




数据挖掘
-

Spark之性能优化(重点:并行流数据接收)
在Spark中有几个优化可以减少批处理的时间。这些可以在优化指南中作了讨论。这节重点讨论几个重要的。...
2018-10-09 22:35:06 -

HBase最佳实践 – Scan用法
HBase从用法的角度来讲其实乏陈可善,所有更新插入删除基本一两个API就可以搞定,要说稍微有点复杂的话,Scan的用法可能会多一些说头。...
2018-10-09 22:35:06 -

搭建Hadoop大数据处理-环境
由于hadoop需要运行在Linux环境中,而且是分布式的,因此个人学习只能装虚拟机,本文都以VMware Workstation为准,安装CentOS7,具体的安装此处...
2018-10-09 22:35:06 -

零基础学习大数据,搭建Hadoop处理环境
由于Hadoop需要运行在Linux环境中,而且是分布式的,因此个人学习只能装虚拟机,本文都以VMware Workstation为准,安装CentOS7,具体的安装此处...
2018-10-09 22:35:06 -

Hadoop3.0: YARN Resource自定义资源配置说明
yarn支持可扩展资源类型 所有节点、应用程序、队列,默认情况下Yarn使用 CPU和内存。资源定义可以扩展为任意的“countable”资源。一个cou...
2018-10-09 22:35:06 -

Hadoop fs常用命令
hadoop fs –ls :等同于本地系统的ls,列出在指定目录下的文件内容,支持pattern匹配。输出格式如filename(full path) size 其中n代表replica的个数,...
2018-10-09 22:35:06 -

hadoop3.0 Yarn支持网络1:network设计文档说明
问题导读1 网络作为Yarn的资源,有什么好处?2 Yarn是否只支持调度和强制执行传出流量?3 Yarn是否支持入口流量?开始在学习之前,其实需要一...
2018-10-09 22:35:06 -

hadoop3.0 Yarn支持网络资源2:network设计文档说明
1 本文讲了哪些配置项?2 DistributedShell是否可以让用户指定网络带宽?3 hadoop3 0网络设计存在哪些已知的问题?...
2018-10-09 22:35:06 -

hadoop3.0扩展Yarn资源模型详解1
1 countable资源是指哪些?2 noncountable资源,本文列举了什么资源?3 标签是否为资源?4 如何实现扩展YARN资源模型?...
2018-10-09 22:35:06 -

hadoop3.0扩展Yarn资源模型详解2:资源Profiles说明
由于YARN添加了对其他资源类型的支持,指定和配置Container的资源分配变得越来越麻烦。 我们建议resource-profiles作为一个解决方案,允许用户...
2018-10-09 22:35:06 -

基于Hadoop生态SparkStreaming的大数据实时流处理平台
随着公司业务发展,对大数据的获取和实时处理的要求就会越来越高,日志处理、用户行为分析、场景业务分析等等,传统的写日志方式根...
2018-10-09 22:35:06 -

Hadoop3 YARN集群中的磁盘I / O调度设计详解1
已经研究了Hadoop YARN中的资源共享和隔离技术实现了CPU和内存等资源。 任务(或容器)可以限制CPU核心的数量和允许使用的内存。 但是,YARN不...
2018-10-09 22:35:06 -

朱诗雄:Apache Spark中的全新流式引擎Structured St
Apache Spark在2016年的时候启动了Structured Streaming项目,一个基于Spark SQL的全新流计算引擎Structured Streaming,让用户像编写批处理程序一样简单地...
2018-10-09 22:35:06 -

细数10个隐藏在Python中的彩蛋
import this 中隐藏了一首《Python之禅》的诗,它是Python中的『八荣八耻』,作者是 Tim Peters ,每个有追求的Python程序员都应该谨记于心。...
2018-10-09 22:35:06 -

自建hadoop集群迁移到EMR之数据迁移篇
自建集群要迁移到EMR集群,往往需要迁移已有数据。本文主要介绍hdfs数据和hive meta数据如何迁移。...
2018-10-09 22:35:06 -

Apache Spark中的决策树
Apache Spark中没有决策树的实现可能听起来很奇怪。然而从技术上来说是有的。在Apache Spark中,您可以找到一个随机森林算法的实现,该算法...
2018-10-09 22:35:06 -

使用Jupyter Notebook 加速PySpark开发
目前我们系统的整体架构大概是: Spark Standalone Cluster + NFS FileServer 自然, 这些都是基于Linux系统...
2018-10-09 22:35:06 -

