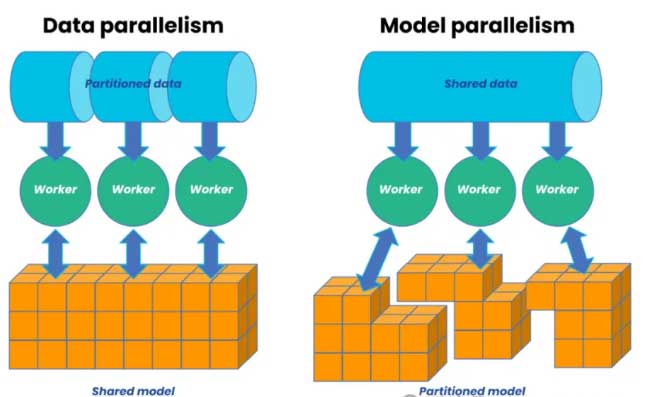
在实际应用中,往往需要将这些基本范式结合起来形成混合并行方案。例如可能在模型架构层面采用流水线并行,在参数层面使用张量并行,同时在外层使用数据并行。这种混合策略能够更好地利用系统资源,但也带来了更高的系统复杂度。
面向未来的系统设计
随着人工智能技术的持续发展,分布式训练系统还将面临更多新的挑战。模型规模的进一步增长、新型计算硬件的出现、对训练效率的更高要求,这些都将推动分布式训练系统向更复杂、更智能的方向发展。在这个过程中,如何在保持系统可用性的同时不断提升性能和可扩展性,将是一个持续的挑战。
接下来的章节中,我们将深入探讨分布式训练系统的各个核心组件,包括参数服务器的实现、训练器的设计、数据加载优化等关键技术,以及在实际部署中的最佳实践。通过这些内容希望能够帮助读者更好地理解和构建现代分布式机器学习系统。
参数服务器架构设计
参数服务器的基本原理
参数服务器(Parameter Server)是分布式机器学习系统中的核心组件,负责管理和同步模型参数。它采用中心化的参数存储和更新机制,支持高效的分布式训练。
关键特性
-
分片存储
-
将模型参数分散存储在多个服务器节点
-
支持动态扩展和容错
-
通过一致性哈希等机制实现负载均衡
-
-
异步更新
-
支持非阻塞的参数更新操作
-
使用版本管理确保一致性
-
提供灵活的同步策略配置
-
-
通信优化
-
参数压缩和稀疏更新
-
流水线化的通信机制
-
带宽感知的调度策略
-
具体实现
以下是一个高效的分布式参数服务器实现:
class DistributedParameterServer:
def __init__(self, world_size: int, num_shards: int):
self.world_size = world_size
self.num_shards = num_shards
# 跨节点存储的参数分片
self.parameter_shards = [
torch.zeros(shard_size, requires_grad=True)
for _ in range(num_shards)
]
# 无锁更新缓冲区
self.update_buffers = {
shard_id: AsyncUpdateBuffer(buffer_size=1024)
for shard_id in range(num_shards)
}
# 初始化通信
self.initialize_communication()
def initialize_communication(self):
# 设置 NCCL 用于 GPU 通信
self.comm = ncclGetUniqueId()
torch.distributed.init_process_group(
backend='nccl',
init_method='env://',
world_size=self.world_size,
rank=dist.get_rank()
)
# 为异步操作创建 CUDA 流
self.streams = [
torch.cuda.Stream()
for _ in range(self.num_shards)
]
核心功能解析
-
参数分片管理
-
通过
parameter_shards实现参数的分布式存储 -
每个分片独立管理,支持并行访问
-
使用PyTorch的自动微分机制追踪梯度
-
-
异步更新机制
-
AsyncUpdateBuffer实现高效的更新累积 -
使用无锁数据结构最小化同步开销
-
支持批量更新提高吞吐量
-
-
CUDA流管理
-
为每个分片创建独立的CUDA流
-
实现计算和通信的重叠
-
提高GPU利用率
-
参数更新流程
async def apply_updates(self, shard_id: int, updates: torch.Tensor):
buffer = self.update_buffers[shard_id]
# 在缓冲区中排队更新
buffer.push(updates)
# 如果缓冲区已满则处理更新
if buffer.is_full():
with torch.cuda.stream(self.streams[shard_id]):
# 聚合更新
aggregated = buffer.aggregate()
# 将更新应用到参数
self.parameter_shards[shard_id].add_(
aggregated,
alpha=self.learning_rate
)
# 清空缓冲区
buffer.clear()
# 全局规约更新后的参数
torch.distributed.all_reduce(
self.parameter_shards[shard_id],
op=torch.distributed.ReduceOp.SUM,
async_op=True
)
这个实现包含几个关键优化:
-
批量处理
-
累积多个更新后一次性应用
-
减少通信次数
-
提高计算效率
-
-
异步操作
-
使用异步all-reduce操作
-
通过CUDA流实现并行处理
-
最小化同步等待时间
-
-
内存优化
-
及时清理更新缓冲区
-
使用就地更新减少内存分配
-
通过流水线化减少峰值内存使用
-
分布式训练器设计与实现
训练器架构
分布式训练器是整个系统的核心组件,负责协调数据加载、前向传播、反向传播和参数更新等过程。一个高效的训练器需要处理多个关键问题:
-
混合精度训练
-
使用FP16减少显存使用
-
维护FP32主权重保证数值稳定性
-
动态损失缩放预防梯度下溢
-
-
梯度累积
-
支持大批量训练
-
减少通信开销
-
提高内存效率
-
