ABtest 和假设检验、流量分配
我们观测到的值,并不是我们需要的参数的真实值,而是真实值的估计(举个例子,平均值和期望);这也就意味着,估计可能是不准确的,ABtest 的结果可能是错误的。直观上说,样本越多,我们可能犯错的概率越小。我们梳理了这块儿的知识,做一个学习总结。
实际业务中,我们定量下面几个问题:
1)ABtest 是否置信
2)一组 ABtest 只需要多少样本就可以有显著性
3)怎么分配流量来进行多组 ABtest 计划,保证各组测试都能显著
ABtest 和假设检验
1)中心极限定理和正态分布,z 检验
中心极限定理说明,在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布(具体推导参考大数定理、中心极限定理)。
在样本数量比较大情况下,可以采用 z 检验。
ABtest 需要采用双样本对照的 z 检验公式。

2)H0、H1 假设和显著性、置信区间、统计功效
现在假设有 A、B 两个组,我们无法确定 A、B 两个组的差异究竟是某种误差引起的,还是客观存在的。所以假定:
- H0=A、B 没有本质差异
- H1=A、B 确实存在差异
显著性 根据 z 检验算出 p 值,通常我们会用 p 值和 0.05 比较,如果 p<0.05, 我们就接受 H0,认为 AB 没有显著差异。
置信区间 是用来对一个概率样本的总体参数进行区间估计的样本均值范围,它展现了这个均值范围包含总体参数的概率,这个概率称为置信水平。
双样本的均值差置信区间估算公式如下:

统计功效 power是说拒绝零假设(H0)后接受正确的 H1 假设概率。直观上说,AB 即使有差异,也不一定能被你观测出来,必须保证一定的条件(比如样本要充足)才能使你能观测出统计量之间的差异;否则,结果也是不置信的,具体的,可以参考下面这张图:
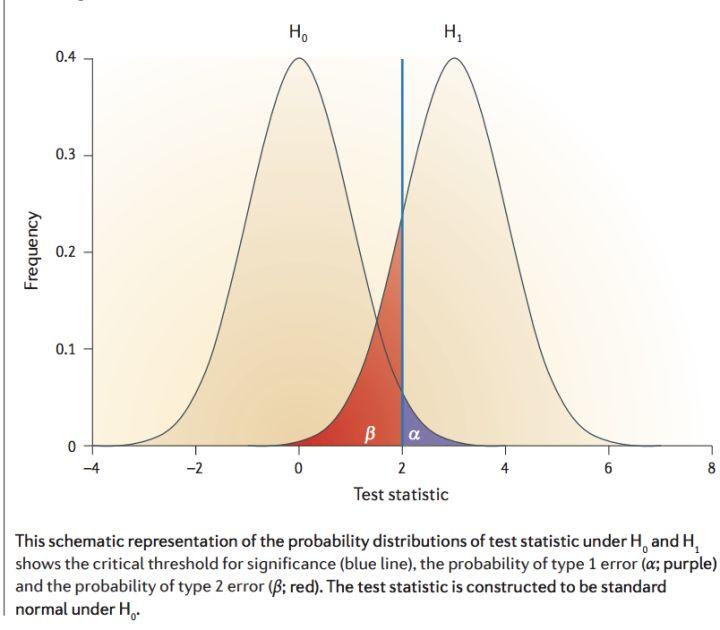
统计功效的计算公式如下:

3)版本替代决策
做完 ABtest 后,应该用上图中的置信区间,和期望收益比较,做版本替代决策。
比如新版本的期望收益是 2%,而检验后置信区间是 [16%,20%],那我们有理由替换旧版本。
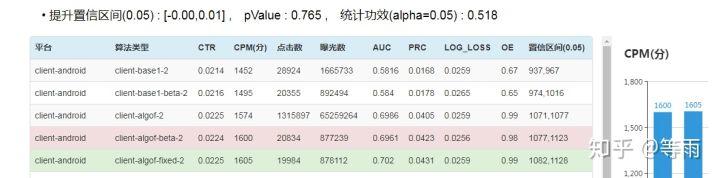
业务中,我们的 ABtest 检验工具如下图所示,算法人员选择 AB 组就可以一次计算完相关检验参数:
ABtest 的流量分配
一个 ABtest 计划需要多大样本量?
假设双样本都有相同的标准差  并已有估计值,知道了 n1,以及双样本的均值差 (
并已有估计值,知道了 n1,以及双样本的均值差 (  );再假设 power=0.8,a=0.05,那么我们可以根据公式推导出最低样本量 n2:
);再假设 power=0.8,a=0.05,那么我们可以根据公式推导出最低样本量 n2:
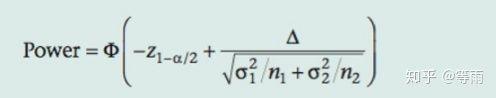
可以使用 Python 的 statsmodels 模块的相关方法来预估最低样本数,相关代码如下:
from statsmodels.stats.power import NormalIndPower
def main():
zpower = NormalIndPower()
effect_size = (1145 - 1132) / 20000.0
nobs1 = 1200000
print zpower.solve_power(
effect_size=effect_size,
nobs1=nobs1,
alpha=0.05,
power=0.8,
ratio=None,
alternative='two-sided'
)
main()
这个方法可以在指定其中一些参数的情况下,求解未知的一个参数,具体用法可以参考官方文档。
ABtest 的流量分配框架
一般来说,会有不同层的多组 ABtest 要进行 (从 UI 到算法到策略等),所以常规是采用多层 ABtest 框架。但是也有独占流量这种类灰度测试(比如不想引入多组测试时敏感的互斥关系,或者版本改造比较大),所以层之外,又分成若干个独立域。
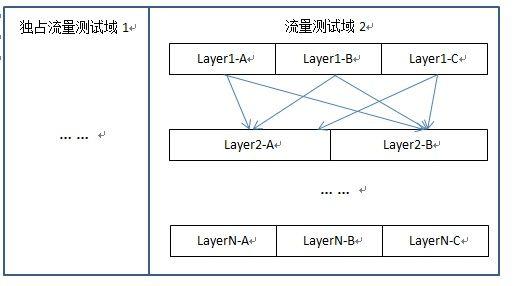
多域多层 ABtest 框架
layer 之间要能独立,最好 layer 之间是完全的正交测试。域之间流量分配遵循独立对等原则。
新加入一组 ABtest 遵循的流程,以及流量分配方案
现在要新加入一组 ABtest,我们遵循以下流程:
1)判断是否开启独占测试,否则选择加入当前某个测试域;
2)根据历史经验估算 ;(如果不好估算,那么就做一次抽样测试先,提取出大概值然后估算)
;(如果不好估算,那么就做一次抽样测试先,提取出大概值然后估算)
假设 power=0.8,a=0.05。再采用前述的 ABtest 样本量估算方法,计算得出需要的最低样本量 n;
3)根据最低样本量 n,判断是否需要扩充当前域的流量。由于新测试将减少旧测试所得样本量,所以为简单计,倾向于直接从主流桶中分配 r 个单位的流量进当前域,使:
sum(r) == n
从而满足新旧测试的量需求;
4)完成配置,发布版本,上线新测试。
另外一个问题,如果一组 ABtest 效果显著有效,也不见得就能说明 ABtest 是可信的。毕竟当前的样本分布,无法代表未来的样本分布。所以,我们应该做多久的 ABtest 才可以接近真实分布呢? 这看起来没有答案,就跟我们没法有效预测单只股票的涨跌一样,也许只能在长时间周期中做完多个窗口的轮动回测,才能得到心里安慰吧
参考文献:
A/B Testing Tech Note: determining sample size
大数定理和中心极限定理http://staff.ustc.edu.cn/~zwp/teach/Prob-Stat/Lec11_slides.pdf

时间:2019-04-22 18:48 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















