
 |
机器人智体的任务是掌握常识并根据自然语言指令做出长期连续的决策来执行日常任务。大语言模型 (LLM) 的最新进展催化了复杂机器人规划的努力。然而,尽管 LLM 具有出色的泛化和理解能力,但其任务规划有时会存在准确性和可行性的问题。RoboGPT,是一个专门设计用于为指令跟踪任务做出具体长期决策的智体。RoboGPT 集成了三个关键模块:1)Robo-Planner 是一个基于 LLM 的规划模块,配备 67K 具身规划数据,将任务分解为逻辑子目标。用基于模板反馈的自指导方法编译了一个新的机器人数据集来微调 Llama 模型。具有强大泛化的 RoboPlanner 可以规划数百个指令跟随任务;2)RoboSkill,针对每个子目标进行定制,以提高导航和操作能力; 3)Re-Plan 模块可根据实时环境反馈,动态调整子目标。利用 RoboSkill 生成的精确语义图,通过计算子目标与环境中存在的物体之间相似性来替换目标物体。实验结果表明,RoboGPT 在数百个未见过的日常任务甚至来自其他领域任务的规划合理性方面超越了其他最先进 (SOTA) 方法,尤其是基于 LLM 的方法。
具身智能任务(包括视觉导航和机器人操控)进展迅速 [1]–[3]。预计未来的机器人将通过遵循自然语言指令(例如“做晚餐”或“洗碗”)来帮助人类执行复杂的日常任务 [1]、[4]。现有方法(包括模板规划 [5]、[6] 和专家指导规划 [7]、[8])在处理七种类型的指令跟随任务方面取得了一些成功。然而,当前的智体无法完全理解指令任务,包括目标数量、前缀内容和目标依赖性等方面。
大语言模型 (LLM) 在自然语言处理领域取得了重大进展 [9]。由于其广泛的内部化世界信息,LLM 可以比基于模板的方法 [5] 更通用地解决复杂的具身规划问题 [10]。然而,通用 LLM 过于宽泛,缺乏机器人专业知识,导致规划通常无法由机器人直接实施 [10]–[12]。例如,给定任务“如果你是一个机器人,给我一个切苹果的规划”,生成的规划是“收集材料”、“洗手”、“准备苹果”、“……”,这对于机器人来说是无法执行的。即使是带有指定提示的 LLM-Planner [10] 也会产生一些不合逻辑的复杂日常任务规划。
为了解决 LLM 规划的准确性问题,本文旨在通过整合机器人领域的专业知识来增强 LLM 的规划能力。目标是微调和增强 LLM 规划过程,以确保逻辑有效性和最佳执行。为了克服缺乏特定领域数据的问题,创建一个专门的机器人数据集,其中包含 67K 个涵盖复杂机器人活动的具体命令。数据收集和微调是此增强过程中的关键步骤。本文采用自动化方法,利用自指导方法使 ChatGPT 能够生成一批数据。然而,超过 60% 的生成数据存在问题,主要是规划中的逻辑关系不正确。为了解决这个问题,引入一种模板反馈机制,提示 ChatGPT 自省并纠正生成的数据。该模型首先识别数据类型,然后输入该类型的相关考虑因素。这个过程引导 ChatGPT 自主纠正错误的规划,大大减少与手动数据更正相关的工作量。与 LLM-Planner 不同,RoboGPT 在上述数据上进行训练:1)可以理解前缀内容,以根据环境修改规划子目标;2)可以理解目标依赖关系以找到容器中不可见的目标,例如,“将微波炉中的苹果放入垃圾桶”,RoboGPT 规划“先找到微波炉”,而当前的方法直接找到苹果,但无法始终找到它们;3)可以理解物体数量,从而比其他方法更能处理两个以上物体的任务。
模板反馈机制的实施不仅保证了高质量数据的生成,而且促进了逻辑思维链的形成,大大提高了生成数据的准确性。经过微调的RoboPlanner在此精炼数据集上训练,表现出强大的泛化能力,并优于其他规划方法。最终,使用此数据集微调的LLM,在具体指令跟随任务中表现出更高的性能。这是一种将数据收集和细化方法与模板反馈机制的应用相结合的创新。
在遵循指令执行任务的过程中,解决可行性问题的关键,是让智体能够感知和考虑环境。将指令目标映射到环境中的目标仍然是一个挑战,即指令命名多样性挑战。例如,任务是“把一支铅笔和一本书放在桌子上”,而环境中常见的桌子类型是“边桌”、“餐桌”和“书桌”。先前的方法 [5]、[6] 通常根据经验预测桌子类型为“边桌”,并计划“寻找边桌”。然而,当环境中没有“边桌”时,智体无法找到合适的桌子,导致任务失败。为了解决这个问题,引入环境反馈和重规划,以使环境目标与指令任务保持一致。
如图所示,RoboGPT 系统用于日常指令执行任务,该系统由 RoboPlanner、RoboSkill 和 Re-Plan 组成。给出指令后,RoboPlanner 将其分解为逻辑子目标。RoboSkill 根据子目标执行导航或操作技能,产生与环境交互的动作,并按顺序完成所有子目标。如果某个子目标仍未完成,Re-Plan 会收集反馈并使用环境信息创建新规划。
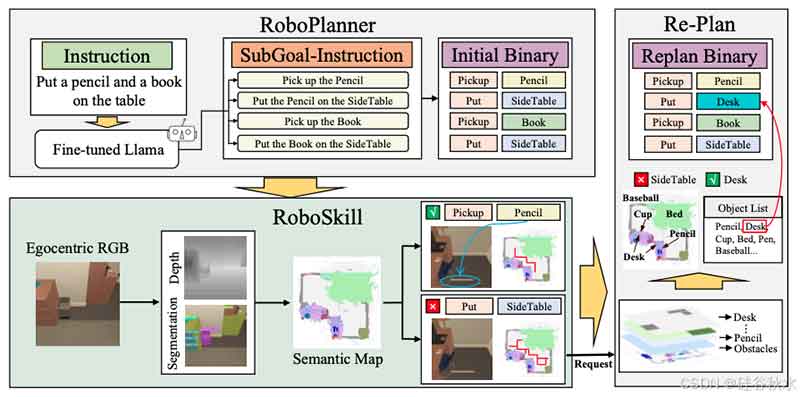
本文构建一个 67K 高质量的具身规划数据集,并基于模板生成自指导数据。该数据集用于训练基于 Llama [9] 的规划模型,该模型能够处理具有长期决策的日常任务。数据集生成和模型训练的过程如图所示。
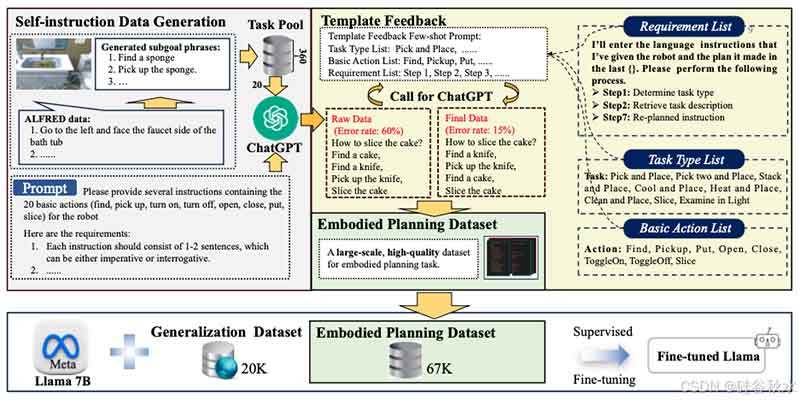
用于规划具有长期决策的日常任务的机器人的公开数据有限。最相关的 ALFRED 任务 [15] 仅包含 8K 专家轨迹,涵盖七种任务类型,多样性不足。因此,这里的感知不仅从 ALFRED 任务中获取 60K 个各种类型的样本,而且还采用自我指导生成具有更广泛任务描述和类型的 7K 个样本。
数据生成过程包括三步:1)自我指令数据生成;2)模版反馈;3)人工验证。
为了增强具身指令规划能力,在 Llama [9] 上采用监督微调。除了 67K 具身规划数据集外,还用从互联网获得的 20K 泛化数据集扩充机器人的训练集,并且只训练两个episodes,使 RoboPlanner 能够学习机器人的规划能力并保持强大的泛化能力。
RoboSkill 根据收到的指令完成导航或操作技能。参考 Prompter [5],在每个时间步骤,感知模块接收以自我为中心的 RGB 图像,检测目标分割和深度,并更新相应区域的语义图。语义图引导导航模块寻找目标。一旦找到目标,交互模块就会产生与环境交互的动作,直到完成所有子目标。
语义分割在各种应用中起着至关重要的作用,因为它能够为交互提供目标掩码并促进语义图的创建 [32]- [34]。语义图随后用于 Re-Plan 和目标导航等子目标。先前的工作中发现分割模块存在遗漏或错误识别,这对语义图的准确性有很大影响。因此,这导致 Re-Plan 和整体 SR 的性能下降。从 ALFRED [15] 可见环境中收集数据集,以利用 FastSAM [35] 主干训练语义分割模型。这显著提高目标检测和语义图的准确性。
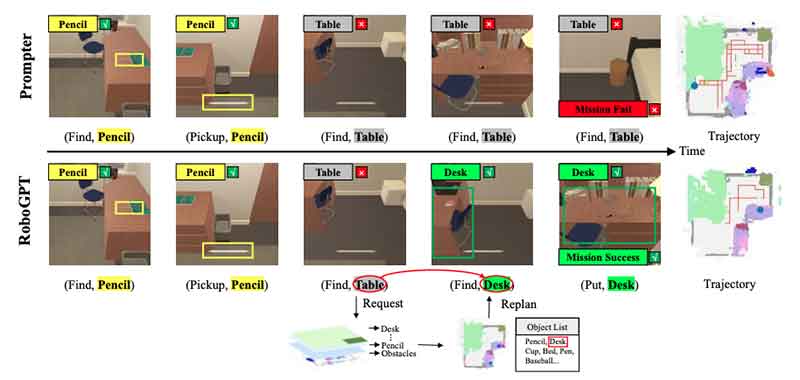
具身智能面临的主要挑战之一是命名多样性,即指令中提到的目标和环境中存在的目标可能具有不同的名称来指代同一目标。然而,现有方法 [5] 往往忽略了这一特定问题。它们主要关注执行前的任务规划,而没有完全理解当前环境。当子目标中指定的目标与环境中存在的目标不匹配时,智体将无休止地探索,直到超过最大步数。
如图所示重新规划的例子:Table - Desk 的匹配
RoboPlanner 是在 NVIDIA DGX A100 上从 Llama- 7b 微调而来的。训练数据包括 67K 具身规划数据集和 20K 在线泛化数据集。为了保持泛化能力,网络以 10-5 的学习率分 2 个episodes进行训练。RoboSkill 利用 FastSAM 主干 [35] 在收集的 80K 幅图像上训练语义分割模型,历时 100 个 epochs,学习率为 10-3,批量大小为 16。
转载请注明:可思数据 » RoboGPT:用于执行指令跟随任务的基于 LLM 具身长期决策智体
免责声明:本站来源的信息均由网友自主投稿和发布、编辑整理上传,或转载于第三方平台,对此类作品本站仅提供交流平台,不为其版权负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本站联系,我们将及时更正、删除,谢谢。联系邮箱:elon368@sina.com