-
优化器集成
-
支持ZeRO优化器
-
CPU卸载机制
-
通信优化策略
-
训练器实现
以下是一个完整的分布式训练器实现:
class DistributedTrainer:
def __init__(
self,
model: nn.Module,
optimizer: Type[torch.optim.Optimizer],
world_size: int,
gradient_accumulation_steps: int = 1
):
self.model = model
self.world_size = world_size
self.grad_accum_steps = gradient_accumulation_steps
# 封装模型用于分布式训练
self.model = DistributedDataParallel(
model,
device_ids=[local_rank],
output_device=local_rank,
find_unused_parameters=True
)
# 使用 ZeRO 优化初始化优化器
self.optimizer = ZeROOptimizer(
optimizer,
model,
overlap_comm=True,
cpu_offload=True
)
# 用于混合精度的梯度缩放器
self.scaler = GradScaler()
# 设置梯度分桶
self.grad_buckets = initialize_grad_buckets(
model,
bucket_size_mb=25
)
训练步骤实现
@torch.cuda.amp.autocast()
def train_step(
self,
batch: Dict[str, torch.Tensor]
) -> torch.Tensor:
# 前向传播
outputs = self.model(**batch)
loss = outputs.loss
# 缩放损失用于梯度累积
scaled_loss = loss / self.grad_accum_steps
# 使用缩放后的损失进行反向传播
self.scaler.scale(scaled_loss).backward()
return loss.detach()
def optimize_step(self):
# 等待所有梯度计算完成
torch.cuda.synchronize()
# 反缩放梯度
self.scaler.unscale_(self.optimizer)
# 裁剪梯度
torch.nn.utils.clip_grad_norm_(
self.model.parameters(),
max_norm=1.0
)
# 使用梯度分桶进行优化
for bucket in self.grad_buckets:
# 同步分桶梯度
bucket.synchronize()
# 应用更新
self.scaler.step(
self.optimizer,
bucket_idx=bucket.index
)
# 清空分桶梯度
bucket.zero_grad()
# 更新缩放器
self.scaler.update()
训练循环的实现需要考虑多个方面的优化:
-
评估策略
-
定期进行模型评估
-
支持分布式评估
-
维护最佳检查点
-
-
状态同步
-
确保所有节点状态一致
-
处理训练中断和恢复
-
支持检查点保存和加载
-
def train_epoch(
self,
dataloader: DataLoader,
epoch: int,
eval_steps: int
):
self.model.train()
step = 0
total_loss = 0
# 训练循环
for batch in dataloader:
# 将批次数据移至 GPU
batch = {
k: v.to(self.device)
for k, v in batch.items()
}
# 计算损失
loss = self.train_step(batch)
total_loss += loss.item()
step += 1
# 累积步数后优化
if step % self.grad_accum_steps == 0:
self.optimize_step()
# 定期评估
if step % eval_steps == 0:
self.evaluate(step, epoch)
self.model.train()
性能优化策略
-
计算优化
-
使用混合精度训练
-
梯度累积减少通信
-
梯度分桶优化通信
-
-
内存优化
-
ZeRO优化器减少内存使用
-
CPU卸载机制
-
梯度检查点技术
-
-
通信优化
-
使用NCCL后端
-
异步通信操作
-
通信计算重叠
-
分布式训练系统的深入优化
混合精度训练的实现细节
混合精度训练是现代分布式训练系统的重要组成部分。它不仅可以减少显存使用,还能提高训练速度。但实现高效稳定的混合精度训练需要注意以下关键点:
动态损失缩放是确保FP16训练稳定性的关键机制:
class DynamicLossScaler:
def __init__(self, init_scale=2**15, scale_factor=2, scale_window=2000):
self.cur_scale = init_scale
self.scale_factor = scale_factor
self.scale_window = scale_window
self.num_overflows = 0
self.num_steps = 0
def scale(self, loss):
return loss * self.cur_scale
