

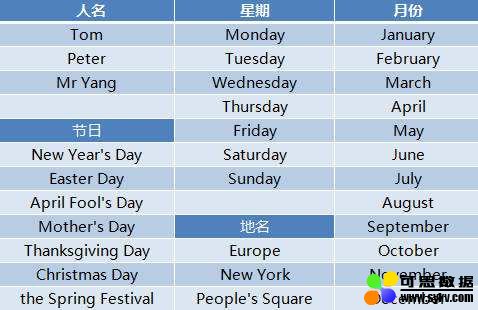
描述 属于101类别的对象的图片。每类约40至800张图片。大多数类别有大约50张图片。2003年9月,李菲飞,马克安德烈托和MarcAurelio Ranzato收集。每幅图像的大小约为300 x 200像素。 我们仔细...

NORB 是 3D 物体图像识别数据集。此数据库用于从形状进行3D对象重新定位的实验从不同的角度对 5 大类别(四条腿的动物、人像、飞机、卡车、小汽车)中的 50 个玩具模型进行图像拍摄...

PubFig:公众人物面对数据库 介绍 PubFig数据库是一个大型的真实世界的人脸数据集,由从互联网上收集的200人的58797张图像组成。与大多数其他现有面部数据集不同,这些图像是在非合...
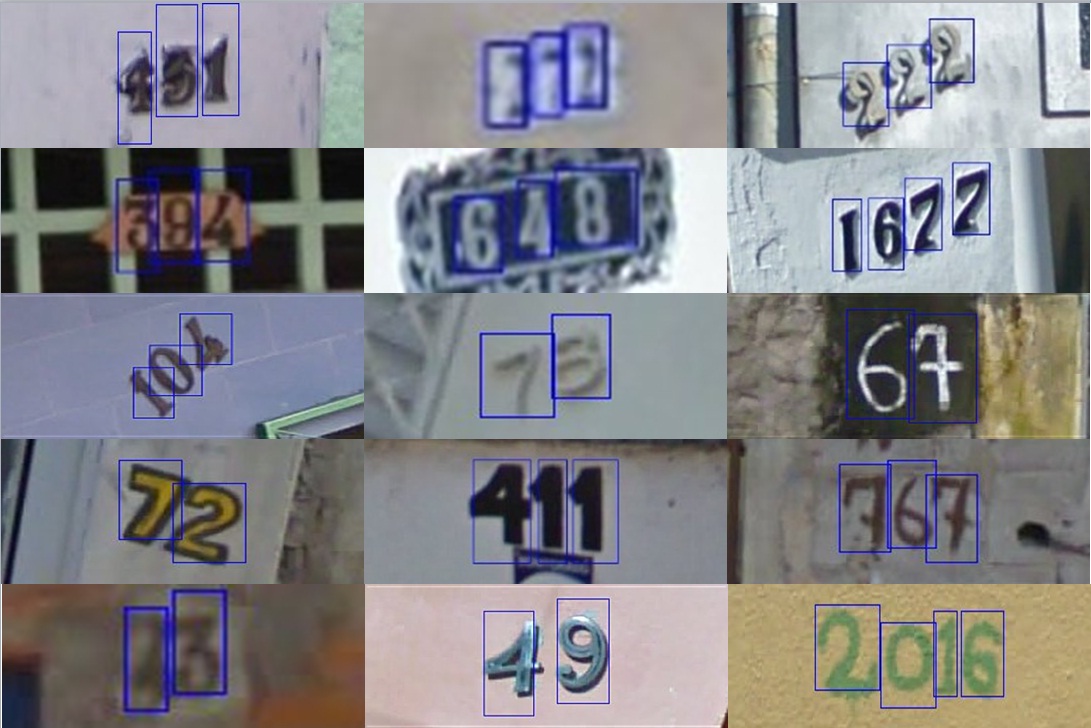
街景号码(SVHN)数据集 SVHN是一个真实的图像数据集,用于开发机器学习和对象识别算法,对数据预处理和格式化的要求最低。它可以被看作与MNIST的风味相似(例如,图像是小的裁剪...

Visual Genome是一个数据集,一个知识库,一个将结构化图像概念连接到语言的持续努力。VisualGenome数据集是Stanford大学维护的图像及图像内容语义信息的数据集,相比于著名的ImageNet 图像...
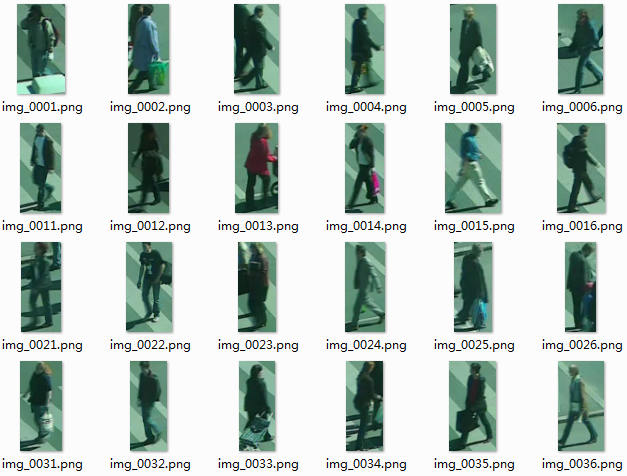
人体重识别数据集(行人再识别数据)该数据集是一个人身份再识别数据集,用以评价人身份再识别算法的效果。可思数据AI资源下载大本营,集课程资源人脸识别自动驾驶,智能安防...

室外标记的人脸面部(LFPW)数据集 Kriegman-Belhumeur Vision Technologies,LLC。 LFPW的第1版包含来自网络下载图像的1432张面孔,使用google.com,flickr.com和yahoo.com等网站上的简单文本查询。每个...

该数据集的目的是提供一种简单的方法来开始3D计算机视觉问题,如3D形状识别。 该数据集包含从MNIST数据集的原始图像生成的3D点云,以便为用于处理2D数据集(图像)的人员提供熟悉...

CrowdSegmentation Dataset 是一个高密度人群和移动物体视频数据,视频来自BBCMotionGallery和GettyImages网站。该数据集包含人群和其他高密度移动物体的视频。这些视频主要来自BBC Motion Gallery和...

加州理工学院行人检测基准 描述 加州理工学院行人数据集包括大约10小时的640x480 30Hz视频,这些视频来自在城市环境中通过常规交通的车辆。大约250,000个框架(137个近似分钟的长段)...

行动数据库 在我们在ICPR04中报告的实验中,将所有序列相对于受试者分成训练组(8人),验证组(8人)和测试组(9人)。在训练集上训练分类器,同时使用验证集来优化每种方法的参...

ALOV++,AmsterdamLibraryofOrdinaryVideosfortracking是一个物体追踪视频数据,旨在对不同的光线、通透度、泛着条件、背景杂乱程度、焦距下的相似物体的追踪。视频主要来自Youtube网站上的视频,...

使用身体姿势特征和多实例学习的双人交互检测 在第二届计算机视觉与模式识别会议上的3D数据人类活动理解国际研讨会上发表,CVPR 2012 Kiwon Yun,Jean Honorio,Debaleena Chattopadhyay,Tamara...

UCF运动行动数据集 UCF体育数据集包括从各种体育运动中收集的一系列动作,这些动作通常在广播电视频道(如BBC和ESPN)上播出。视频序列来自各种素材网站,包括BBC Motion gallery和Gett...
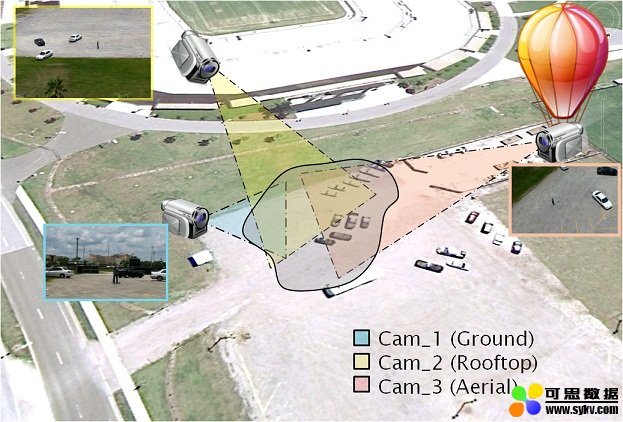
UCF-ARG 是一个多角度人类动作识别数据,从3个不同角度的摄像机,拍摄12位志愿者的人类动作视频。拍摄的人类动作有10类,包括:拳击,携带,鼓掌,挖掘,慢跑,开关门,跑步,投掷...

