
 |
一、重新定义端到端:不止是 “传感器到控制”,更是架构范式的革新
Li Hongyang 在演讲中首先明确了端到端自动驾驶的核心定义:“学习单一模型,直接将原始传感器输入(图像、点云、车辆状态等)映射到驾驶控制指令(转向、刹车、油门)”,其本质是用 “统一函数” 取代传统自动驾驶的 “感知 - 定位 - 预测 - 规划 - 控制” 模块化流水线。这种架构革新的关键价值在于两点:
- 简化链路,降低延迟:省去模块间数据转换的中间环节(如感知结果向规划模块的语义对齐),端到端模型可直接输出控制指令,理论响应速度比模块化架构快 30%-50%,这对高速、突发场景的安全至关重要;
- 适配数据驱动逻辑:训练依赖 “输入 - 输出” 的直接映射,无需手动编写复杂规则(如 “无保护左转时的让行优先级”),只需通过海量标注数据让模型自主学习驾驶逻辑 —— 训练方式可灵活采用监督学习(SL)、模仿学习(IL)或强化学习(RL),核心是 “数据决定模型能力边界”。
二、端到端的 “前世今生”:从黑白图像到 1.5 代双分支的演进之路
Li Hongyang 将端到端自动驾驶的发展划分为三个关键阶段,每个阶段的技术突破都围绕 “解决前一阶段的核心痛点” 展开:
1. 早期探索阶段(2000s-2010s):从 “能跑” 到 “基本可用”
- 技术特征:以单一传感器输入(如黑白图像、简单激光雷达数据)为主,模型目标是实现 “结构化道路的基础跟车、车道保持”;
- 代表方法:条件模仿学习(Conditional Imitation Learning)通过专家驾驶数据,让模型学习 “给定导航指令(如‘左转’)时的控制输出”;泛化性优化工作则尝试解决 “不同光照、简单天气” 下的适配问题;
- 局限:场景覆盖极窄(仅能应对高速、无复杂交互的路况),对行人、突发障碍物的处理能力几乎为零,本质是 “实验室原型”,无法落地。
2. 模块化端到端阶段(2020s 初):嵌入显式功能,提升鲁棒性
- 技术特征:在端到端模型内部嵌入显式功能模块(如地图匹配、运动规划子网络),同时引入多模态传感器融合(相机 + 激光雷达);
