




数据挖掘
-
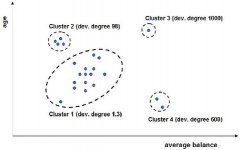
数据挖掘十大经典算法
不仅仅是选中的十大算法,其实参加评选的18种算法,实际上随便拿出一种来都可以称得上是经典算法,它们在数据挖掘领域都产生了极为深...
2018-10-04 22:25:12 -

数据挖掘常用的方法
在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的大型数据库中发现隐含在其中有...
2018-10-04 22:22:08 -

TO数据挖掘新入行的朋友,你问我答
IDMer:本帖中包含了数据挖掘初学者常见的问题,DMFighter对我以前回复的一些问题进行了精心的整理,在此也感谢他的辛勤工作。本文内容涵...
2018-10-04 22:21:22 -

数据挖掘与数据建模的9条定律
数据挖掘是利用业务知识从数据中发现和解释知识(或称为模式)的过程,这种知识是以自然或者人工形式创造的新知识。 当前的数据挖掘...
2018-10-04 22:16:29 -

数据分析挖掘体系
...
2018-10-04 22:15:43 -
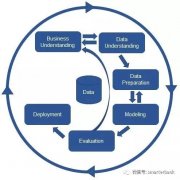
干货:数据挖掘方法论与工程化思考
数据挖掘的标准流程 CRISP-DM(cross-industry standard process for data mining),即为跨行业数据挖掘标准流程。近年来CRISP-DM 在各种KDD过程模型中占据领先...
2018-10-04 22:12:46 -

以“小”博大,小程序的C位出道记
自2017年1月9日微信小程序正式发布算起,仅一年多的时间,小程序已经生长出一个相对完整的生态,通过底层技术与微信流量入口双管齐下...
2018-09-30 23:56:53 -

超越Spark,大数据集群计算的生产实践
本文会介绍 Spark 核心社区开发的生态系统库,以及 ML MLlib 及 Spark Streaming 的 Spark 库的具体用法,对于企业的各种用例及框架也进行了说明。...
2018-09-30 17:32:12 -

Spark Streaming 技术点汇总
Spark Streaming 支持实时数据流的可扩展(Scalable)、高吞吐(high-throughput)、容错(fault-tolerant)的流处理(stream processing)。...
2018-09-27 23:35:10 -

SparkSQL大数据实战:揭开Join的神秘面纱
Join是数据库查询永远绕不开的话题,传统查询SQL技术总体可以分为简单操作(过滤操作-where、排序操作-limit等),聚合操作-groupby以及Join操作...
2018-09-27 23:34:56 -

如何用Python编写你最喜欢的R函数?
本文介绍了采用创建一个Python脚本,用该脚本模仿R风格的函数的方法来方便地进行统计。是用R语言还是用Python语言?这是一个旷日持久的争...
2018-09-26 13:28:40 -

小议Lambda与Kappa架构,不可变数据的计算探索
Lambda架构说起来也很简单,就是通过分布式系统的组件搭建,设计出一个具有鲁棒性,可扩展,低延时的分布式计算系统。之所以称之为L...
2018-09-25 16:23:38 -

聚类分析的算法划分
聚类分析的算法可以分为划分的方法、层次的方法、基于密度的方法、基于网络的方法、基于模型的方法等,其中,前面两种方法最为常用...
2018-09-25 16:23:01 -

2018年最值得推荐的6款大数据挖掘工具
数据肯定是无价的。但分析数据并非易事,因为结果越准确,成本就越高。鉴于数据急剧增长,需要一个过程来提供有意义的信息,最终变...
2018-09-25 16:21:18 -

腾讯QQ大数据:聚类算法如何应用在营收业务中—
导语同一催费场景,挖掘人群特点,不同人群触达不同文案与图片提升转化 背景 尊敬的XXX用户,您的话费已不足10元。为了您的正常使用,...
2018-09-25 00:24:37 -

Hadoop推动现代数据仓库技术的深刻变革
...
2018-09-25 00:22:45 -

领英开源TonY:构建在Hadoop YARN上的TensorFlow框架
本文介绍了 TonY 的内部细节、领英实现并用来在 Hadoop 上扩展分布式 TensorFlow 的功能以及实验结果。...
2018-09-21 13:07:50 -

MapReuce中对大数据处理最合适的数据格式是什么?
本节作为《Hadoop从入门到精通》大型专题的第三章第二节将教大家如何在Mapreduce中使用XML和JSON两大常见格式,并分析比较最适合Mapreduce大数...
2018-09-21 00:27:02 -

数据挖掘领域十大经典算法之—CART算法(附代码
CART与C4 5类似,是决策树算法的一种。此外,常见的决策树算法还有ID3,这三者的不同之处在于特征的划分:...
2018-09-21 00:26:56 -

Hadoop发行版本之间的区别
商业发行版主要是提供了更为专业的技术支持,这对于大型企业更为重要,不同发行版都有自己的一些特点,本文就各发行版做简单对比介...
2018-09-21 00:26:49 -

Hadoop体系结构中的服务解决介绍
要在集群中运行DKHadoop服务,需要指定集群中的一个或多个节点执行该服务的特定功能,角色分配是必须的,没有角色集群将无法正常工作,...
2018-09-21 00:26:41 -
数据挖掘领域十大经典算法之—朴素贝叶斯算法
NaïveBayes算法,又叫朴素贝叶斯算法,朴素:特征条件独立;贝叶斯:基于贝叶斯定理。属于监督学习的生成模型,实现简单,没有迭代,并...
2018-09-21 00:26:25 -

数据挖掘领域十大经典算法之—K-邻近算法/kNN(
又叫K-邻近算法,是监督学习中的一种分类算法。目的是根据已知类别的样本点集求出待分类的数据点类别。...
2018-09-21 00:26:16 -

Apache HBase 问题排查思路
本文来自于中国 HBase 技术社区在杭州举办的第三次 HBase Meetup 会议,第四次 HBase Meetup 会议将于本周六(2018-09-08)在上海举办。...
2018-09-21 00:25:59 -

数据挖掘领域十大经典算法之—AdaBoost算法(附代
Adaboost算法是一种提升方法,将多个弱分类器,组合成强分类器。AdaBoost,是英文”Adaptive Boosting“(自适应增强)的缩写,由Yoav Freund和Robert...
2018-09-21 00:25:52 -

TF Learn : 基于Scikit-learn和TensorFlow的深度学习利器
了解国外数据科学市场的人都知道,2017年海外数据科学最常用的三项技术是 Spark ,Python 和 MongoDB 。说到 Python ,做大数据的人都不会对 S...
2018-09-21 00:25:44 -

数据挖掘领域十大经典算法之—PageRank算法
Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。...
2018-09-21 00:25:33 -

如何使用HBase?大数据存储的两个实战场景
现如今各种数据存储方案层出不穷,本文仅仅是结合两个实战场景就基于HBase的大数据存储做了简单的分析,并对HBase的原理做了简单的阐述...
2018-09-21 00:25:22 -

数据挖掘领域十大经典算法之—EM算法
例子是说测量校园里面同学的身高分布,分为男生和女生,分别抽取100个人…具体的不细讲了,参考文档中讲得很详细。...
2018-09-21 00:25:14 -

如何衔接Spark 和Tensorflow?
我们知道,Spark 目前是大数据处理组件的王者,实现了让大数据处理更轻松的远景。Tensorflow则是深度学习当之无愧最热的框架。...
2018-09-21 00:24:56 -

kNN算法——帮你找到身边最相近的人
本文将使用学生社团来解释k-NN算法的一些概念,该算法可以说是最简单的机器学习算法,构建的模型仅包含存储的训练数据集。...
2018-09-21 00:24:48 -

数据挖掘领域十大经典算法之—Apriori算法
先验算法(Apriori Algorithm)是关联规则学习的经典算法之一。先验算法的设计目的是为了处理包含交易信息内容的数据库(例如,顾客购买的商品...
2018-09-21 00:24:41 -

Apache Kafka在大型应用中的20项最佳实践
Apache Kafka是一款流行的分布式数据流平台,它已经广泛地被诸如New Relic(数据智能平台)、Uber、Square(移动支付公司)等大型公司用来构建可扩展...
2018-09-21 00:24:34 -

整合AI和数据科学新利器:基于Apache Spark的Hydro
下面我们来看看 Reynold Xin 的六大问答,涵盖了从 Hydrogen 项目如何帮助开发者在 Spark 实现机器学习和人工智能框架,到该项目与其他开源项...
2018-09-21 00:24:26 -

数据挖掘领域十大经典算法之—SVM算法
SVM(Support Vector Machine)中文名为支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、...
2018-09-21 00:24:17