在高级人类交互识别挑战中,参赛者需要通过连续视频识别正在进行的人类活动。目的是激励研究人员在现实环境中从连续视频中探索复杂人类活动的识别。每个视频包含顺序和/或同时...
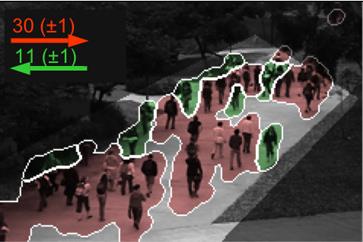
加州大学圣地亚哥分校的行人数据集 目前,人们对用于监控所有类型环境的视觉技术非常感兴趣。这可能有许多目标,例如安全性,资源管理或广告。然而,视觉技术的部署总是受到整...

僧伽罗语TTS 标识符:SLR30 摘要:僧伽罗语多音箱TTS语料库 类别:演讲 许可:署名 - ShareAlike 4.0国际(CC BY-SA 4.0) 关于此资源: 该数据集包含用于僧伽罗语的多扬声器高质量转录音频数...

THCHS-30 标识符:SLR18 摘要:CSLT @清华大学发布免费汉语语音语料库 类别:演讲 许可证:Apache License v.2.0 关于此资源: THCHS30是由清华大学语音与语言技术中心(CSLT)出版的开放式中文...
LibriSpeech ASR corpus 是一个语音数据,包括 1000小时 的英文发音和对应文字。 LibriSpeech ASR语料库 标识符:SLR12 摘要:大规模(1000小时)阅读英语演讲语料库 类别:演讲 许可证:CC BY 4.0...

收集撒哈拉以南非洲语言资源进行自动语音识别:Wolof案例研究。Elodie Gauthier,Laurent Besacier,Sylvie Voisin,Michael Melese和Uriel Pascal Elingui。出席LREC 2016 到目前为止,ASR目录包含4种语言的...

AMI语料库 AMI会议语料库是一种多模式数据集,包含100小时的会议录音。有关语料库的温和介绍,请参阅语料库概述。要访问数据,请发出的指示有。大约三分之二的数据是通过参与者在...

房间响应和噪声数据库 标识符:SLR28 摘要:模拟和真实房间脉冲响应,各向同性和点源噪声的数据库。此数据中的音频文件均为16k采样率和16位精度。 类别:音频 许可证:Apache 2.0 关于...

THUYG-20维吾尔语,语音识别,语音数据 标识符:SLR22 摘要:免费的维吾尔语言数据库由CSLT @清华大学和新疆大学发布 类别:演讲 许可证:Apache License v.2.0 介绍THUGY20是由语音和语言技术中...

项目名称: TIMIT声学 - 语音连续语音语料库 作者(S): John S. Garofolo,Lori F. Lamel,William M. Fisher,Jonathan G. Fiscus,David S. Pallett,Nancy L. Dahlgren,Victor Zue 国家编号: LDC93S1 ISBN: 1-58563...

麻省理工学院生物和计算学习中心车辆数据库 综合汽车(CompCars)数据集 新闻 2015-09-25监视自然图像在下载链接中以sv_data。*发布。下载所有此类文件,然后使用与Web-nature数据相同的密...

汽车数据集 概观 该 汽车 数据集包含196类汽车的16185个图像。 数据分为8,144个训练图像和8,041个测试图像,其中每个类别大致分为50-50个分割。 课程通常在 Make,Model,Year等 级别 ,例如...

该目录包含2014年4月至9月纽约市超过450万部Uber皮卡的数据,以及2015年1月至6月期间超过1430万部Uber皮卡。其他10家租车(FHV)公司的旅行级数据作为329 FHV公司的汇总数据,也包括在内。...

KITTI是一系列以自动驾驶为目标的机器视觉任务数据,包括:空间建模、视觉流、视觉测距、3D物体检测、3D物体追踪等。数据来自一辆搭载2台彩色和黑白摄像机、360度激光雷达和GPS定位...

MPIIHumanShape人体模型数据是一系列人体轮廓和形状的3D模型及工具。模型是从平面扫描数据库CAESAR学习得到。 MPII Human Shape是一系列富有表现力的3D人体形状模型和工具,用于人体形状空间...
TCGA-ESCA 癌症 CT 影像数据是食道癌相关的数据集,包含 185 人的 5271 个文件,旨在对各种类型的癌症诊治过程进行全程数字化的跟踪,以数字档案的形式记录检查结果、处方和疗效。该数...

TCGA-CESC 癌症CT影像数据,旨在对各种类型的癌症诊治过程进行全程数字化的跟踪,以数字档案的形式记录检查结果、处方和疗效。...
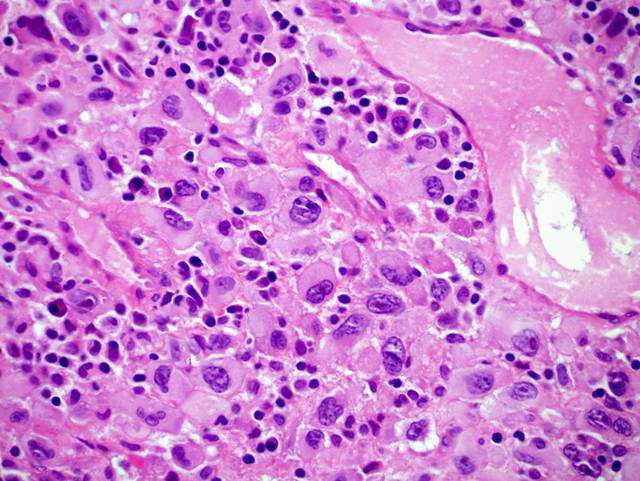
将对腺体分割问题感兴趣的研究,以验证他们现有或新发明的算法在同一标准数据集上的性能。我们将为参与者提供苏木精和伊红(H&E)染色载玻片的图像,包括各种组织学等级。 腺...
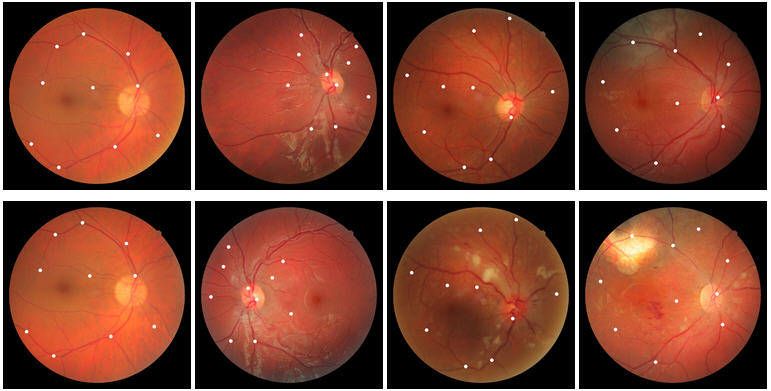
FIRE 是一个视网膜眼底图像数据集,包含 129张 眼底视网膜图像,由不同特征组合成 134对 图像组合。这些图像组合根据特质被划分为3类。眼底图像由 NidekAFC-210 眼底照相机采集,分辨率...

EGG大脑电波形状数据 EEGbrainwaveforconfusion_Forvariableselectionandcausalinference...

Zeeshan-ul-hassan Usmani的基因组表型SNPs原始数据 基因组学是分子生物学的一个分支,涉及基因组的结构,功能,变异,进化和绘图。有几家公司提供下一代人类基因组测序,从完整的30亿个...
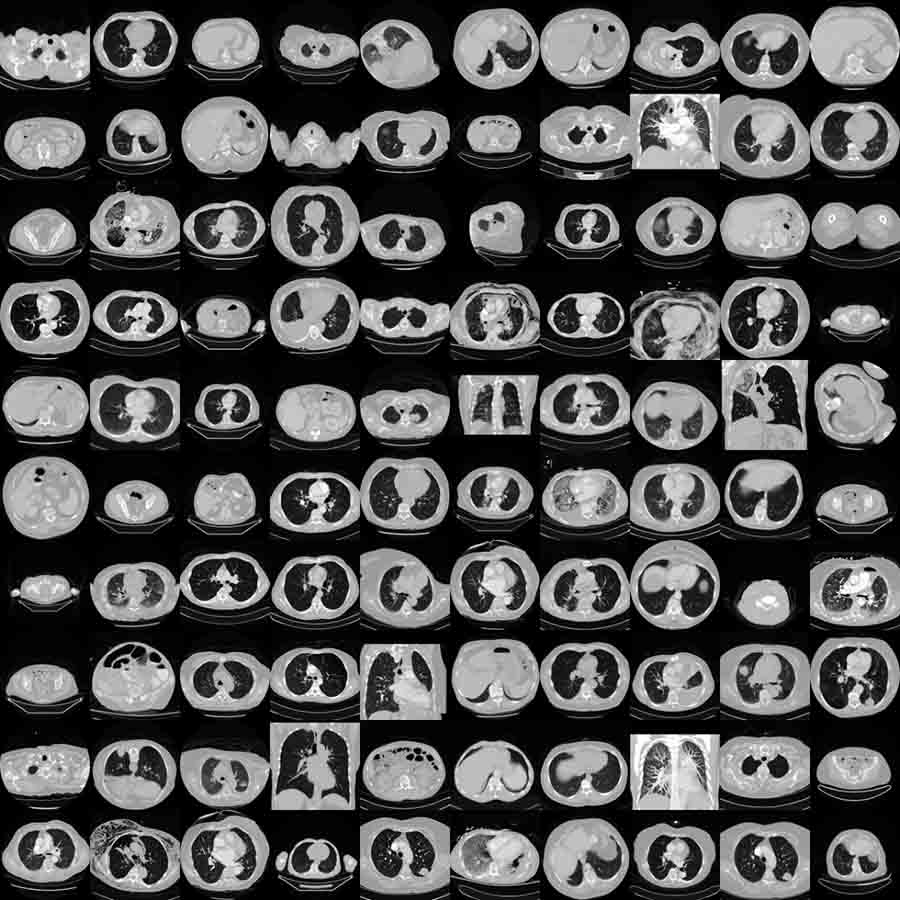
本数据集是一个癌症CT图像数据,包括69位不同的患者的475个病例的中等规模的CT影像和患者年龄。该数据是 TCGA-LUAD 肺癌CT影像数据库的一部分。...
SegmentingSoftTissueSarcomas是由手术病理确认的软组织肉瘤的医学PET-CT图像,从2004年11月到2011年11月,有19例病例发现了肺部转移。 摘要 该数据是TCIA研究的预处理子集,名为Soft Tissue Sarcoma。...

食品数据库 Open Food Facts是一个免费的,开放的,来自世界各地的食品产品数据库,包括成分,过敏原,营养成分以及我们可以在产品标签上找到的所有信息。5000多个贡献者已经使用我...

在我们的广域人群计数论文中使用的多视图人群计数数据集包括我们提议的数据集CityStreet,以及两个现有数据集PETS2009和DukeMTMC重新用于多视图人群计数。 发布的数据集文件由指令文档...

ETH Pedestrian dataset 是一个包含行人的视频数据,可用以进行行人检测和识别等机器视觉任务。...

公路交通数据集(聚类) 用于聚类视频纹理的高速公路交通视频数据集。 文件: zip (42MB) 如果您使用此数据集,请引用: 使用动态纹理混合对视频进行建模,聚类和分段。 Antoni...

Traffic Lights Recognition (TLR) 是一个交通信号灯识别的视频数据,在真实的道路上采集的交通信号灯视频,分辨率为 640x480,由法国一所大学提供。公共数据库,城市场景中交通灯识别(TL...

CelebFaces属性数据集(CelebA) 是一个大型人脸属性数据集,拥有超过 200K的 名人图像,每个图像都有 40个 属性注释。 此数据集中的图像覆盖了大的姿势变化和背景杂乱。 CelebA拥有大量...

CMU-Oxford Sculpture数据集包含143K图像,描绘了242位艺术家的2197件艺术作品。每张图片都为我们的CVPR论文中定义的每个3D形状属性提供了12个标签。我们还提供示例MATLAB代码,用于说明读取...

FacesintheWild是一个人脸数据集,从新闻照片中采集,包括30281张 人脸图像及标注信息,标注信息通过Whos in the Picture系统自动产生,约有80%的标注正确率。 数据集Faces in the Wild由新闻摄影...

Common ob

Places2 是一个场景图像数据集,包含 1千万张 图片,400多个不同类型的场景环境,可用于以场景和环境为应用内容的视觉认知任务。 该目标是识别照片中描绘的场景类别。此任务的数据...

著名的猫图像标注数据集(Cat Annotation Dataset),包含 10000张 各种类型和环境下猫的图像以及相应的猫轮廓位置标注信息。 Cat注释数据集 CAT数据集包括10000个猫图像。对于每个图像,我...

多域情感数据集包含从Amazon.com获取的许多产品类型(域)的产品评论。一些域名(书籍和DVD)有成千上万的评论。其他(乐器)只有几百个。评论包含星级(1至5星),如果需要可以转...

美国 reddit 新闻网站最受欢迎的 2500 名发布者每家媒体 1000 个发布内容及评论数据集,来自订阅者的前2,500个子评价,从2013年8月15日至20日期间从reddit提取。 这是什么? 这是来自reddit的...

ICWSM 2010论文中的数据可从以下链接获得。我们的数据集已匿名化,以保护用户自己的隐私。我们只发布有关Twitter链接结构的信息。 数据集 链接列表: 此文件包含我们在2009年9月根据...
什么是JRC名称? JRC-Names是一个高度多语言的命名实体资源,用于个人和组织名称(称为实体)。它包含大量名称列表及其多种拼写变体(单个人最多可达数百种),包括跨脚本(拉丁语...

WikiText英语词库数据(TheWikiTextLongTermDependencyLanguageModelingDataset)WikiText长期依赖语言建模数据集是一个包含1亿个词汇的英文词库数据,这些词汇是从Wikipedia的优质文章和标杆文章中提取...
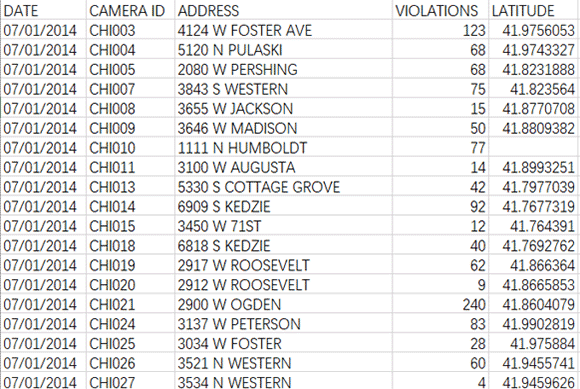
2014 - 2016年芝加哥的摄像机违规行为, 芝加哥街头摄像机记录的每日限速违规行为。此数据集反映了作为自动速度执行计划的一部分,安装在芝加哥市的每台摄像机记录的每日违规速度...

LabelMe图像注释标注工具源代码 LabelMe的目标是提供在线注释工具,为计算机视觉研究构建图像数据库。在这里将介绍在服务器上安装LabelMe注释工具的源代码。LabelMe是一个用ja


下游不火,机器人产业不可能做起来

缓存与数据库双写一致性

明略数据发布“符号的力量——行业AI大脑明智系

大数据驱动城市创新 百分点共同发起成立北京城

蔡维德:全球有几百位公链开发者 却有几万条公

互联网金融,要便捷更要安全
新冠肺炎“识别”战,AI算法落地有多难?

贵州大数据榜单项目“多源数据融合集成与分析

蚂蚁金服:SQLFlow是牛刀初试,实时大数据
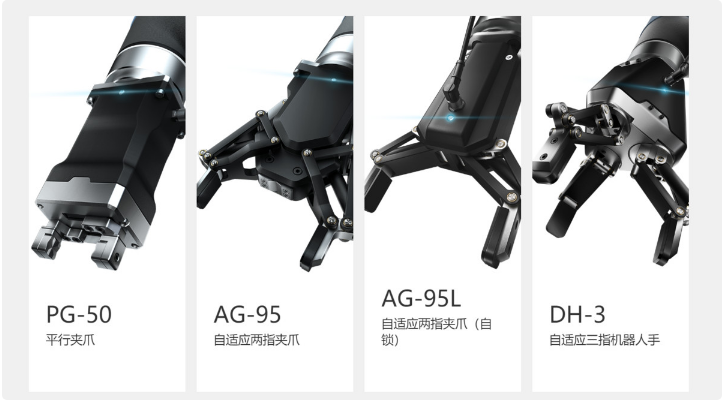
瞄准迅速增长的工业机器人和协作机器人行业

5G警用机器人上岗护航五一节日安保

专家议报告|深圳市人工智能与机器人研究院执
自动驾驶方向开源数据集资源汇总

欧盟对中国电动自行车加征临时关税

欧盟对中国电动自行车加征临时关税

欧盟《人工智能法案》正式生效

人形机器人的万亿市场,中国竞争力如何?

有分析认为,人工智能(AI)市场从去年开始展开寻找硬件主导股后,在泡沫争议不断的情况下,寻找软件(SW)主导股的大框架将发生改变。

人工智能也可“望闻问切”

多名院士专家谈人工智能:中国发展AI不能靠“堆芯片”

大学生创业者追逐AI风口
大学生创业者追逐AI风口

图像像素级精度是机器学习图像标注的唯一出路

医疗设备中的人工智能:这些都是新兴的行业应用

刷脸支付有风险!央视曝光一女子刷脸后背上万元贷款

如何防止AI在自拍中识别出你的脸