
 |
一、有监督学习(Supervised Learning)
1.定义
有监督学习是指使用带有标签(或目标值)的数据集来训练模型,让模型学习输入特征与输出标签之间的映射关系。在学习过程中,模型会不断调整其参数,以最小化预测标签与实际标签之间的差异。
2.特点
数据集包含输入特征和对应的标签。
模型通过学习已知的输入输出关系来预测新的数据。
预测结果可以与实际标签进行比较,以评估模型的准确性。
3.应用场景
分类任务:如垃圾邮件分类、图像识别、情感分析等。
回归任务:如房价预测、股票价格预测、天气预报等。
时间序列预测:如销售预测、股票价格趋势预测等。
4.常见算法:
线性回归
逻辑回归
支持向量机(SVM)
决策树
随机森林
神经网络
二、无监督学习(Unsupervised Learning)
1.定义
无监督学习是指使用没有标签的数据集进行训练,模型需要自行发现数据中的内在结构、模式或规律。无监督学习的目标通常不是预测或分类,而是数据的降维、聚类或关联规则的发现。
2.特点
数据集仅包含输入特征,没有对应的标签。
模型需要自行发现数据中的模式和结构。
评估模型的方法通常不是通过预测准确性,而是通过聚类效果、数据降维的质量或关联规则的实用性等。
3.应用场景
聚类分析:如客户细分、市场分析、图像分割等。
数据降维:如主成分分析(PCA)、自编码器等,用于简化数据集、提高模型训练效率。
异常检测:识别出数据中的异常点或异常行为。
4.常见算法
K-means聚类
层次聚类
主成分分析(PCA)
自编码器
密度估计
异常检测算法
三、有监督学习与无监督学习的区别
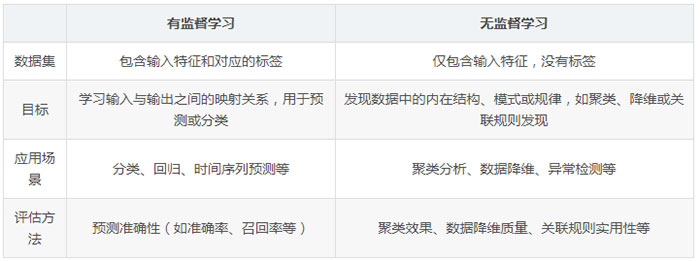
总之,有监督学习和无监督学习在机器学习领域各有其独特的应用场景和优势。选择合适的学习方法取决于具体问题的需求和数据的特点。
免责声明:本站来源的信息均由网友自主投稿和发布、编辑整理上传,或转载于第三方平台,对此类作品本站仅提供交流平台,不为其版权负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本站联系,我们将及时更正、删除,谢谢。联系邮箱:elon368@sina.com


