《搜索与推荐中的深度学习匹配》之推荐篇
这个 tutorial 确实不错https://www.comp.nus.edu.sg/~xiangnan/sigir18-deep.pdf,我很喜欢,好像一个博士论文一样,将这两个领域梳理得很清楚。
搜索,推荐和广告其实是机器学习在工业界最好的落地。而且容易拿到由用户的行为来表示的海量的标注数据,而且这三者要不可以赚钱,要不可以增加流量,往往是公司的核心业务。
其实这篇 tutorial 主要讲推荐模型的,而实际上推荐就是一个匹配问题,所以标题才叫推荐里的深度学习匹配。另外,由于广告和推荐的技术很像,所以对广告技术感兴趣的人也可以看看这篇 tutorial。
本篇 blog 的提纲:
- part-1 推荐系统的概述
- part-2 推荐系统里的传统匹配模型:
-
part-2.1 Collaborative Filtering Models
- part-2.2 Generic Feature-based Models
-
part-3 推荐系统里的深度学习匹配模型:
-
part-3.1 基于 representation learning 的方法:
-
part-3.1.1 基于 Collaborative Filtering 的一些方法介绍
- part-3.1.2 基于 Collaborative Filtering + Side Info 的一些方法介绍
-
part-3.2 基于 matching function learning 的方法:
-
part-3.2.1 基于 Neural Collaborative Filtering 的一些方法介绍
- part-3.2.2 基于 Translation 的一些方法介绍
- part-3.2.3 Feature-based 的一些方法介绍
-
part-3.3 Modern RecSys Architecture : representation learning 和 matching function learning 的融合
-
part-4 short summary
part-1 推荐系统的概述
推荐系统是由系统来根据用户过去的行为、用户的属性(年龄、性别、职业等)、上下文等来猜测用户的兴趣,给用户推送物品(包括电商的宝贝、新闻、电影等)。推荐一般是非主动触发的,和搜索的主动触发不一样(搜索一般有主动提供的 query);也有小部分情况,用户有提供 query:例如用户在电商里搜索一个商品后,结果页最底下推荐给用户的商品,这种情况算是有提供 query。
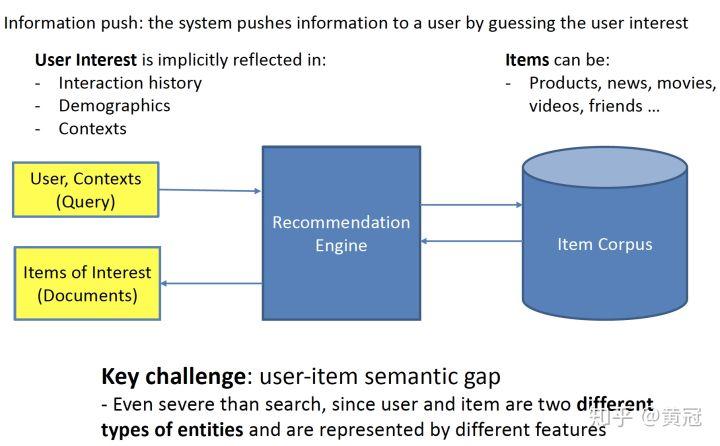
搜索一般是想尽快的满足用户,而推荐是更多的是增加用户停留时长。
推荐系统涉及到的两大实体:user 和 item 往往是不同类型的东西,例如 user 是人,item 是电商的宝贝,他们表面上的特征可能是没有任何的重叠的,这不同于搜索引擎里的 query 和 doc 都是文本:

正是由于 user 和 item 不同类型的东西,所以推荐里匹配可能比搜索里的更难。
接下来是,推荐系统里的传统匹配模型的介绍。
part-2 推荐系统里的传统匹配模型
先简单的提一下推荐算法的分类:
- 基于内容的推荐
- 基于协同过滤(CF)的推荐
-
一般是基于用户的行为,可以不用上内容信息
-
基于规则的推荐
- 基于人口统计信息的推荐
- 混合推荐
part-2.1 Collaborative Filtering Models
协同过滤(CF)是推荐里最通用、最著名的算法了。
CF 的基本假设是:一个用户的行为,可以由跟他行为相似的用户进行推测。
协同过滤一般分为 user-based 和 item-based、model-based 三类方法。user-based 和 item-based、model-based 的协同过滤的算法的思想通俗的讲,就是:
- user-based:两个用户 A 和 B 很相似,那么可以把 B 购买过的商品推荐给 A(如果 A 没买过);例如你和你的师兄都是学机器学习的,那么你的师兄喜欢的书籍,你也很有可能喜欢