def update_scale(self, overflow):
self.num_steps += 1
if overflow:
self.num_overflows += 1
if self.num_steps % self.scale_window == 0:
if self.num_overflows == 0:
self.cur_scale *= self.scale_factor
else:
self.cur_scale /= self.scale_factor
self.num_overflows = 0
梯度累积的高级特性
梯度累积不仅用于处理显存限制,还能提供额外的训练优势:
-
噪声平滑:累积多个小批次的梯度可以降低梯度估计的方差
-
内存效率:通过分散计算减少峰值显存使用
-
通信优化:减少参数同步频率,降低通信开销
class GradientAccumulator:
def __init__(self, model, accumulation_steps):
self.model = model
self.accumulation_steps = accumulation_steps
self.stored_gradients = {}
self._initialize_gradient_storage()
def _initialize_gradient_storage(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.stored_gradients[name] = torch.zeros_like(param)
def accumulate_gradients(self):
with torch.no_grad():
for name, param in self.model.named_parameters():
if param.requires_grad and param.grad is not None:
self.stored_gradients[name] += param.grad / self.accumulation_steps
param.grad = None
def apply_accumulated_gradients(self):
with torch.no_grad():
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.stored_gradients[name]
self.stored_gradients[name].zero_()
ZeRO优化器的工作原理
ZeRO(Zero Redundancy Optimizer)通过三个阶段的优化显著减少显存使用:
阶段1:优化器状态分片
优化器状态(如Adam的动量和方差)在工作节点间进行分片:
class ZeROStage1Optimizer:
def __init__(self, optimizer, dp_process_group):
self.optimizer = optimizer
self.dp_process_group = dp_process_group
self.world_size = dist.get_world_size(dp_process_group)
self.rank = dist.get_rank(dp_process_group)
self._partition_optimizer_state()
def _partition_optimizer_state(self):
for group in self.optimizer.param_groups:
for p in group['params']:
if p.requires_grad:
state = self.optimizer.state[p]
# 将优化器状态分片到不同节点
for k, v in state.items():
if torch.is_tensor(v):
partitioned = self._partition_tensor(v)
state[k] = partitioned
def _partition_tensor(self, tensor):
# 计算每个进程的分片大小
partition_size = tensor.numel() // self.world_size
start_idx = partition_size * self.rank
end_idx = start_idx + partition_size
return tensor.view(-1)[start_idx:end_idx]
阶段2:梯度分片
在阶段1的基础上添加梯度分片,进一步减少显存使用:
def backward(self, loss):
loss.backward()
# 对梯度进行分片
for name, param in self.model.named_parameters():
if param.requires_grad:
# 仅保留本节点负责的梯度分片
grad_partition = self._partition_gradient(param.grad)
param.grad = grad_partition
def _partition_gradient(self, gradient):
partition_size = gradient.numel() // self.world_size
start_idx = partition_size * self.rank
end_idx = start_idx + partition_size
return gradient.view(-1)[start_idx:end_idx]