- 代表方法:Andrew Gigard 团队提出的 “可解释性网络”,通过多模态输入(图像 + 点云)让模型输出 “目标检测框 + 轨迹预测结果”,再映射到控制指令;PPJL、Soft ACT 等工作则通过预训练技术,提升模型对 “陌生路段” 的适配能力;
- 突破与不足:首次具备 “城区简单道路” 的通行能力,但仍受限于 “已知场景”,对 “极端天气、长尾事件(如施工区临时改道)” 的处理能力薄弱 —— 核心问题是 “真实路测数据无法覆盖所有风险场景”。

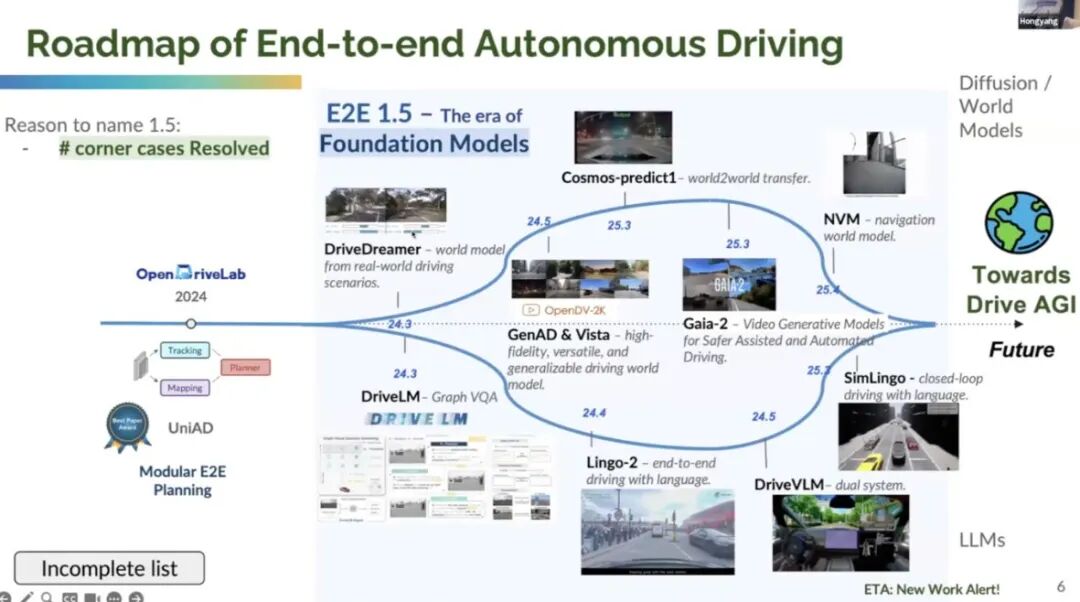
3. 1.5 代端到端阶段(2023-2025):基础模型驱动,分化双分支
这是当前行业所处的关键阶段,核心标志是 “基础模型(Foundation Models)融入端到端架构”,通过大模型的泛化能力解决长尾问题,同时分化出两条技术路径:| 分支类型 | 核心技术逻辑 | 代表方案与能力特点 | 优势与局限 |
|---|---|---|---|
| WM 世界模型分支 | 构建 “环境动态模拟器”,通过多模态输入预测未来场景,再生成控制指令 | - Drive Dreamer:用扩散模型生成多视图未来视频,预测车辆、行人运动轨迹;- Cosmos Predict One:结合高精地图,模拟 “极端天气(暴雨、大雾)下的场景演变”;- Gaia 2:视频生成模型,重点优化 “危险场景(如前车急刹、行人横穿)的多样性生成” | 优势:可主动生成罕见场景数据,弥补真实路测不足;局限:仿真与现实的 “域差” 难以完全消除,生成场景的物理真实性(如路面摩擦系数、车辆动力学)可能与实际偏差 |
| VLA 分支 | 以 “语言” 为中间桥梁,连接视觉感知与动作输出,通过语言推理优化决策逻辑 | - Java LM:提出 “草图维基”,用文本描述驾驶场景(如 “前方 50 米有施工,需借道超车”),再转化为控制指令;- Lingo Tool:通过语言思维链(Chain of Thought)分解复杂决策(如 “无保护左转→观察对向直行车→判断行人意图→调整车速”);- Job VRM:双模型协同(小模型处理常规场景,大语言模型处理复杂交互),平衡延迟与精度 | 优势:决策可解释性强(语言推理过程可追溯),人机交互更自然;局限:语言符号化过程可能导致精度损耗,大模型推理延迟较高(部分方案延迟超 100ms,不满足高速场景需求) |
Li Hongyang 强调,1.5 代的本质是 “用基础模型的能力补全端到端的短板”——WM 试图解决 “数据稀缺”,VLA 试图解决 “决策不可解释”,但两者都未脱离 “数据驱动” 的核心,也都面临 “如何走向大规模工程落地” 的共同挑战。
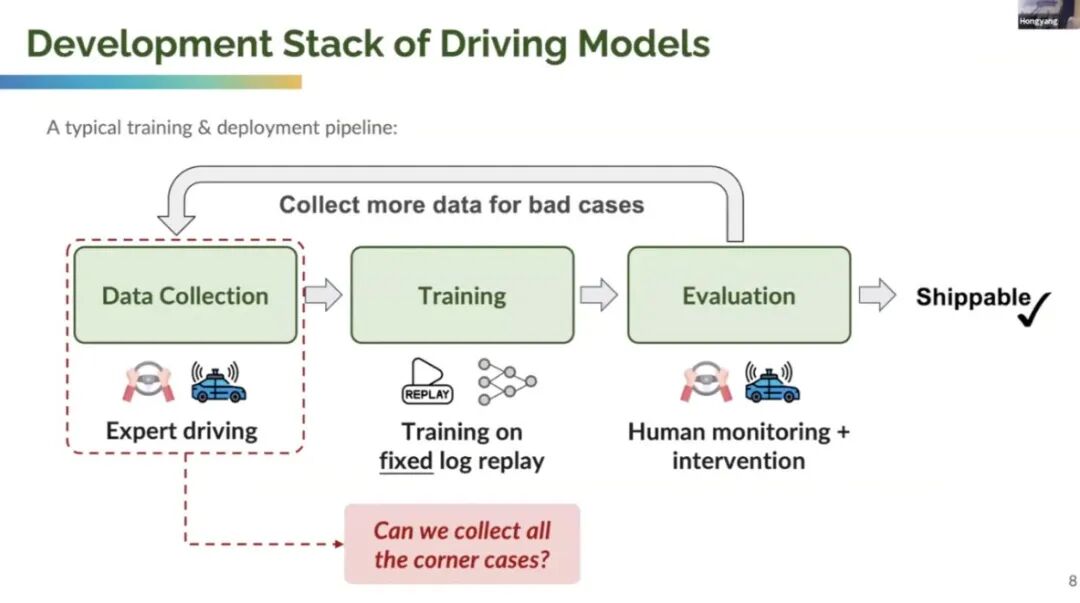
三、L4 落地的核心瓶颈:长尾问题与 “数据收集悖论”
尽管特斯拉 FSD 的 “每次接管跑的公里数(MPI)” 逐年提升(北美数据显示,2025 年 FSD 的 MPI 已突破 1500 公里),但 Li Hongyang 通过一组关键数据揭示了行业的核心困境 ——“数据收集悖论”:如上图所示,X 轴代表 “驾驶场景类型”,从左到右依次为 “常规场景”“边缘场景”“安全关键场景(濒临事故)”;Y 轴包含两条曲线:
- 黑色曲线(危险概率):随着驾驶里程累积,常规场景的感知、决策问题已基本解决,剩余 20% 的长尾场景(如 “暴雨天施工区 + 行人横穿 + 定位信号丢失”)发生概率极低,但一旦发生就是高风险事故;
- 红色曲线(部署成本):要收集这些 “十年一遇” 的安全关键场景,需要投入庞大的车队规模(特斯拉北美车队超 200 万辆),且每增加 1% 的场景覆盖率,成本会呈指数级上升 —— 更严峻的是,“收集危险场景” 本身可能伴随安全风险(如为了采集 “前车急刹” 数据,需让测试车接近危险状态)。
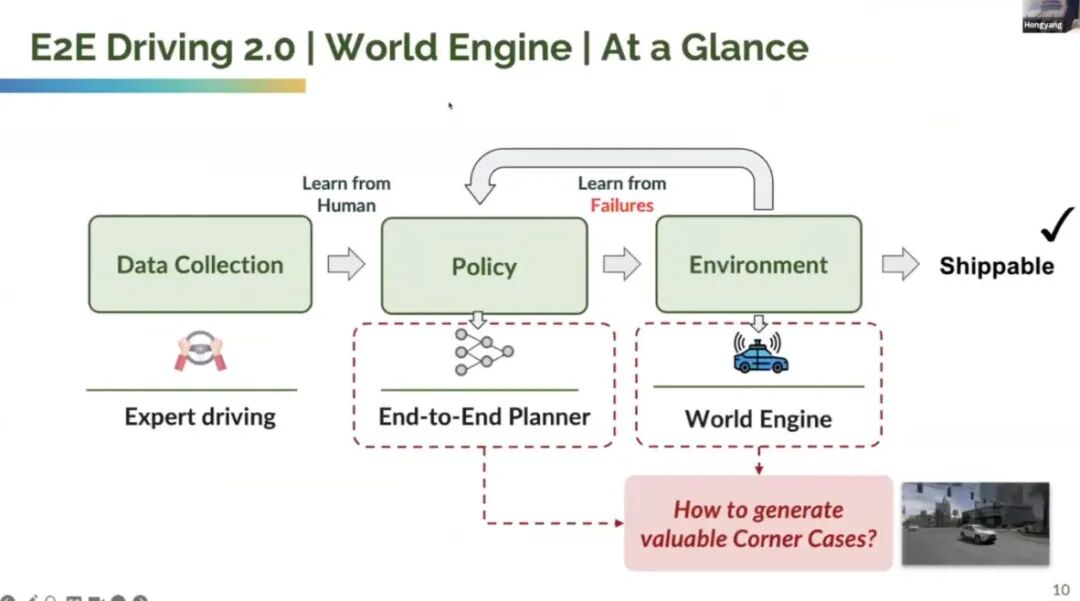
四、世界引擎:端到端自动驾驶的 “终极数据与算法闭环”
Li Hongyang 提出的 “世界引擎”,本质是一套 “主动生成高价值数据、优化端到端模型” 的全链路系统,核心由 “数据引擎(Data Engine)” 与 “算法引擎(Algorithm Engine)” 两部分构成,共同解决 “长尾场景数据稀缺” 与 “模型迭代效率低” 的问题: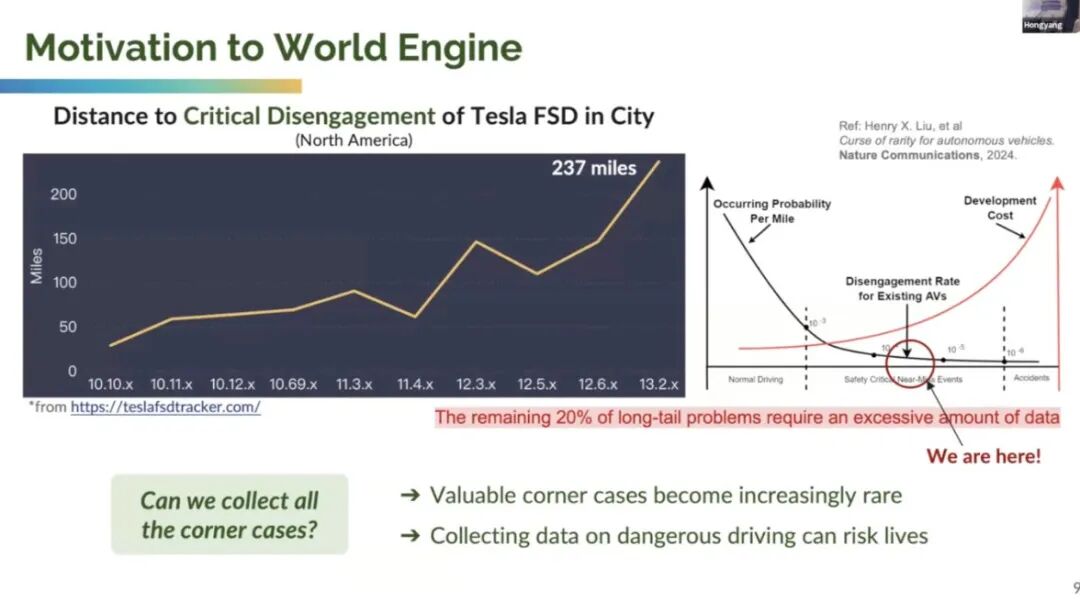