- item-based: 两个 item:A 和 B 很相似,那么某个用户购买过 A,则可以给该用户推荐 B。例如一个用户购买过《模式识别》这本书,它很有可能也喜欢《推荐系统》这本书。计算两个 item 是否相似的一种简单方法是,看看他们的共现概率,即他们被用户同时购买的概率
- model-based: 用机器学习的思想来建模解决,例如聚类、分类、PLSA、矩阵分解等
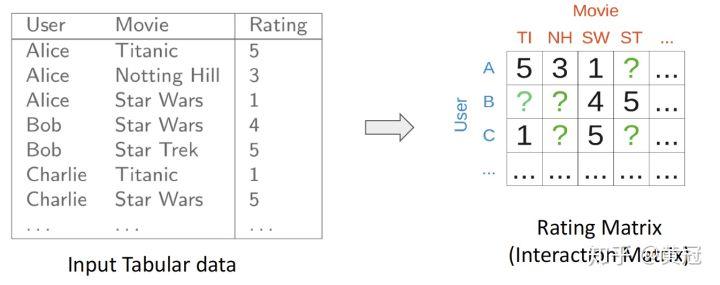
CF 要解决的问题用数学化的语言来表达就是:一个矩阵的填充问题,已经打分的 item 为 observed data,未打分的是 missing data:
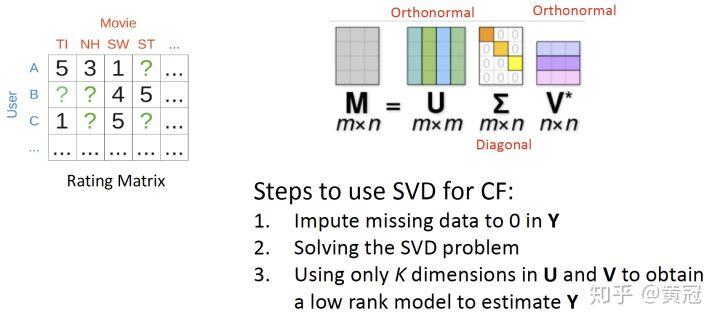
- 矩阵填充一般是用 SVD 分解来解决:
SVD 就是在解决以下问题:
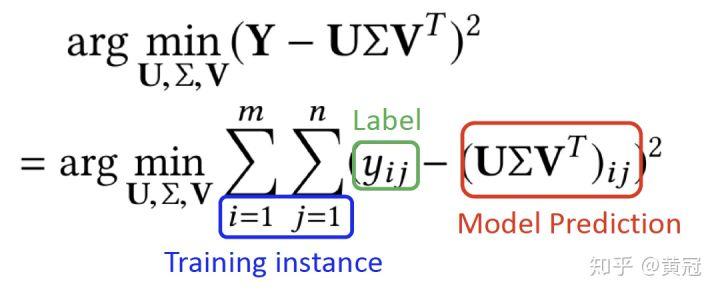
svd 有以下缺点:
1.missing data(就是没打分的,占比 99%) 和 observed data(观测到的、已打分的)有一样的权重。
2. 没有加正则,容易过拟合。
- MF(matrix Factorization,user-based CF)
user 和 item 分别用一个 embedding 表示,然后用户对 item 的偏好程度用这两个 embedding 的内积表示:
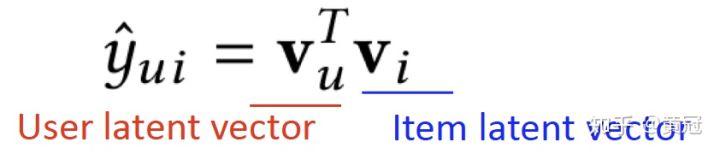
使用 L2-loss(其它 loss 也可以)和正则:
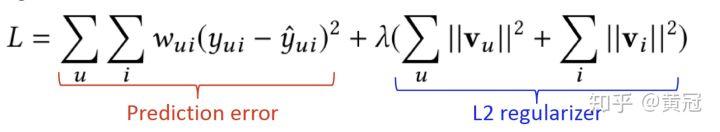
- Factored Item Similarity Model(Kabbur et al., KDD’14),FISM
这个论文是用 user 作用过的 item 的 embedding 的和来表示 user,item 用另一套 embedding 下的一个 embedding 来表示,最后两者的内积表示 user 对该 item 的偏好。

这个模型也叫 item-based 的 CF,因为把括号里的东西展开后,其实就是找用户作用过的 item 和 item[j] 的相似度。
- SVD++:
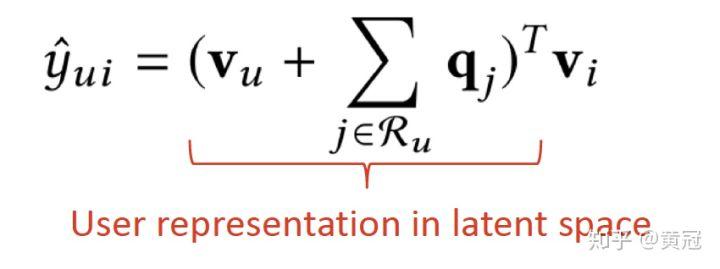
很简单,另外用一个 user 的 embedding,和上述的 FISM 的方法,融合来表示 user。这曾经是 netflix 比赛中连续三年效果最好的单模型。
part-2.2 Generic Feature-based Models
- FM: Factorization Machines (Rendle, ICDM’10)
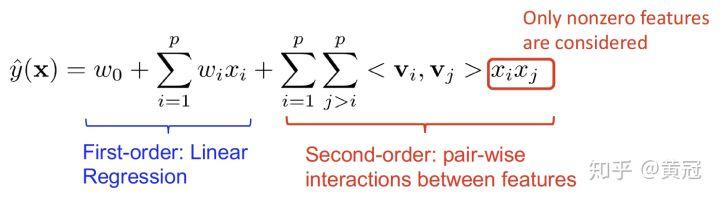
这个模型的最大的特点就是每一个特征都用要一个低维度的隐向量来表示(一般是 10 维左右),其实就是现在说的 embedding;可以自动的做 2 阶的特征组合(自己和自己不组合);并且很多其它的模型都是 FM 的特例。
当只有两个输入的时候:userID 和 itemID,FM 就等价于 MF(matrix factorization):
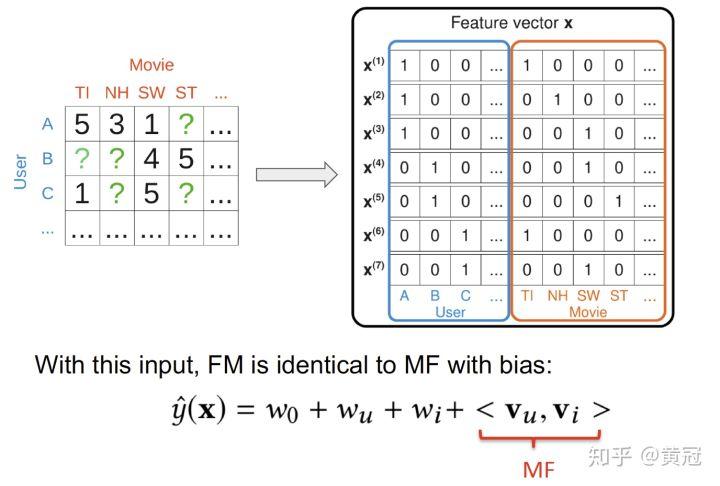
如果输入包含两个变量:1. 用户的历史作用过的 item 2. 要预测的 item 的 ID,那么 FM 也是包含了 FISM 模型的(Factored Item Similarity Model):
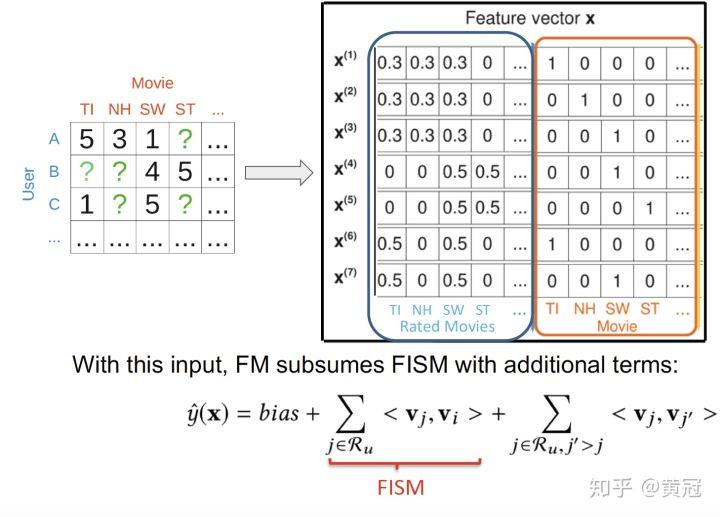
而如果再加上 user 的 embedding,那就包含了 svd++。所以 mf,fism 和 svd++ 都是 fm 的特例。
而实践证明用打分预测来解决推荐系统的排序问题,效果不好。可能的原因:
- 预测打分用的 RMSE 和排序指标有差异性
- 观测到的打分数据有 bias,例如用户偏向对他们喜欢的 item 打分
所以一般用 pairwise 的 ranking 来解决推荐的排序问题:
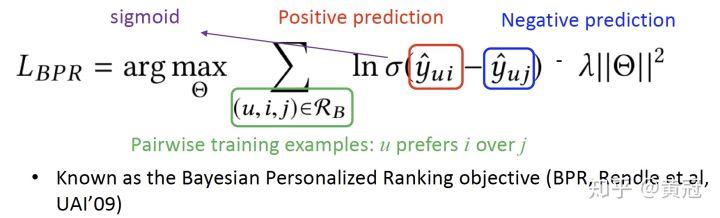
接下来我们介绍一下推荐系统里的深度学习匹配模型。