阶段3:参数分片
最后一个阶段实现参数分片,实现最大程度的显存节省:
def forward(self, *args, **kwargs):
# 在前向传播前收集完整参数
self._gather_parameters()
output = self.module(*args, **kwargs)
# 释放完整参数
self._release_parameters()
return output
def _gather_parameters(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
# 从所有节点收集完整参数
full_param = self._all_gather_parameter(param)
self.temp_params[name] = param.data
param.data = full_param
def _release_parameters(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
# 恢复到分片状态
param.data = self.temp_params[name]
高级训练特性
为了处理超大模型,可以实现梯度检查点机制:
class GradientCheckpointing:
def __init__(self, model, checkpoint_layers):
self.model = model
self.checkpoint_layers = checkpoint_layers
self.saved_activations = {}
def forward_with_checkpoint(self, x):
activations = []
for i, layer in enumerate(self.model.layers):
if i in self.checkpoint_layers:
# 保存输入,释放中间激活值
activations.append(x.detach())
x = layer(x)
else:
x = layer(x)
return x, activations
通过这些深入的优化和实现细节,我们的分布式训练系统可以更好地处理大规模模型训练的挑战。这些机制相互配合,共同提供了一个高效、可扩展的训练框架。
高效的分布式数据加载系统
数据加载的重要性
在分布式机器学习系统中,数据加载往往成为制约训练效率的关键瓶颈。随着模型规模的增长,每个训练步骤的计算时间相应增加,这要求数据加载系统能够及时提供下一批次的训练数据,避免GPU空等待。一个高效的数据加载系统需要解决以下核心问题:
-
数据分片与均衡
-
确保训练数据均匀分布到各个节点
-
处理数据倾斜问题
-
支持动态负载调整
-
-
预取与缓存
-
实现异步数据预取
-
合理利用内存缓存
-
优化磁盘I/O性能
-
-
内存管理
-
控制内存使用峰值
-
实现高效的数据传输
-
优化CPU到GPU的数据移动
-
分布式数据加载器实现
以下是一个针对性能优化的分布式数据加载器实现:
class DistributedDataLoader:
def __init__(
self,
dataset: Dataset,
batch_size: int,
world_size: int,
rank: int,
num_workers: int = 4,
prefetch_factor: int = 2
):
# 跨节点分片数据集
self.sampler = DistributedSampler(
dataset,
num_replicas=world_size,
rank=rank,
shuffle=True
)
# 创建高效的数据加载器
self.dataloader = DataLoader(
dataset,
batch_size=batch_size,
sampler=self.sampler,
num_workers=num_workers,
pin_memory=True,
prefetch_factor=prefetch_factor,
persistent_workers=True
)
# 预取缓冲区
self.prefetch_queue = Queue(maxsize=prefetch_factor)
self.prefetch_stream = torch.cuda.Stream()
# 启动预取工作进程
self.start_prefetch_workers()
数据预取是提高训练效率的关键机制。通过异步预取下一批次数据可以显著减少GPU的等待时间:
def start_prefetch_workers(self):
def prefetch_worker():
while True:
# 获取下一个批次
batch = next(self.dataloader.__iter__())
with torch.cuda.stream(self.prefetch_stream):
# 将批次数据移至 GPU
batch = {
k: v.pin_memory().to(
self.device,
non_blocking=True
)
for k, v in batch.items()
}
# 添加到队列
self.prefetch_queue.put(batch)
# 启动预取线程
self.prefetch_threads = [
threading.Thread(target=prefetch_worker)
for _ in range(2)
]
for thread in self.prefetch_threads:
thread.daemon = True
thread.start()
数据加载优化策略
-
内存钉存(Pin Memory)
-
使用页锁定内存加速GPU传输
-
减少CPU到GPU的数据拷贝开销
-
支持异步数据传输
-
-
持久化工作进程
-
避免频繁创建销毁工作进程
-
维持预热的数据加载管道
-
提高数据加载稳定性
-
-
异步数据传输
-
利用CUDA流实现异步传输
-
通过预取隐藏数据加载延迟
-
优化CPU-GPU数据移动
-
性能优化与监控
在实际部署中,还需要考虑以下几个关键方面:
-
性能指标监控
-
数据加载延迟
-
GPU利用率
-
内存使用情况
-
磁盘I/O负载
-
-
自适应优化
-
动态调整预取深度
-
根据负载调整工作进程数
-
优化批次大小
-
-
故障处理
-
优雅处理数据加载异常
-
支持断点续传
-
实现自动重试机制
-
系统优化与最佳实践
在深度学习领域,从实验室原型到生产级系统的转变往往充满挑战。一个高效的分布式训练系统不仅需要正确的实现,更需要全方位的性能优化。这种优化是一个渐进的过程,需要从通信、计算、内存等多个维度进行系统性的改进。
通信系统的优化
在分布式训练中,通信效率往往是决定系统性能的关键因素。当在数千个GPU上训练模型时,如果没有经过优化的通信机制,大量的时间都会浪费在参数同步上。为了解决这个问题,现代分布式训练系统采用了一系列创新的通信优化技术。
梯度压缩是最基础的优化手段之一。通过对梯度进行量化或稀疍化处理,可以显著减少需要传输的数据量。例如,8位量化可以将通信带宽需求减少75%,而且在许多情况下对模型收敛几乎没有影响。更激进的压缩方案,如深度梯度压缩,甚至可以将梯度压缩到原始大小的1%以下。
拓扑感知通信是另一个重要的优化方向。在大规模集群中,不同节点之间的网络带宽和延迟可能存在显著差异。通过感知底层网络拓扑,可以优化通信路由,最大化带宽利用率。例如在有InfiniBand网络的集群中,可以优先使用RDMA通信,并根据节点间的物理距离调整通信策略。
内存管理
随着模型规模的增长,内存管理已经成为分布式训练中最具挑战性的问题之一。现代语言模型动辄需要数百GB的显存,这远超单个GPU的容量。因此,高效的内存管理策略变得至关重要。
显存优化需要多管齐下。首先是通过梯度检查点技术减少激活值存储。在深度网络中,激活值通常占用的显存远大于模型参数。通过战略性地丢弃和重计算中间激活值,可以在适度增加计算量的情况下显著减少显存使用。
ZeRO优化器代表了当前最先进的内存优化技术。它通过对优化器状态、梯度和模型参数进行分片,实现了接近线性的显存减少。这种方法不仅降低了单个设备的内存压力,还提供了出色的可扩展性。在实践中合理配置ZeRO的不同阶段对于获得最佳性能至关重要。
训练稳定性的保障
在追求性能的同时,维持训练的稳定性同样重要。分布式环境下的训练过程面临着更多的不确定性,需要采取额外的措施来确保可靠性。
混合精度训练是现代分布式系统的标配,但它也带来了数值稳定性的挑战。动态损失缩放是解决这个问题的关键。通过自适应调整损失的缩放因子,可以在保持FP16训练效率的同时,避免梯度下溢带来的问题。
容错机制是另一个不容忽视的方面。在大规模训练中,硬件故障是不可避免的。设计良好的检查点保存和恢复机制,以及优雅的故障处理流程,可以最大限度地减少故障带来的影响。
性能调优的实践智慧
性能调优是一个需要理论指导和实践经验相结合的过程。在实际工作中,我们发现一些关键的调优原则特别重要。首先是要建立可靠的性能度量基准。这包括训练速度、GPU利用率、内存使用情况等多个指标。只有有了这些基准数据,才能客观评估优化的效果。
系统配置的优化同样重要。CUDA和通信库的配置直接影响着系统性能。例如,启用CUDA graph可以减少启动开销,而正确的NCCL配置则能显著提升多GPU通信效率。这些配置需要根据具体的硬件环境和工作负载特点来调整。
# 设置CUDA环境 os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3' torch.backends.cudnn.benchmark = True torch.backends.cudnn.deterministic = False
进程间通信配置
# NCCL配置 os.environ['NCCL_DEBUG'] = 'INFO' os.environ['NCCL_SOCKET_IFNAME'] = 'eth0' os.environ['NCCL_IB_DISABLE'] = '0'
训练超参数的选择也需要特别注意。在分布式环境下,批次大小的选择不仅要考虑内存限制,还要考虑通信开销和优化效果。学习率的调整更需要考虑分布式训练的特点,通常需要随着有效批次大小的变化进行相应的缩放。
总结
分布式机器学习系统仍在快速发展。随着新型硬件的出现和算法的进步,我们预期会看到更多创新的优化技术。自适应训练策略将变得越来越重要,系统能够根据训练状态和资源利用情况动态调整参数。跨数据中心的训练也将成为新的研究热点,这将带来新的通信优化和同步策略的需求。
展望未来,分布式训练系统的发展方向将更加注重可扩展性和易用性的平衡。自动化的性能优化和故障处理机制将变得越来越普遍,使得研究人员能够更专注于模型设计和算法创新。这个领域还有很多待解决的问题,但也正是这些挑战让分布式机器学习系统的研究充满活力和机遇。
转载请注明:可思数据 » 分布式机器学习系统:设计原理、优化策略与实践经验
免责声明:本站来源的信息均由网友自主投稿和发布、编辑整理上传,或转载于第三方平台,对此类作品本站仅提供交流平台,不为其版权负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本站联系,我们将及时更正、删除,谢谢。联系邮箱:elon368@sina.com


