机器学习决策树简介
机器学习中的决策树
现代机器学习算法正在彻底改变我们的日常生活。例如,像 BERT 这样的大型语言模型正在为谷歌搜索提供支持,而 GPT-3 正在为许多高级语言应用程序提供支持。
如今,构建复杂的机器学习算法比以往任何时候都容易。然而,无论机器学习算法变得多么复杂,它都属于以下学习类别之一:
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
决策树是最古老的监督机器学习算法之一,可以解决广泛的现实问题。研究表明,决策树算法的最早发明可以追溯到 1963 年。
让我们深入研究这个算法的细节,看看为什么这类算法在今天仍然很流行。
什么是决策树?
决策树算法因其处理复杂数据集的简单方法而成为一种流行的监督机器学习算法。决策树之所以得名,是因为它们与包含节点和边形式的根、分支和叶子的树相似。它们用于决策分析,很像导致所需预测的基于 if-else 的决策流程图。树学习这些 if-else 决策规则来拆分数据集以制作树状模型。
决策树可用于预测分类问题的离散结果和回归问题的连续数值结果。多年来开发了许多不同的算法,如CART、C4.5和集成,如随机森林和梯度提升树。
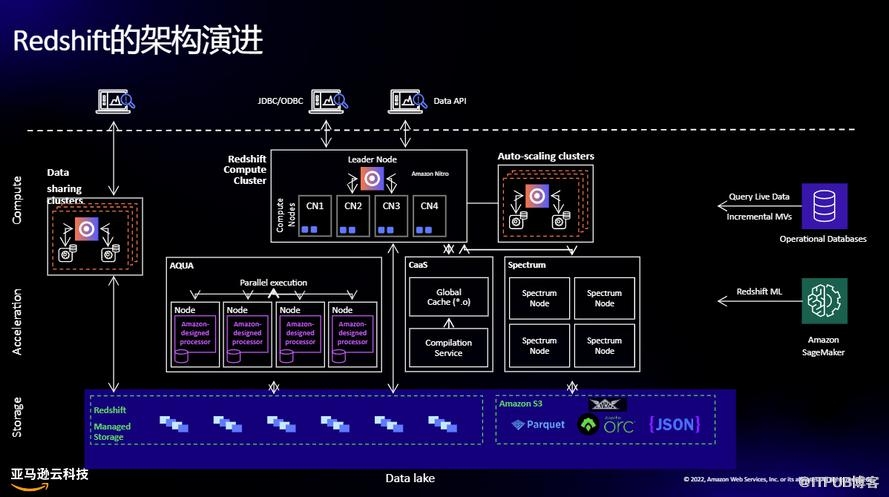
剖析决策树的各个组成部分
决策树算法的目标是预测输入数据集的结果。树的数据集采用属性、属性值和要预测的类的形式。与任何监督学习算法一样,数据集分为训练集和测试集。训练集定义了算法学习并应用于测试集的决策规则。
在进入决策树算法的步骤之前,让我们先了解一下决策树的组成部分:
- 根节点: 它是包含所有属性值的决策树顶部的起始节点。根节点根据算法学习到的决策规则分裂成决策节点。
- 分支: 分支是对应于属性值的节点之间的连接器。在二进制拆分中,分支表示真路径和假路径。
- Decision Nodes/Internal Nodes: 内部节点是介于根节点和叶节点之间的决策节点,对应决策规则及其答案路径。节点表示问题,分支显示基于这些问题的相关答案的路径。
- 叶节点: 叶节点是代表目标预测的终端节点。这些节点不再分裂。
以下是决策树及其上述组件的可视化表示:
决策树算法通过以下步骤来达到所需的预测:
- 该算法从具有所有属性值的根节点开始。
- 根节点根据算法从训练集中学习到的决策规则分裂成决策节点。
- 根据问题及其答案路径通过分支/边缘通过内部决策节点。
- 继续前面的步骤,直到到达叶节点或直到所有属性都已被使用。
为了在每个节点选择最佳属性,根据两个属性选择指标之一进行拆分:
- 基尼指数衡量基尼不纯度,以指示算法对随机类标签进行错误分类的可能性。
- 信息增益衡量拆分后熵的改进,以避免预测类的 50/50 拆分。熵 是给定数据样本中杂质的数学度量。几乎 50/50 的分裂表明决策树中的混乱。
决策树算法的花卉分类教程
考虑到上述基础知识,让我们继续实施。对于本文,我们将使用 Scikit-learn 库在 Python 中实现决策树分类模型。
关于数据集:本教程的数据集是鸢尾花数据集。Scikit 学习数据集库已经有这个数据集,所以不需要外部加载它。该数据集包括四种鸢尾花属性及其值,这些属性将被输入以预测三种鸢尾花中的一种。
- 数据集中的属性/特征: 萼片长度、萼片宽度、花瓣长度、花瓣宽度。
- 数据集中的预测标签/花类型: Setosis、Versicolor、Virginica。
以下是决策树分类器的 python 实现的分步教程:
导入库
首先,以下代码导入执行决策树实现所需的库。
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
加载 Iris 数据集
以下代码使用 load_iris 函数从data_set 变量中的 sklearn.dataset 库加载鸢尾花数据集。在接下来的两行中打印虹膜类型和特征。
data_set = load_iris()
print('Iris plant classes to predict: ', data_set.target_names)
print('Four features of iris plant: ', data_set.feature_names)
分离属性和标签
下面几行代码将花的特征和种类分离出来,存储在变量中。shape[0]函数确定存储在X_att变量中的属性数量。我们数据集中的属性值总数为 150。
#Extracting data attributes and labels
X_att = data_set.data
y_label = data_set.target
print('Total examples in the dataset:', X_att.shape[0])
我们还可以通过将X_att变量中的值添加到pandas库中的DataFrame函数来为数据集中的一部分属性值创建表格可视化。
data_view=pd.DataFrame({
'sepal length':X_att[:,0],
'sepal width':X_att[:,1],
'petal length':X_att[:,2],
'petal width':X_att[:,3],
'species':y_label
})
data_view.head()
拆分数据集
以下代码使用train_test_split函数将数据集拆分为训练集和测试集。此函数中的random_state参数用于为函数提供随机种子,以便在每次执行时为给定数据集提供相同的结果。test_size表示测试集的大小。0.25表示划分25%的测试数据和75%的训练数据。
#Splitting the data set to create train and test sets
X_att_train, X_att_test, y_label_train, y_label_test = train_test_split(X_att, y_label, random_state = 42, test_size = 0.25)
应用决策树分类函数
以下代码通过使用DecisionTreeClassifier函数创建分类模型 并将标准设置为'entropy'来实现决策树。该标准将属性选择度量设置为信息增益。 之后,代码使模型适合我们的属性和标签训练集。
#Applying decision tree classifier
clf_dt = DecisionTreeClassifier(criterion = 'entropy')
clf_dt.fit(X_att_train, y_label_train)
计算模型精度
下面的一段代码正在计算并打印决策树分类模型在训练集和测试集上的准确性。为了计算准确度分数,我们使用预测 函数。训练集的准确率为 100%,测试集的准确率为 94.7%。
print('Training data accuracy: ', accuracy_score(y_true=y_label_train, y_pred=clf_dt.predict(X_att_train)))
print('Test data accuracy: ', accuracy_score(y_true=y_label_test, y_pred=clf_dt.predict(X_att_test)))
真实世界的决策树应用
决策树在许多行业的决策过程中都有应用。决策树的常见应用见于金融和市场营销领域。它们可用于:
- 贷款审批,
- 支出管理,
- 客户流失预测,
- 新产品的可行性,等等。
如何改进决策树?
综上所述,决策树的基本背景和实现可以安全地假设它们仍然因其可解释性而广受欢迎。决策树易于理解的原因是它们可以被人类可视化和解释。因此,它们是解决机器学习问题的直观方法,同时还确保结果是可解释的。机器学习中的可解释性是我们过去讨论过的一个话题,它也与人工智能伦理的新兴主题有关。
与任何机器学习算法一样,也可以改进决策树以避免过度拟合和偏向主导预测类。修剪和集成是克服决策树算法缺点的常用方法。即使存在这些缺点,决策树仍然是决策分析算法的基础,并且在机器学习中始终保持相关性。

时间:2022-12-06 16:37 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论: