
 |
随着大数据时代的到来,数据量呈指数级增长,企业需要高效的存储和管理海量数据的方法。数据湖和数据仓库是两种常见的数据存储和管理解决方案,它们在存储架构、数据处理方式和应用场景上有着显著的区别。本文将深入探讨数据湖与数据仓库的区别与应用,帮助企业选择合适的数据存储解决方案。
提出问题
什么是数据湖和数据仓库?
数据湖和数据仓库有哪些区别?
如何选择合适的数据存储解决方案?
数据湖和数据仓库在实际应用中的案例有哪些?
解决方案
什么是数据湖和数据仓库?
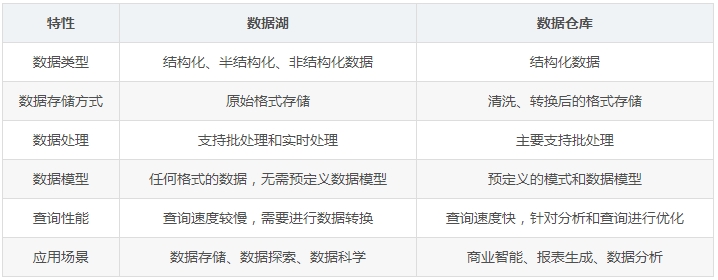
数据湖
数据湖是一个集中式存储库,可以存储大量的结构化和非结构化数据。它允许以任何格式存储数据,包括文本、图像、视频、音频等,数据可以以原始格式进行存储,无需进行预处理。
特点:
灵活性:支持多种数据格式和数据源。
高扩展性:能够存储海量数据,适用于大规模数据处理。
低成本:存储成本相对较低,适合长期存储大量数据。
数据仓库
数据仓库是一个专门设计用于数据分析和报告的数据库系统,通常用于存储和管理结构化数据。数据仓库通过ETL(提取、转换、加载)过程将数据从多个源系统中抽取、清洗和转换,统一存储在中央存储库中。
特点:
高性能:专为数据查询和分析优化,支持复杂的查询和报表生成。
数据一致性:通过数据清洗和转换,确保数据的一致性和准确性。
集成性:能够集成来自多个数据源的数据,提供统一的数据视图。
数据湖和数据仓库的区别
选择合适的数据存储解决方案
数据湖的应用场景
数据存储:适合存储大量的原始数据,支持数据探索和数据科学应用。
数据整合:能够整合来自不同数据源的数据,包括结构化和非结构化数据。
大数据处理:适用于大规模数据处理和分析,如机器学习和深度学习应用。
数据仓库的应用场景
商业智能:适合用于商业智能和报表生成,支持复杂的查询和数据分析。
数据集成:能够集成来自多个数据源的数据,提供一致的数据视图。
历史数据分析:适用于存储和分析历史数据,支持长期趋势分析和报表生成。
数据湖和数据仓库在实际应用中的案例
案例一:数据湖在电商中的应用
问题:电商企业需要存储和处理大量的用户行为数据,包括点击流数据、搜索记录、购物车数据等,以进行用户行为分析和推荐系统的开发。
解决方案:使用数据湖存储海量的用户行为数据,通过Spark和Hadoop等大数据处理工具,对数据进行批处理和实时处理,支持用户行为分析和推荐系统的开发。
实际操作:
数据存储
将用户行为数据以原始格式存储在数据湖中,支持多种数据格式和数据源。
aws s3 cp user_behavior_data.json s3://your-data-lake-bucket/
数据处理
使用Spark进行数据处理和分析。
from pyspark.sql import SparkSession
# 初始化SparkSession
spark = SparkSession.builder.appName("Ecommerce User Behavior Analysis").getOrCreate()
# 读取数据
data = spark.read.json("s3://your-data-lake-bucket/user_behavior_data.json")
# 数据处理
result = data.groupBy("user_id").agg({"clicks": "sum", "purchases": "sum"})
# 显示结果
result.show()
案例二:数据仓库在金融行业中的应用
问题:金融企业需要存储和分析大量的交易数据和客户数据,以支持风险管理和客户关系管理。
解决方案:使用数据仓库存储和管理结构化的交易数据和客户数据,通过ETL过程进行数据清洗和转换,确保数据的一致性和准确性,支持风险管理和客户关系管理的应用。
实际操作:
数据存储
将交易数据和客户数据存储在数据仓库中,支持高效的数据查询和分析。
-- 创建表
CREATE TABLE transactions (
transaction_id INT,
customer_id INT,
amount DECIMAL(10, 2),
date DATE
);
-- 加载数据
COPY transactions FROM 's3://your-data-warehouse-bucket/transactions.csv'
CREDENTIALS 'aws_access_key_id=YOUR_ACCESS_KEY;aws_secret_access_key=YOUR_SECRET_KEY'
CSV;
数据分析
使用SQL进行数据查询和分析。
-- 查询高风险交易
SELECT customer_id, SUM(amount) AS total_amount
FROM transactions
WHERE amount > 10000
GROUP BY customer_id
HAVING SUM(amount) > 50000;
最佳实践
数据治理:无论是数据湖还是数据仓库,数据治理都是关键,确保数据的一致性、准确性和安全性。
架构设计:根据业务需求和数据特性,合理设计数据架构,选择合适的数据存储解决方案。
性能优化:通过合理的资源配置和优化策略,提升数据处理和分析的性能。
自动化运维:采用自动化运维工具,进行系统监控和管理,提高系统的稳定性和可靠性。
持续集成和部署:采用持续集成和部署(CI/CD)流程,提高系统的开发和部署效率,确保系统的快速迭代和发布。
结论
数据湖和数据仓库作为两种常见的数据存储和管理解决方案,各有优劣。数据湖适用于存储和处理多种格式的海量数据,支持大数据处理和数据科学应用;数据仓库则适用于存储和分析结构化数据,支持商业智能和报表生成。企业应根据具体的业务需求和数据特性,选择合适的数据存储解决方案,构建高效的数据处理和分析系统。
转载请注明:可思数据 » 数据湖与数据仓库的区别与应用
免责声明:本站来源的信息均由网友自主投稿和发布、编辑整理上传,或转载于第三方平台,对此类作品本站仅提供交流平台,不为其版权负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本站联系,我们将及时更正、删除,谢谢。联系邮箱:elon368@sina.com