1. 数据引擎:主动生成安全关键场景,替代 “被动路测收集”
数据引擎的核心逻辑是 “从已有专家驾驶数据中提取特征,生成海量相似但更极端的场景”,具体分为三步:- 源场景挖掘:从真实路测日志中筛选 “潜在风险场景”(如 “行人靠近车道边缘”“前车刹车灯亮起”),作为生成的 “种子数据”;
- 极端场景生成:通过扩散模型、物理仿真引擎,对种子场景进行 “风险放大”—— 例如将 “晴天行人横穿” 扩展为 “暴雨天 + 逆光 + 行人突然冲出”,将 “单一车辆加塞” 扩展为 “多车连续加塞 + 非机动车干扰”;
- 传感器级渲染:将生成的场景转化为 “传感器可感知的原始数据”(如相机图像、激光雷达点云、毫米波雷达信号),确保数据格式与真实采集一致,可直接用于模型训练。
2. 算法引擎:闭环优化端到端模型,提升泛化能力
算法引擎是 “世界引擎” 的 “大脑”,负责将数据引擎生成的场景转化为模型能力的提升,核心是 “闭环迭代”:- 模型测试与弱点定位:将生成的极端场景输入端到端模型,记录模型的误判情况(如 “漏检施工标志”“决策延迟”),定位算法薄弱环节;
- 针对性训练:用高价值场景数据对模型进行微调,重点优化弱点(如针对 “暴雨天感知” 补充训练);
- 真实场景验证:将优化后的模型部署到少量测试车,收集真实路测反馈,若发现新的误判,再回流到数据引擎生成对应场景 —— 形成 “生成 - 训练 - 验证 - 再生成” 的闭环。
五、VLA 与 WM 的博弈:路径差异下的共同目标
演讲最后,Li Hongyang 针对当前行业 “VLA 与 WM 孰优孰劣” 的争论给出了明确观点,结合行业实践可总结为三点:- WM 是 “终极目标”,但当前仍处 “概念大于落地”:WM 的核心价值是 “完全模拟现实世界”,理论上可覆盖所有场景,但受限于物理仿真精度(如车辆动力学、行人行为随机性),目前生成的场景仍存在 “失真” 问题 —— 国内部分企业提及的 “WM 世界模型”,更多是 “基于高精地图的场景回放”,而非真正的 “动态模拟器”,存在一定的概念夸大。
- VLA 是 “现阶段更务实的路径”:VLA 通过语言推理提升决策可解释性,不仅符合监管对 “自动驾驶决策可追溯” 的要求,也能通过 “小模型 + 大语言模型” 的协同(小模型处理常规场景降延迟,大模型处理复杂交互保精度),快速落地到 L2+、L3 级产品 —— 例如华为 ADS 4.0 的 “自然语言交互决策”,本质就是 VLA 思路的工程化应用,已实现城区复杂道路的稳定通行。
- 两者最终都需依赖世界引擎:无论 VLA 还是 WM,都无法回避 “长尾场景数据稀缺” 的问题 ——VLA 需要世界引擎生成 “复杂语言描述的危险场景”(如 “前方施工,同时有非机动车逆行”),WM 需要世界引擎优化 “仿真场景的真实性”,甚至可以说,“世界引擎是 1.5 代双分支走向第二代端到端(工程化落地阶段)的必经之路”。
六、结语:从 “技术路线之争” 到 “落地能力比拼”
Li Hongyang 的演讲本质上传递了一个核心观点:端到端自动驾驶的竞争,已从 “选 VLA 还是选 WM” 的路线之争,转向 “谁能更快解决工程落地问题” 的能力比拼。1.5 代的双分支是行业探索的必然产物,WM 代表了 “对终极场景覆盖的追求”,VLA 代表了 “对现阶段可解释性与落地效率的平衡”,两者没有绝对的优劣,只有 “适配不同产品目标” 的差异。但无论选择哪条路径,都绕不开 “世界引擎” 的支撑 —— 因为只有通过主动生成高价值数据、构建 “数据 - 模型 - 验证” 的闭环,才能突破 L4 落地的 “数据收集悖论”。
对行业而言,与其纠结 “WM 和 VLA 谁更先进”,不如聚焦 “世界引擎的仿真精度如何提升”“VLA 的推理延迟如何降低”“WM 的域差如何缩小” 等具体工程问题。毕竟,自动驾驶的终极目标不是 “技术名词的胜利”,而是 “安全、可靠地服务于真实道路”—— 这也是世界引擎被寄予厚望的核心原因。
转载请注明:可思数据 » 端到端自动驾驶的演进与核心博弈:从 1.5 代双分支到世界引擎的必然之路
免责声明:本站来源的信息均由网友自主投稿和发布、编辑整理上传,或转载于第三方平台,对此类作品本站仅提供交流平台,不为其版权负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本站联系,我们将及时更正、删除,谢谢。联系邮箱:elon368@sina.com


