
 |

近日,百度联合复旦大学等发布 Hallo2,一个可以生成长达数小时且分辨率为 4K 的人物动画的视觉模型。Hallo2 目前已经在 GitHub 平台开源,供全球开发者免费使用和研究,预计将促进视频生成技术的广泛应用和发展。(项目地址:https://fudan-generative-vision.github.io/hallo2/#/)
Hallo2 发布后,在海外引发了不小的震动。有人惊叹视频生成的长度和分辨率,也有老用户从 Hallo 第一代模型就被圈粉,还有对 Hallo2 开源模型和代码的认可。
Hallo2 备受关注,很重要一个原因是百度和复旦的研究团队解决了人像视频生成一个很大的痛点:如何提升视频生成的时长和质量。
一直以来,生成高质量的人物动画需要耗费大量的时间和人力成本。而百度与复旦联合发布的 Hallo2 的出现,有望彻底改变这一现状,为数字人、电影制作、虚拟助手、游戏开发等领域带来革命性的变化。
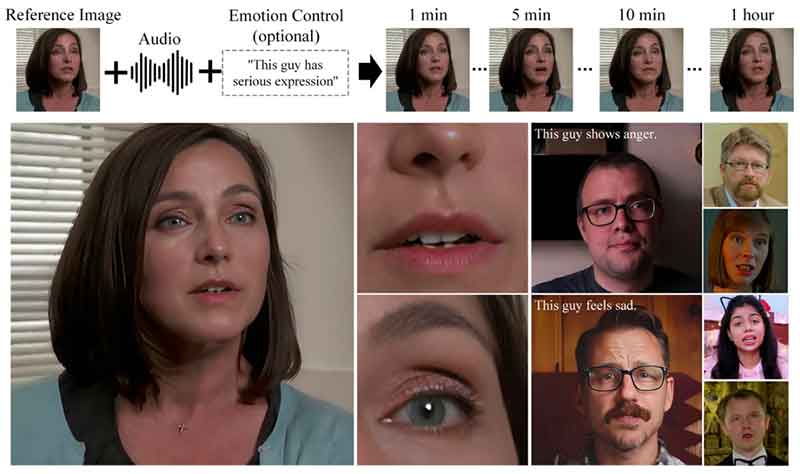
Hallo2 是能够实现长达一小时、4K 分辨率的音频驱动人像动画生成模型。通过创新的图像块丢弃、噪声增强和时间对齐等技术,Hallo2 解决了长时视频生成中的外观漂移和视觉不一致问题,支持灵活的语音与文本控制,生成质量达到业内领先水平。
Hallo2 继承了前代 Hallo 模型的创新框架,继续采用基于扩散的生成模型和分层音频驱动视觉合成模块,提高了音频与视觉输出之间的同步精度,并经过改进使得各部分的协同作用更加高效,增强了生成动画的质量和真实感。此外,Hallo2 不仅在图像和视频的质量方面有了显著提升,而且大幅增加了动作的丰富性和多样性。
有行业专家表示,Hallo2 的出现,标志着音频驱动的肖像图像动画技术迈入了新的发展阶段。百度基于长期的视觉技术积累,正在瞄准行业痛点进行针对性研究和场景落地,不仅为开发者提供了强大的工具,也为未来各种应用场景下的动画形象创作带来了新的可能性。
转载请注明:可思数据 » 百度又放大招!视觉生成模型 Hallo2 或将落地数字人等场景
免责声明:本站来源的信息均由网友自主投稿和发布、编辑整理上传,或转载于第三方平台,对此类作品本站仅提供交流平台,不为其版权负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本站联系,我们将及时更正、删除,谢谢。联系邮箱:elon368@sina.com