如何在Python中用scikit-learn生成测试数据集
测试数据集是小型的专用数据集,它可以让你测试一个机器学习算法或测试工具。数据集中的数据有完整的定义(例如线性或非线性)使你可以...
2018-10-09 22:35:06 -

一个Spark缓存的使用示例
之前一直不是非常理解Spark的缓存应该如何使用 今天在使用的时候, 为了提高性能, 尝试使用了一下Cache, 并收到了明显的效果...
2018-10-09 22:35:06 -

如何使用 scikit-learn 为机器学习准备文本数据
文本数据需要特殊处理,然后才能开始将其用于预测建模。我们需要解析文本,以删除被称为标记化的单词。然后,这些词还需要被编码为...
2018-10-09 22:35:06 -

HBase跨版本数据迁移总结
某客户大数据测试场景为:Solr类似画像的数据查出用户标签——通过这些标签在HBase查询详细信息。以上测试功能以及性能。...
2018-10-09 22:35:06 -

手把手教你Spark性能调优
上周四接到反馈,集群部分 spark 任务执行很慢,且经常出错,参数改来改去怎么都无法优化其性能和解决频繁随机报错的问题。...
2018-10-09 22:35:06 -

Apache Spark 2.3 重要特性介绍
为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2 3 在许多模块都做了重要的更新,比如 Structured Streaming 引入了低延迟的连续处理(...
2018-10-09 22:35:06 -

NumPy能力大评估:这里有70道测试题
本 NumPy 测试题旨在为大家提供参考,让大家可以使用 NumPy 的更多功能。问题共分为四个等级,L1 最简单,难度依次增加。机本文对该测试题...
2018-10-09 22:35:06 -

kafka架构与原理
它可以让你发布和订阅记录流。在这方面,它类似于一个消息队列或企业消息系统。它可以让你持久化收到的记录流,从而具有容错能力。...
2018-10-09 22:35:06 -

Spark核心技术原理透视--Spark运行模式
通过Spark运行原理的讲解大家了解了Spark在底层的运行,那Spark的运行模式又是什么样的呢?通过本文以下的讲解大家可以详细的学习了解。...
2018-10-09 22:31:08 -

python开发环境搭建
虽然网上有很多python开发环境搭建的文章,不过重复造轮子还是要的,记录一下过程,方便自己以后配置,也方便正在学习中的同事配置他...
2018-10-09 22:31:08 -

从扩线查询能力分析分布式图数据库Titan的设计改
本文先简单介绍了图数据库的发展趋势,而后重点介绍了分布式图数据库Titan,围绕图数据库的典型查询(扩线查询)场景,分析了Titan在设计...
2018-10-09 22:31:08 -

Sqoop数据导入到HBase遇上的问题及解决方法
将 tmp sqoop-hadoop compile 文件夹下的 detects jar包 放到sqoop安装目录lib下。重新执行即可。确实重新运行好了...
2018-10-09 22:31:08 -

如何在Python中从零开始实现随机森林
随机森林是套袋(方法)的延伸,除了基于多个测试数据样本构建树木之外,它还限制了可用于构建树木的特征,使得树木间具有差异。这反过...
2018-10-09 22:31:08 -
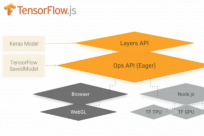
TensorFlow发布面向JavaScript开发者的机器学习框架
据介绍,在过去的两年中,TensorFlow 不断更新,不断改善,逐渐成为社区内最为流行的深度学习框架。下图是从开源以来,TensorFlow 的重大更...
2018-10-09 22:31:08 -

Apache Spark统一内存管理模型详解
本文将对 Spark 的内存管理模型进行分析,下面的分析全部是基于 Apache Spark 2 2 1 进行的。为了让下面的文章看起来不枯燥,我不打算贴出代...
2018-10-09 22:31:08 -

Hadoop中理论与工程的错位
Hadoop是当前重要的大数据计算平台,它试图摒弃传统数据库的理念,重新构建一套新的大数据体系。但是,这并不是件很容易的事,在Hado...
2018-10-09 22:31:08 -

54个大数据hadoop面试经典题
参考下面的M R系统的场景:HDFS 块大小为64MB;输入类型为FileInputFormat;有三个文件大小分别是:...
2018-10-09 22:31:08 -

Apache Hadoop 3.1.0 正式发布,原生支持GPU和FPGA
4月6日,Apache Hadoop 3 1 0 正式发布了,Apache Hadoop 3 1 0 是2018年 Hadoop-3 x 系列的第一个小版本,并且带来了许多增强功能。不过需要注意的是,...
2018-10-09 22:31:08






