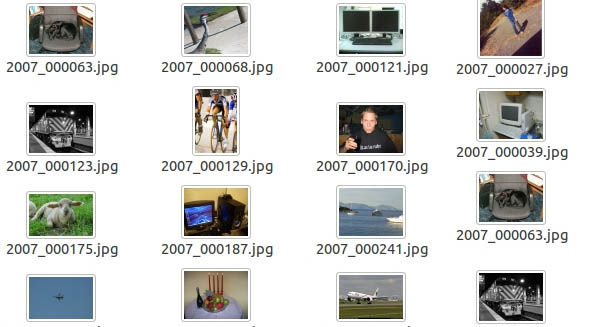
PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge。
本文主要分析PASCAL VOC数据集中和图像中物体识别相关的内容。
PASCAL VOC项目:
-
为对象类识别提供标准化图像数据集
-
提供用于访问数据集和注释的通用工具集
-
可以评估和比较不同的方法
-
Ran挑战评估对象类识别的性能(从2005年至2012年,现已完成)
Pascal VOC数据集
来自VOC挑战的数据集可通过以下挑战链接获得,并且可通过PASCAL VOC评估服务器评估这些数据集上的新方法 。即使挑战现已完成,评估服务器仍将保持活动状态。
本文来自织梦
下表简要概述了VOC开发的主要阶段。
本文来自织梦
|
年 |
统计 |
新发展 |
笔记 |
|
2005年 |
只有4个班:自行车,汽车,摩托车,人。训练/验证/测试:包含2209个带注释的对象的1578个图像。 |
两个比赛:分类和检测 |
图像主要来自现有的公共数据集,并不像随后使用的flickr图像那样具有挑战性。此数据集已过时。 |
|
2006年 |
10班:自行车,公共汽车,汽车,猫,牛,狗,马,摩托车,人,羊。训练/验证/测试:2618张图像,包含4754个带注释的对象。 |
来自flickr和Microsoft Research Cambridge(MSRC)数据集的图像 |
MSRC图像比flickr更容易,因为照片通常集中在感兴趣的对象上。此数据集已过时。 |
|
2007年 |
20课:
-
人:人
-
动物:鸟,猫,牛,狗,马,羊
-
车辆:飞机,自行车,船,公共汽车,汽车,摩托车,火车
-
室内:瓶子,椅子,餐桌,盆栽,沙发,电视/显示器
训练/验证/测试:9,963张图像,包含24,640个带注释的对象。 |
-
课程数量从10个增加到20个
-
细分分析师介绍
-
人物布局品尝师介绍
-
截断标志添加到注释中
-
分类挑战的评估指标变为平均精度。以前它是ROC-AUC。
|
今年建立了20个班级,从那时起就已经修好了。这是针对测试数据发布注释的最后一年。 |
|
2008年 |
20课。数据被分开(像往常一样)约50%列车/值和50%测试。train / val数据有4,340个图像,包含10,363个带注释的对象。 |
-
遮挡标志添加到注释中
-
测试数据注释不再公开。
-
分段和人物布局数据集包括来自相应VOC2007集的图像。
|
|
|
2009年 |
20课。列车/瓦尔数据有7,054张图像,包含17,218个ROI注释对象和3,211个分段。 |
-
从现在开始,所有任务的数据都包含前几年用新图像增强的图像。在早些年,每年都会发布一个全新的数据集,用于分类/检测任务。
-
增强允许每年增加图像的数量,并且意味着可以在前几年的图像上比较测试结果。
-
细分成为标准挑战(从品酒师提升)
|
-
没有为附加图像提供困难的标志(遗漏)。
-
测试数据注释未公开。
|
|
2010 |
20课。train / val数据有10,103个图像,包含23,374个ROI注释对象和4,203个分段。 |
-
行动分类品尝师介绍。
-
基于ImageNet引入的大规模分类的相关挑战。
-
亚马逊机械土耳其人用于注释的早期阶段。
|
-
计算AP的方法发生了变化。现在使用所有数据点而不是TREC样式采样。
-
测试数据注释未公开。
|
|
2011 |
20课。train / val数据有11,530个图像,包含27,450个ROI注释对象和5,034个分段。 |
|
-
布局注释现在不是“完整的”:只有人注释,有些人可能没有注释。
|
|
2012 |
20课。列车/瓦尔数据有11,530张图像,包含27,450个ROI注释对象和6,929个分段。 |
-
分割数据集的大小显着增加。
-
行动分类数据集中的人员还附加了身体上的参考点。
|
-
用于分类,检测和人员布局的数据集与VOC2011相同。
|
主办单位
-
Mark Everingham(利兹大学)
-
Luc van Gool(苏黎世ETHZ)
-
克里斯威廉姆斯(爱丁堡大学)
-
John Winn(微软剑桥研究院)
-
Andrew Zisserman(牛津大学)
主要贡献来自 织梦内容管理系统
-
Yusuf Aytar(牛津大学)
-
Ali Eslami(微软剑桥研究院)
-
Alexander Sorokin(伊利诺伊大学厄巴纳 - 香槟分校)