part-3 推荐系统里的深度学习匹配模型
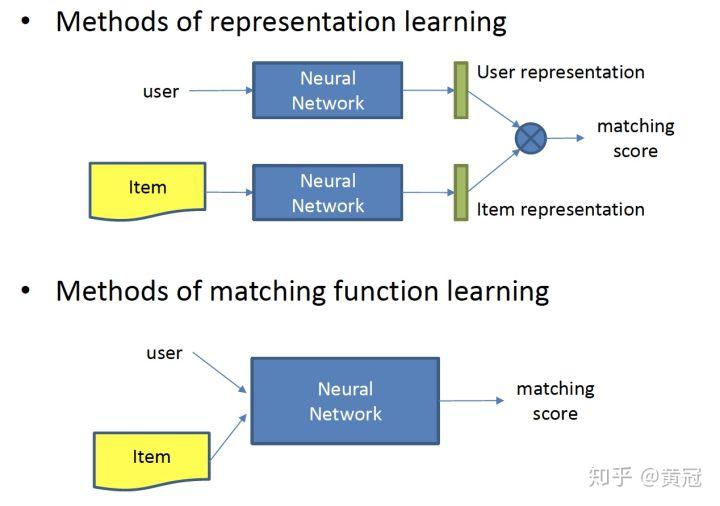
和搜索里的深度学习匹配模型一样,推荐里深度学习匹配模型也主要分两大类:
- representation learning,这类方法是分别由 NN,学习出 user 和 item 的 embedding,然后由两者的 embedding 做简单的内积或 cosine 等,计算出他们的得分
- matching function learning,这类方法是不直接学习出 user 和 item 的 embedding 表示,而是由基础的匹配信号,由 NN 来融合基础的匹配信号,最终得到他们的匹配分。
part-3.1 基于 representation learning 的一些方法介绍
此类方法,tutorial 也大概分为两类:
- 基于 Collaborative Filtering 的一些方法介绍
- 基于 Collaborative Filtering + Side Info 的一些方法介绍
part-3.1.1 基于 Collaborative Filtering 的一些方法介绍(representation learning)
这类方法是仅仅建立在 user-item 的交互矩阵上。
首先,简单复习一下 MF,如果用神经网络的方式来解释 MF,就是如下这样的:
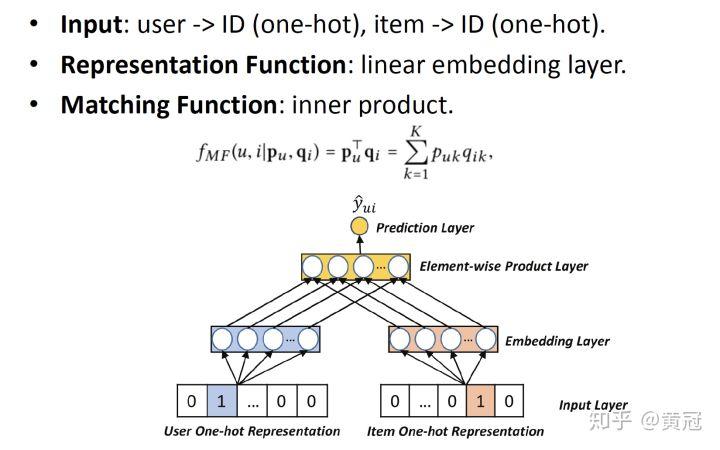
输入只有 userID 和 item_ID,representation function 就是简单的线性 embedding 层,就是取出 id 对应的 embedding 而已;然后 matching function 就是内积。
- Deep Matrix Factorization (Xue et al,IJCAI’17)
用 user 作用过的 item 的打分集合来表示用户,即 multi-hot,例如 [0 1 0 0 4 0 0 0 5],然后再接几层 MLP,来学习更深层次的 user 的 embedding 的学习。例如,假设 item 有 100 万个,可以这么设置 layer:1000 * 1000 ->1000->500->250
用对 item 作用过的用户的打分集合来表示 item,即 multi-hot,例如 [0 2 0 0 3 0 0 0 1],然后再接几层 MLP,来学习更深层次的 item 的 embedding 的学习。例如,假设 user 有 100 万个,可以这么设置 layer:1000 * 1000 ->1000->500->250
得到最后的 user 和 item 的 embedding 后,用 cosine 计算他们的匹配分:
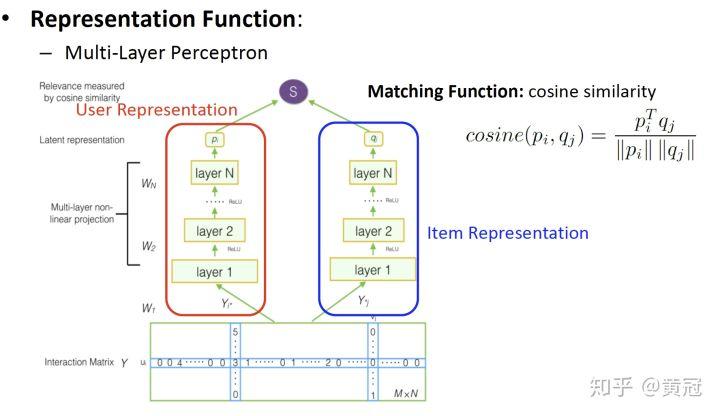
这个模型的明显的一个缺点是,第一层全连接的参数非常大,例如上述我举的例子就是 100010001000。
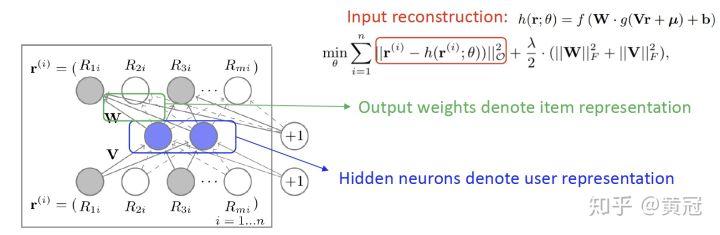
- AutoRec (Sedhain et al, WWW’15)
这篇论文是根据 auto-encoder 来做的,auto-encoder 是利用重建输入来学习特征表示的方法。
auto-encoder 的方法用来做推荐也分为 user-based 和 item-based 的,这里只介绍 user-based。
先用 user 作用过的 item 来表示 user,然后用 auto-encoder 来重建输入。然后隐层就可以用来表示 user。然后输入层和输出层其实都是有 V 个节点(V 是 item 集合的大小),那么每一个输出层的节点到隐层的 K 条边就可以用来表示 item,那么 user 和 item 的向量表示都有了,就可以用内积来计算他们的相似度。值得注意的是,输入端到 user 的表示隐层之间,可以多接几个 FC;另外,隐层可以用非线性函数,所以 auto-encoder 学习 user 的表示是非线性的。
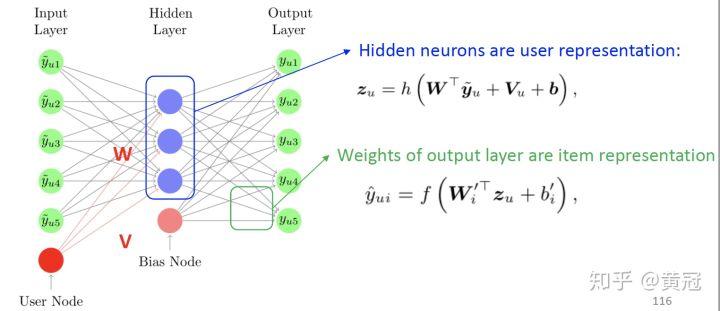
- Collaborative Denoising Auto-Encoder(Wu et al, WSDM’16)
这篇论文和上述的 auto-encoder 的差异主要是输入端加入了 userID,但是重建的输出层没有加 user_ID,这其实就是按照 svd 的思路来的,比较巧妙,svd 的思想在很多地方可以用上:
简单总结一下,基于 Collaborative Filtering 的做 representation learning 的特点:
- 用 ID 或者 ID 对应的历史行为作为 user、item 的 profile
- 用历史行为的模型更具有表达能力,但训练起来代价也更大
而 Auto-Encoder 的方法可以等价为:
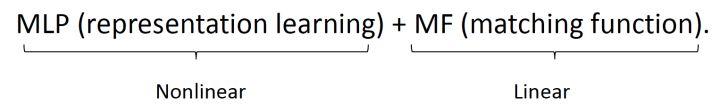
用 MLP 来进行 representation learning(和 MF 不一样的是,是非线性的),然后用 MF 进行线性的 match。
part-3.1.2 基于 Collaborative Filtering+side info 的一些方法介绍(representation learning)
这类方法是建立在 user-item interaction matrix + side info 上的。
- Deep Collaborative Filtering via Marginalized DAE (Li et al, CIKM’15):
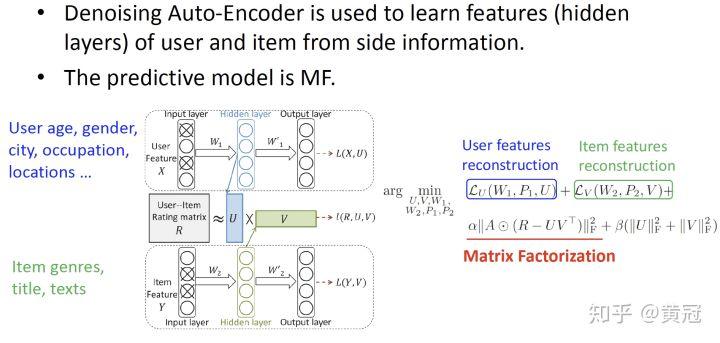
这个模型是分别单独用一个 auto-encoder 来学习 user 和 item 的向量表示(隐层),然后用内积表示他们的匹配分。
- DUIF: Deep User and Image Feature Learning (Geng et al, ICCV’15)
这篇论文比较简单,就是用一个 CNN 来学习 item 的表示(图像的表示),然后用 MF 的方法(内积)来表示他们的匹配分:
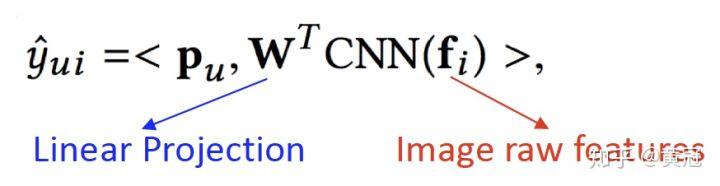
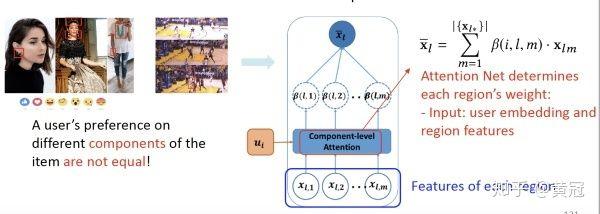
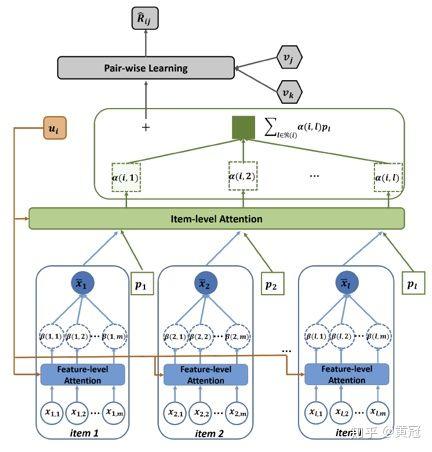
- ACF: Attentive Collaborative Filtering(Chen et al, SIGIR’17)
这篇论文主要是根据 SVD++ 进行改进,使用两层的 attention。
输入包括两部分:
- user 部分:user_ID 以及该 user 对应的作用过的 item
- item 部分:item_ID 和 item 的特征
两个层次的 attention:
-
Component-level attention:
-
不同的 components 对 item 的 embedding 表示贡献程度不一样,表示用户对不同 feature 的偏好程度
- 由 item 的不同部分的特征,组合出 item 的表示:
- attention weight 由下述式子做归一化后得到:
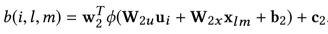
其中 u 表示用户的向量,x[l][m] 表示物品的第 m 部分的特征
-
Item-level attention:
-
用户历史作用过的 item,对用户的表示的贡献也不一样,表示用户对不同 item 的偏好程度
- attention weight 的计算公式如下,其中 u 表示用户的向量,v 表示基础的 item 向量,p 表示辅助的 item 向量,x 表示由上述的 component-level 的 attention 计算出来的 item 的特征的表示向量:
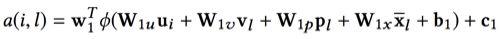
- 然后使用 svd++ 的方式计算用户的方式,只是这里的 item 部分不是简单的加和,而是加权平均:

这个论文是采用 pairwise ranking 的方法进行学习的,整个模型的结构图如下:
模型采用 pairwise ranking 的 loss 来学习:
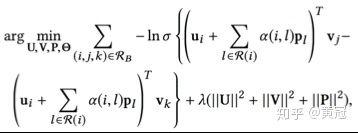
- CKE: Collaborative Knowledge Base Embedding (Zhang et al, KDD’16)
这篇论文比较简单,其实就是根据可以使用的 side-info(文本、图像等),提取不同特征的表示:
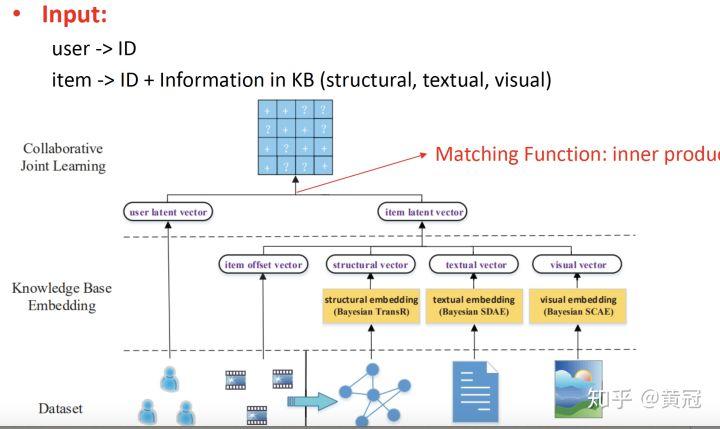
对上述方法做一个简单的总结(基于 Collaborative Filtering+side info 的一些方法介绍(representation learning)):
- Matching function 就是简单的 cosine
- 根据可以使用的 side-info(文本、图像、语音等),来选择适合的 DNN(MLP、auto-encoder、CNN、RNN 等)来描述 user、item 的 representation
part-3.2 基于 matching function learning 的方法
part-3.2.1 基于 Neural Collaborative Filtering 的一些方法介绍(matching function learning)
- Neural Collaborative Filtering Framework (He et al, WWW’17)
这篇论文是使用 NN 来学习 match function 的通用框架:
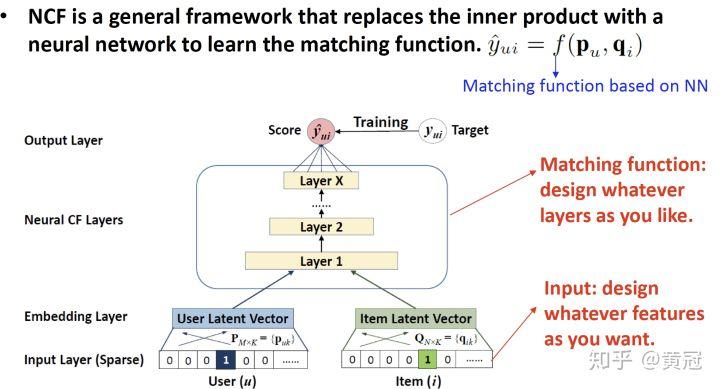
这篇论文的模型就是将 user 的 embedding 和 item 的 embedding concat 到一起,然后用几层 FC 来学习他们的匹配程度。
- MLP 在抓取多阶信息的时候,表现并不好
很不幸的是,MLP 效果并没有比内积好。有一篇论文证明了,MLP 在抓取多阶的信息的时候,表现并不好:
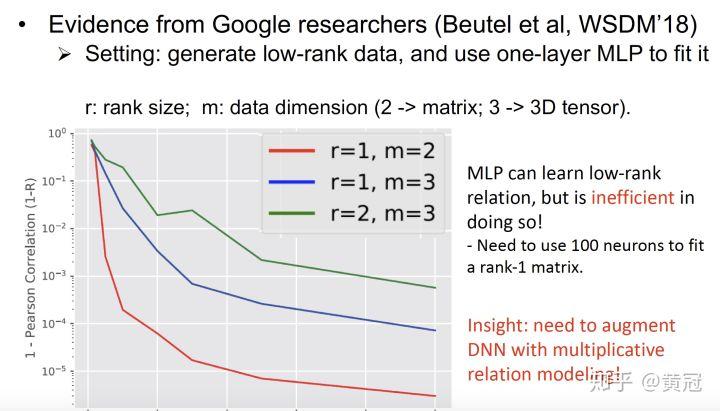
这篇论文要说的是,即使是二维的 1 阶的数据,也需要 100 个节点的一层 FC 才能比较好的拟合;而如果是 2 阶的数据,100 个节点的一层 FC 拟合得非常差,所以 MLP 在抓取多阶信息上并不擅长。不过个人总体上觉得这篇论文的说服力不够。
- NeuMF: Neural Matrix Factorization (He et al, WWW’17)
这篇论文其实是 MF 和 MLP 的一个融合,MF 适合抓取乘法关系,MLP 在学习 match function 上更灵活:
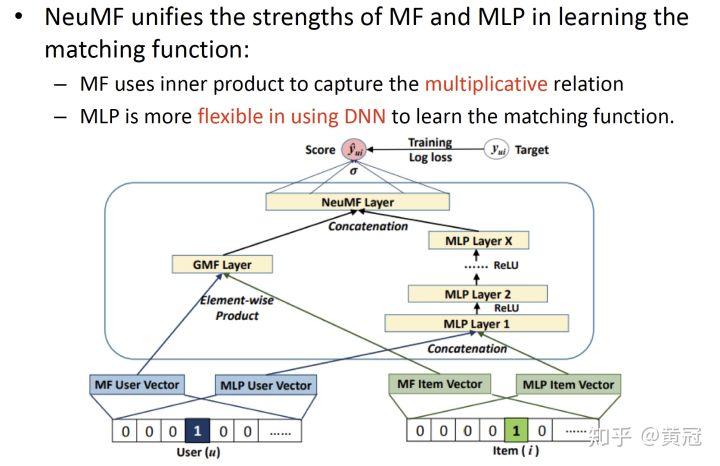
user 和 item 分别用一个单独的向量做内积(element-wise product,没求和)得到一个向量 v1;然后 user 和 item 分别另外用一个单独的向量,通过几层 FC,融合出另外一个向量 v2,然后 v1 和 v2 拼接 (concat) 到一起,再接一个或多个 FC 就可以得到他们的匹配分。
- NNCF: Neighbor-based NCF(Bai et al, CIKM’17)
这篇论文主要是将 user 和 item 的 neighbors 信息引入。至于 user 和 item 的 neighbor 怎么挖掘,就有很多算法了,包括直接和间接的 neighbors。例如两个用户同时购买过某个商品,他们就是 neighbor 等。
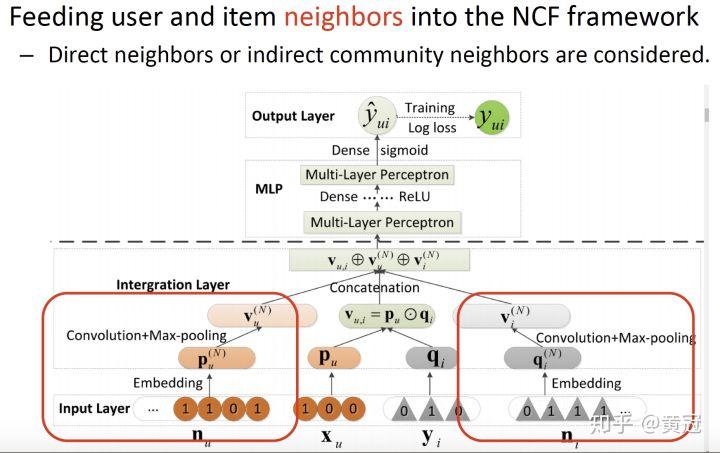
底层是用户的向量和 item 的向量的 element-wise dot 的结果拼接上另外两个向量:
- user 的 neighbor 信息(每个 neighbor_ID 也映射成向量),通过卷积和 max-pooling 后得到的向量
- item 的 neighbor 信息,通过卷积和 max-pooling 后得到的向量
效果:
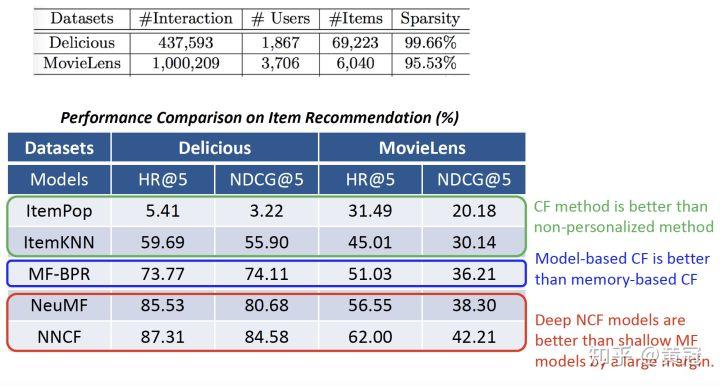
Deep NCF 效果要远远比 MF 好;而 NeuMF 要比普通的 MF 效果要好,说明加了 MLP 来做 match function learning 要比简单的内积效果要好。
- ONCF: Outer-Product based NCF (He et al, IJCAI’18)
上述的模型,user 向量和 item 向量要不是 element-wise product,要不是 concat,这忽略了 embedding 的不同维度上的联系。一个直接的改进就是使用 outer-product,也就是一个 m 维的向量和 n 维的向量相乘,得到一个 m*n 的二维矩阵(即两个向量的每一个维度都两两相乘):
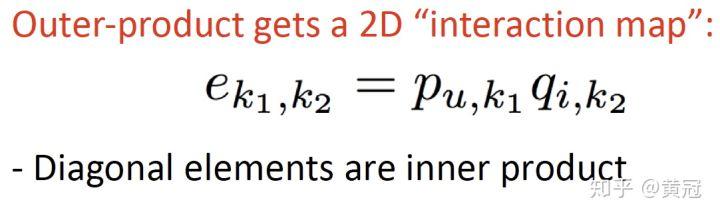
其中也包含了内积的结果。
然后就得到一个 mn 的矩阵,然后就可以接 MLP 学习他们的匹配分。但是由于 m*n 比较大,所以这样子是内存消耗比较大的:
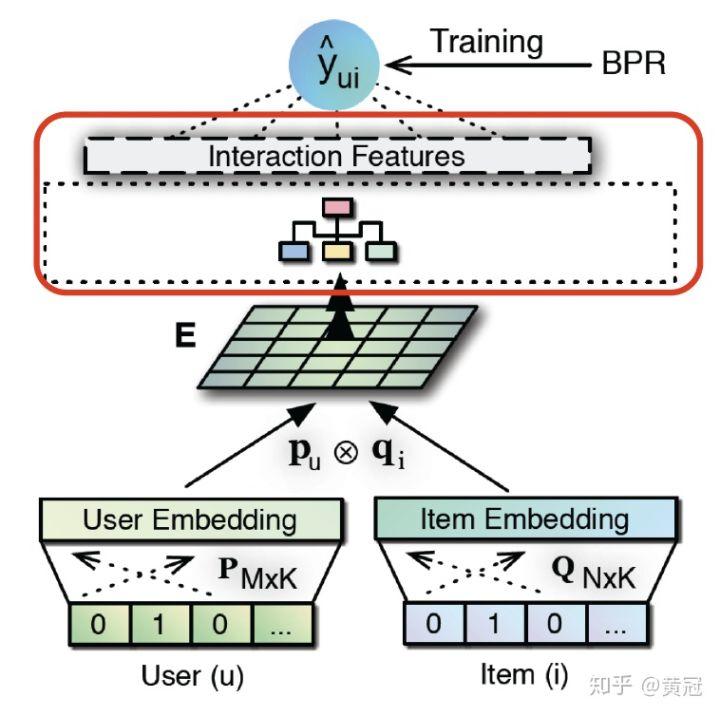
很自然的一个改进就是将全连接,改成局部全连接,这就是 CNN 了。
使用 CNN 来处理上述的 outer-product 的二维矩阵,可以起到大大节省内存的效果:
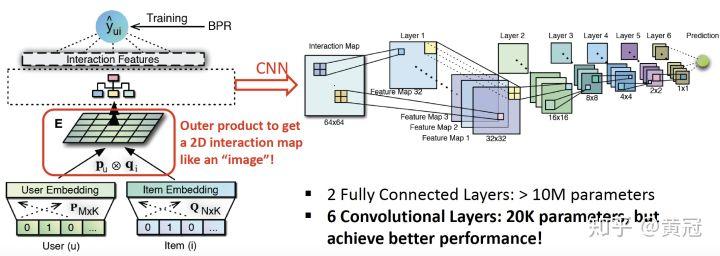
效果上,ConvNCF 要比 NeuMF 和 MLP 都要好:

part-3.2.2 基于 Translation 的一些方法介绍(matching function learning)
- Overview of Translation-based Models
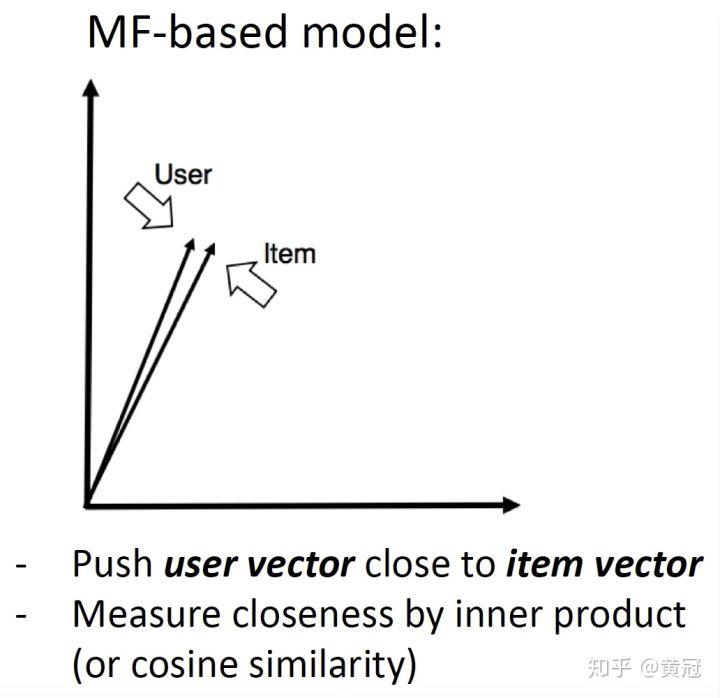
MF-based 的 model 是让 user 和他喜欢的 item 的向量更接近:
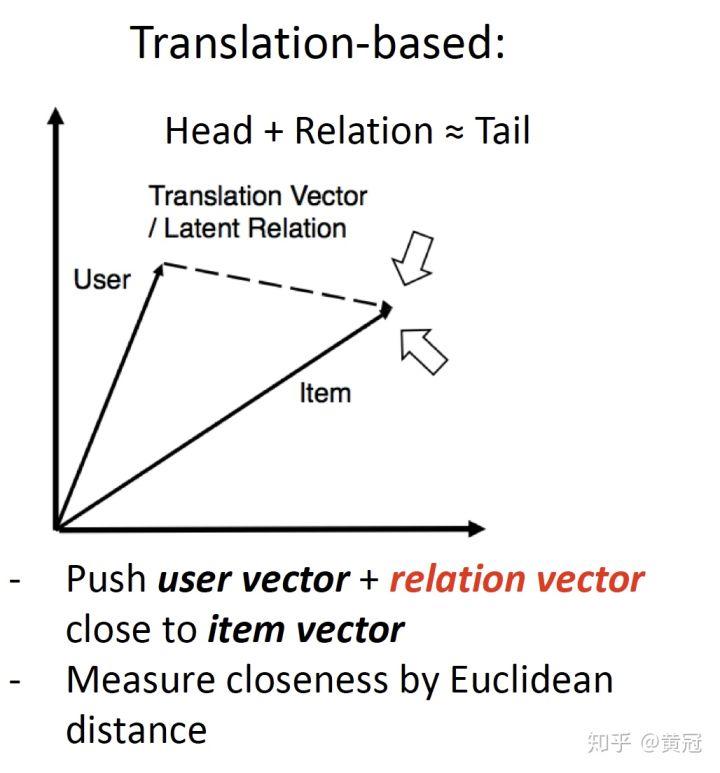
而 translation-based 的模型是,让用户的向量加上一个 relation vector 尽量接近 item 的向量:
- TransRec (He et al, Recsys’17):
这篇论文的主要思想是,item 是在一个 transition 空间中的,用户下一次会喜欢的 item 和他上一个喜欢的 item 有很大关系。
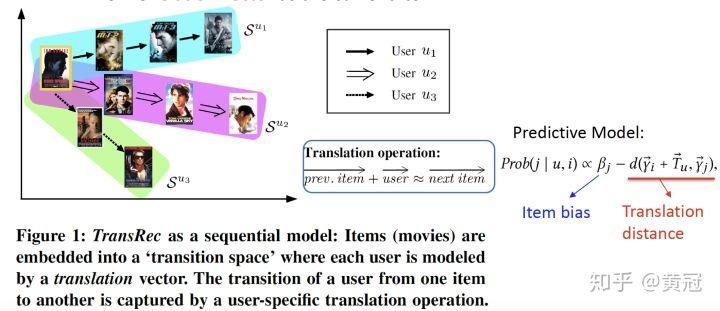
这篇论文要解决的下一个物品的推荐问题,利用三元关系组来解决这个问题:,主要的思想是:
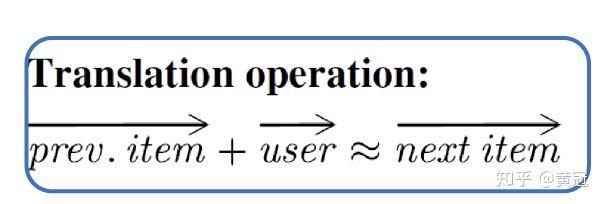
那么用户喜欢下一次物品的概率和下述式子成正比:
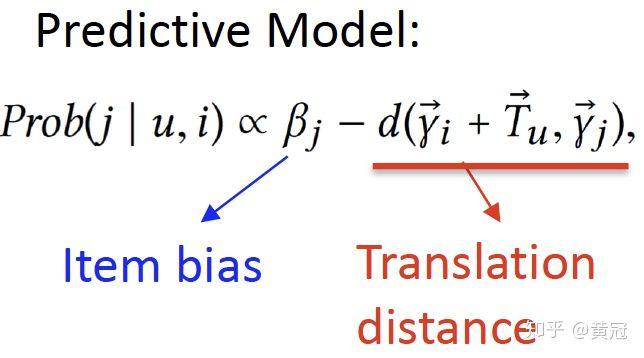
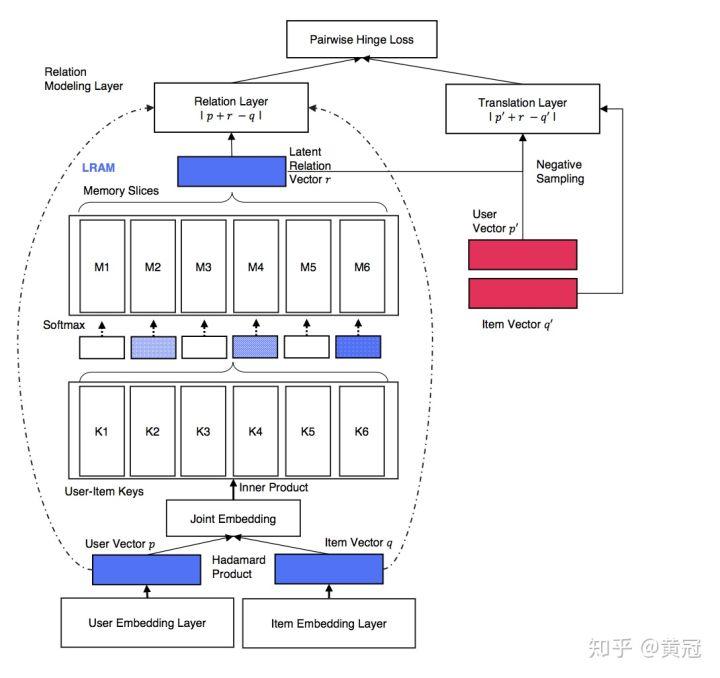
- Latent Relational Metric Learning(Tay et al, WWW’18)
这个论文主要是 relation vector 通过若干个 memory vector 的加权求和得到,然后采用 pairwise ranking 的方法来学习。
首先和 attention 里的 k、q、v 类似,计算出 attention weight:

其中 p 和 q 分别是 user 和 item 的向量。然后对 memory vector 进行加权求和得到 relation vector(该论文中用了 6 个 memory vector):
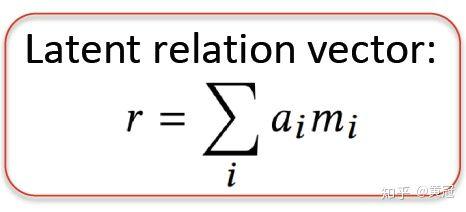
如果 item_q 是 user_p 喜欢的 item,那么随机采样另一对 p 和 q,就可以进行 pairwise ranking 的学习,即正样本的 |p+r-q|(p 喜欢 q)应该小于负样本的  (
(  ,这里的正负样本用同一个 r):
,这里的正负样本用同一个 r):
part-3.2.3 Feature-based 的一些方法介绍
推荐里的特征向量往往是高维稀疏的,例如 CF 中 feature vector = user_ID + item_ID。对于这些高维稀疏特征来说,抓取特征特征之间的组合关系非常关键:
-
二阶特征组合:
-
users like to use food delivery apps at meal-time
- app category 和 time 之间的二阶组合
-
三阶特征组合:
-
male teenagers like shooting games
- gender, age, 和 app category 之间的三阶组合
对于 feature-based 的方法来说,能抓取特征的交互作用和关系非常重要。
- Wide&Deep (Cheng et al, Recsys’16)
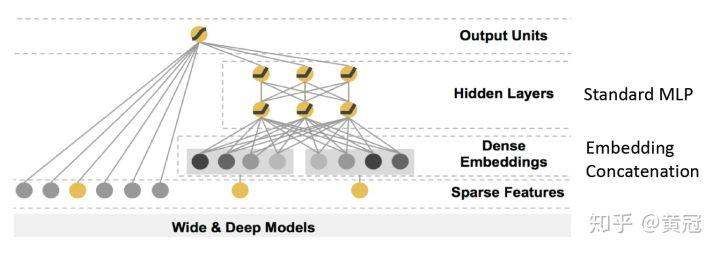
这个模型主要是将 LR 和 DNN 一起联合训练,注意是联合训练,一般的 ensemble 是两个模型是单独训练的。思想主要是:
- LR 擅长记忆;DNN 擅长泛化(包括抓取一些难以人工设计的交叉特征)
- LR 部分需要大量的人工设计的 feature,包括交叉特征
-
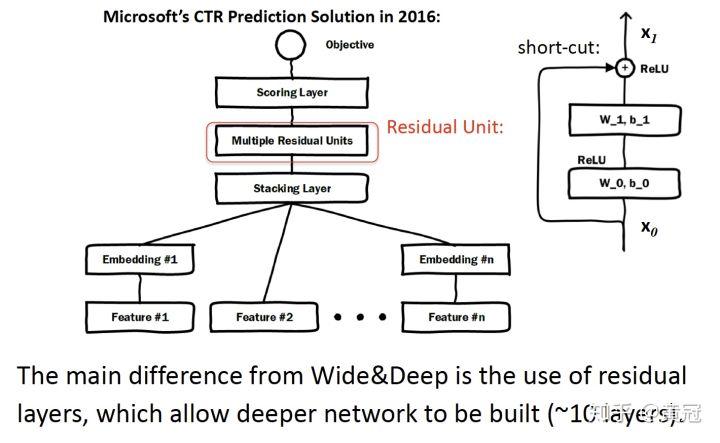
Deep Crossing (Shan et al, KDD’16)
这篇论文和 wide&deep 的主要差别是加了残差连接:
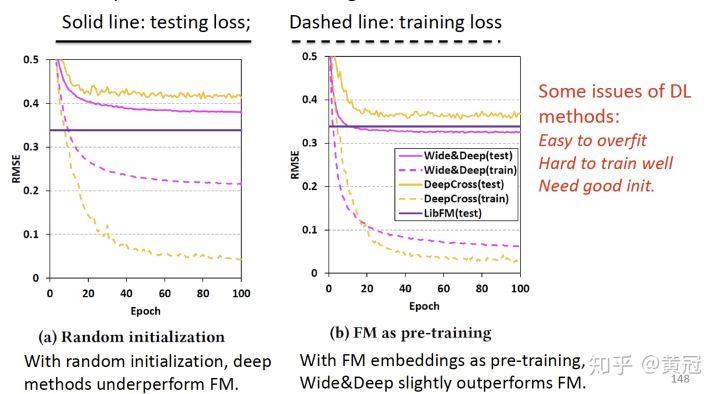
- Empirical Evidence (He and Chua, SIGIR’17):
这篇论文主要想说明两点:
- 如果只有 raw feature,如果没有人工设计的特征,DNN 效果并不够好
- 如果没有很好的初始化,DNN 可能连 FM 都打不过。如果用 FM 的隐向量来初始化 DNN,则 DNN 的效果比 FM 好
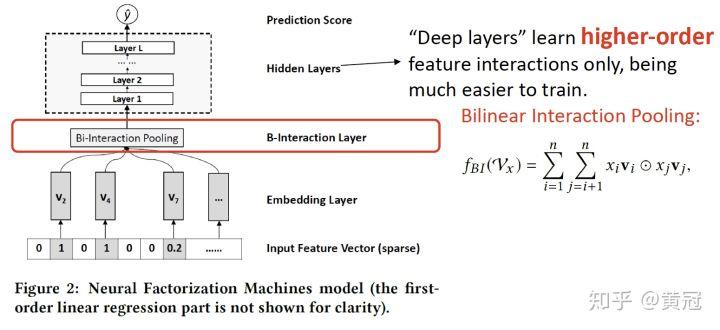
-
NFM: Neural Factorization Machine(He and Chua, SIGIR’17)
这个模型主要是,将 FM 里的二阶特征组合放到 NN 里,后面再接几层 FC 学习更高阶的特征组合。具体方法是:两两特征进行组合,即进行 element-wise dot,得到一个 K 维的向量,然后所有组合的 K 维向量进行加和,得到一个 K 维的向量,往后再接几个 FC,模型结构图如下:
效果上,该模型完爆了之前没有手工做特征组合的模型和 FM:
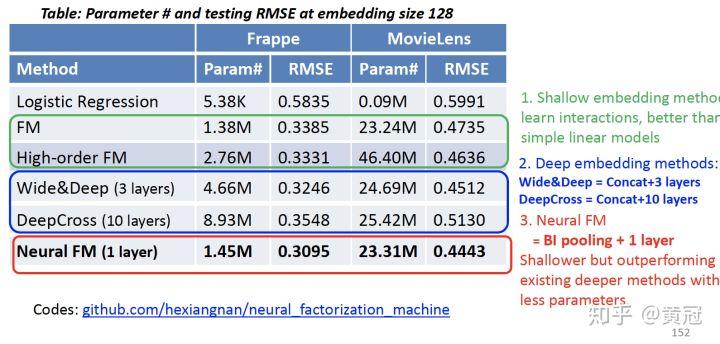
- AFM: Attentional Factorization Machine(Xiao et al, IJCAI’17):
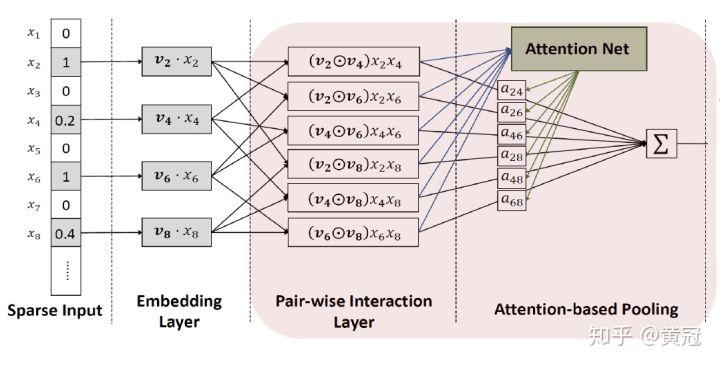
这个模型主要是针对 FM 的不同特征的组合的结果的简单加和,变成加权平均,用 attention 来求权重(有利于提取重要的组合特征;NFM 是使用 MLP 来学习不同特征组合的权重,且没有归一化的过程):
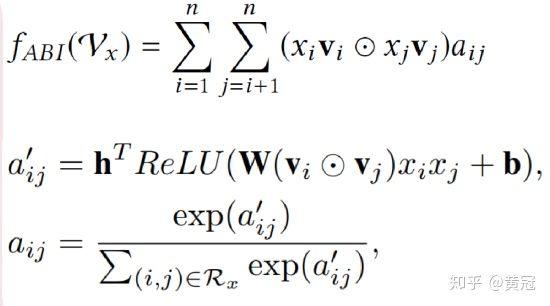
模型的整体结构图如下:
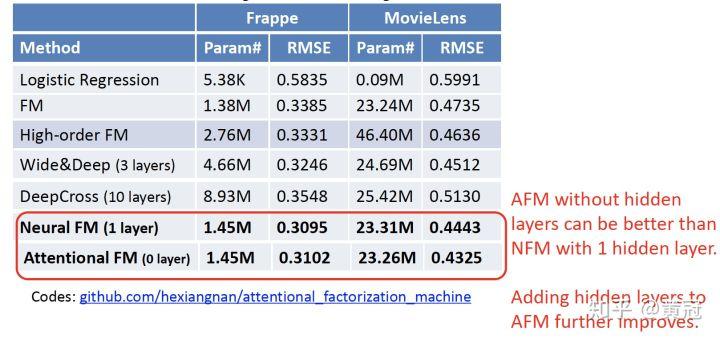
效果上,不带隐层的 AFM 就能干掉带一层隐层的 NFM。如果增加隐层,AFM 的效果能进一步提升:
- DeepFM (Guo et al., IJCAI’17):
这一篇论文主要是将 wide&deep 的 LR 替换成 FM,FM 可以抓取二阶的特征组合关系,而 DNN 可以抓取更高阶的特征组合关系:
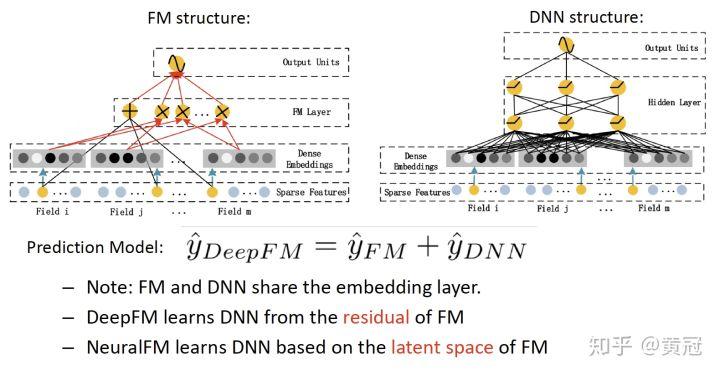
对上述的 feature-based 的方法做个简单总结:
- 特征交互对 matching function learning 非常关键
- 早期的对 raw feature 进行交叉,对效果提升非常有用:
-
wide&deep 是手工进行组合
- FM-based 的模型是自动进行组合
-
用 DNN 可以用来学习高阶的特征组合,但可解释性差。怎么学习可解释性好的高阶组合特征,依然是一个大的挑战。
part-3.3 Modern RecSys Architecture : representation learning 和 matching function learning 的融合
- Deep neural networks for youtube recommendations:
这一部分是我自己添加的,我觉得讲到推荐的话,这篇论文还是值得讲一讲的。这篇论文中有很多实践的干货,值得好好琢磨琢磨。
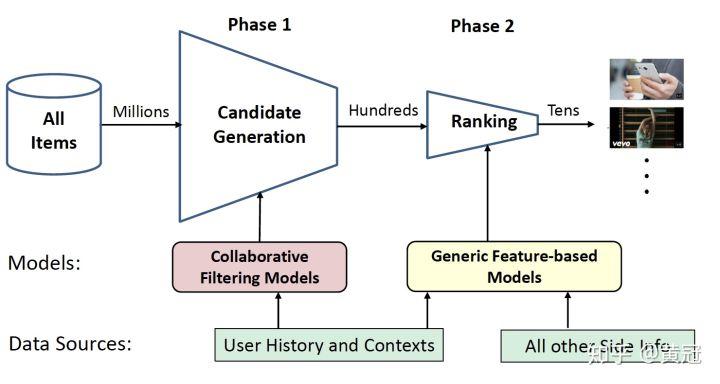
一个 top-n 推荐的系统一般也分两个排序阶段:
- 粗排:万里挑百
- 精排:百里挑十
整个推荐系统的架构图如下:
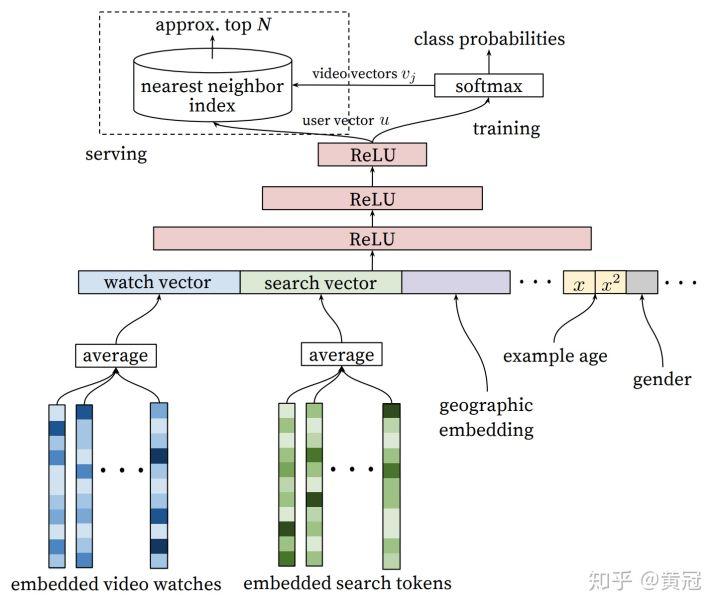
对于粗排模型:
采用分组全连接:
什么叫分组全连接呢?例如对特征分组,有两组特征是:1. 用户过去 14 天点击过的视频的 ID 2. 用户过去 3 天观看时间超过 2 分钟的视频的 ID,每一组特征内的 ID 的 embedding 加和,那每一组内都是一个全连接,每一组加和后都到一个定长的 K 维向量,如果有 N 组特征,就会一个定长的 N*K 维的特征,然后再接若干层 FC,就可以预测用户对该视频的偏好程度。分组全连接的思想,有点像 CNN 里的局部连接。上述的 Deep Matrix Factorization 是全连接,第一层全连接的参数可能很大。
那么这篇论文的粗排具体是怎么做的呢?主要是以下几点:
- 多分类,label=1 为用户看完的视频
- 输出层有 v 个节点,v 是 item 的集合大小
- 倒数第二层的输出表述 user 的 embedding
- 最后一层的权重表示每个 item 的 embedding
那么通过这个模型,user 和 item 的 embedding 都得到了,那么就可以用 CF 的方法,用内积计算出他们的匹配分,用来做粗排(召回)。所以上述的 tutorial 里的架构图才把粗排模型叫 Collaborative Filtering Models。
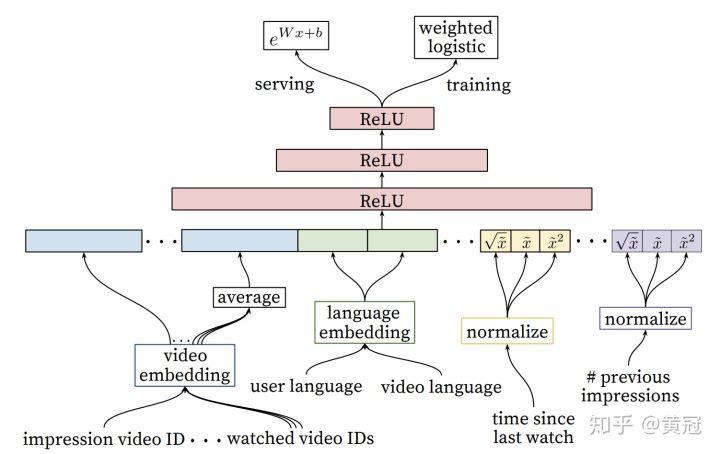
对于精排模型,也是使用分组全连接的模型:
part-4 short summary
这篇 tutorial 总算撸完了,收获非常大。总体上,个人感觉推荐的深度学习模型比搜索的、NLP 的要简单一点点。
总体上,不管是搜索还是推荐,匹配模型都主要分两大类:
- representation learning,这种方法重点是学习出要匹配的两个物品的表示。具体到推荐中,可以根据可以使用的信息,例如文本、图像、语音等,来确定到底是使用 auto-encoder、MLP、CNN 还是 RNN 等模型结构
- matching function learning,这种方法,在底层就进行匹配,然后用 NN 将基础的匹配信号进行融合,得到最后的匹配分。在推荐中,这种方法,想办法做一些特征组合非常重要。
另外,svd 的思想很强大,很多 nn 的模型都是借鉴 svd 来改进的;而 svd++ 又是 FM 的一个特例,FM 的威力也不可小觑。
参考链接:
https://www.comp.nus.edu.sg/~xiangnan/sigir18-deep.pdf
《搜索与推荐中的深度学习匹配》之搜索篇

时间:2019-01-08 00:00 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Attention!当推荐系统遇见注意力机制
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]万物皆可Graph | 当推荐系统遇上图神经网络
- [机器学习]ResNet、Faster RCNN、Mask RCNN是专利算法吗?盘点何恺
- [机器学习]YOLO算法最全综述:从YOLOv1到YOLOv5
- [机器学习]推荐系统架构与算法流程详解
- [机器学习]YOLO算法最全综述:从YOLOv1到YOLOv5
- [机器学习]贝尔实验室和周公“掰手腕”:AI算法解梦成为现
- [机器学习]性能超越GPU、FPGA,华人学者提出软件算法架构加
- [机器学习]GPT-3的威力,算法平台的阴谋
相关推荐:
网友评论:















