




数据挖掘
-

用Python实现了一个大数据数据搜索引擎
搜索是大数据领域里常见的需求。Splunk和ELK分别是该领域在非开源和开源领域里的领导者。本文利用很少的Python代码实现了一个基本的数据...
2018-10-09 22:41:15 -

Spark作业如何在无管理权限的集群部署Python或JD
在现实情况下,我们需要的 JDK 版本可能并没有在集群上安装,这个时候咋办?是不是就没办法呢?答案肯定不是,本文就是介绍如何解决这种...
2018-10-09 22:41:15 -

hadoop(04)、Hadoop 集群模式搭建实践
本文我们将在linux(CentOS7)下搭建hadoop集群模式,以便实践更多场景下hadoop的使用,尤其是在实际的生产模式中,必定是以集群模式存在。...
2018-10-09 22:41:15 -

浅析:spark认知
Spark是一种基于内存的开源计算框架,不同于Hadoop的MapReduce和HDFS,Spark主要包括Spark Core和在Spark Core基础之上建立的应用框架Spark SQL、Spark ...
2018-10-09 22:41:15 -

教你玩转Hadoop分布式集群搭建,进击大数据
终于要开始玩大数据了,之前对haoop生态几乎没有太多的了解,现在赶鸭子上架,需要完全使用它来做数据中心,这是我的haoop第一篇文章,...
2018-10-09 22:41:15 -

在数据预处理阶段,特征的标准化有哪些方法?
特征标准化(Feature Standardization)的作用是将样本数据中的每一列特征缩放到一个统一的尺度。方法有很多种,我列几个最常用的。...
2018-10-09 22:41:15 -

17个新手常见Python运行时错误
当初学 Python 时,想要弄懂 Python 的错误信息的含义可能有点复杂。这里列出了常见的的一些让你程序 crash 的运行时错误。...
2018-10-09 22:41:15 -

Hbase万亿级存储性能优化总结
hbase主集群在生产环境已稳定运行有1年半时间,最大的单表region数已达7200多个,每天新增入库量就有百亿条,对hbase的认识经历了懵懂到熟...
2018-10-09 22:41:15 -

用 Python 连接 MySQL 的几种姿势
尽管很多 NoSQL 数据库近几年大放异彩,但是像 MySQL 这样的关系型数据库依然是互联网的主流数据库之一,每个学 Python 的都有必要学好一门...
2018-10-09 22:41:15 -

数据结构的定义和简介
我们如何把现实中大量而复杂的问题以特定的数据类型和特定的存储结构保存到主存储器(内存)中,以及在此基础上为实现某个功能(如元素的...
2018-10-09 22:41:15 -

大数据批处理框架 Spring Batch全面解析
如今微服务架构讨论的如火如荼。但在企业架构里除了大量的OLTP交易外,还存在海量的批处理交易。在诸如银行的金融机构中,每天有3-4万...
2018-10-09 22:38:18 -

扼杀性能的10个常见Hibernate错误
我在很多应用程序中修复过性能问题,其中大部分都是由同样的错误引起的。修复之后,性能变得更溜,而且其中的大部分问题都很简单。...
2018-10-09 22:38:18 -

hadoop|计算框架从MapReduce1.0到Yarn
知道海量数据如何存储后,脚步不能停留,下一步要设计一个框架,用来玩(计算)这些数据时,资源(计算机集群)该如何调度,比如已知1PB的...
2018-10-09 22:38:18 -

数据专家必知必会的7款Python工具
如果你有志于做一个数据专家,你就应该保持一颗好奇心,总是不断探索,学习,问各种问题。在线入门教程和视频教程能帮你走出第一步...
2018-10-09 22:38:18 -

你试过C语言和Python一起混合编程吗?两者相加不
C语言是编程语言的祖母,但是随着一代一代的编程语言长大,所以祖母也是会拍在沙滩上的,很多小小伙伴应该都会学过或者了解C语言,因...
2018-10-09 22:38:17 -

Lua 和 Python 相比,哪种语言更快更好
网上经常看到别人拿lua与python来进行对比,但是,本人认为,lua与python根本就不具有可比性 原因如下:...
2018-10-09 22:38:17 -

Python基础语法-常量与变量
Python是一门强类型的动态语言。 字面常量,变量没有类型,变量只是在特定的时间指向特定的对象而已,变量所指向的对象是有类型的。...
2018-10-09 22:38:17 -

大数据学习(1)Hadoop安装
hadoop的安装其实就是HDFS和YARN集群的配置,从下面的架构图可以看出,HDFS的每一个DataNode都需要配置NameNode的位置。同理YARN中的每一个NodeM...
2018-10-09 22:38:17 -

基于概率论的分类算法-朴素贝叶斯(Naive Bayes)
概率论是许多机器学习算法的基础,理解并使用概率论就显得十分重要。本文给出一个使用概率论分类的方法 - 朴树贝叶斯,并写出一个最...
2018-10-09 22:38:17 -

从源码看Spark读取Hive表数据小文件和分块的问题
使用Spark进行数据分析和计算早已成趋势,你是否关注过读取一张Hive表时Task数为什么是那么多呢?它跟什么有关系呢? 最近刚好碰到这个问题...
2018-10-09 22:38:17 -

安装Spark(完全分布式部署--Standalone)
1 将Spark解压并上传至 opt目录下,tar -zxvf spark-1 6 2-bin-hadoop2 6 tgz -C opt...
2018-10-09 22:38:17 -

Keras之父:大多数深度学习论文都是垃圾,炒作
近日,François Chollet接受了采访,就“深度学习到底是什么”、“Python为何如此广受欢迎”、“目前深度学习面临的主要挑战”等议题进行了...
2018-10-09 22:38:17 -

编译hadoop2.9源码并搭建环境
因为以前安装hadoop编译版的时候遇到过问题,时间比较久了,具体问题有些描述不清了,建议大家下载源码自己编译安装,如果遇到bug自己...
2018-10-09 22:38:17 -
Spark 的transformation和action操作
下图描述了Spark在运行转换中通过算子对RDD进行转换。 算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作。...
2018-10-09 22:38:17 -

Spark RDD简介及RDD在Spark中的地位
Spark的核心概念是RDD (resilient distributed dataset),指的是一个 只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在...
2018-10-09 22:38:17 -

python 小技巧(python tricks)
不积跬步无以至千里,人生苦短,我用Python,Life is short, use Python...
2018-10-09 22:38:17 -

Spark运行原理架构图(手绘)
Spark运行原理架构图(手绘);Spark-wc(word count)运行架构原理图(纯手绘);masterHA切换机制(手绘);sparkContext的构建的过程(手绘)...
2018-10-09 22:38:17 -

Hadoop和Spark之间有什么区别,现工业界都在使用何
谈到大数据,相信大家对hadoop和Apache Spark这两个名字并不陌生。然而,最近业界有一些人正在大张旗鼓的宣扬Hadoop将死,Spark将立。...
2018-10-09 22:38:17 -

Python学习之Anaconda的使用及配置方法
下面简单的介绍下anaconda,它是将Python版本和许多常用的package打包直接来使用的Python发行版,支持linux、mac、windows系统,并有一个conda强大的...
2018-10-09 22:38:17 -

构建基于Spark的推荐引擎(Python)
在学习Spark机器学习时,书上用scala完成,自己不熟悉遂用pyshark完成,更深入的理解了spark对协同过滤的实现...
2018-10-09 22:38:17 -

Python列表(list)详解
Python内置的一种数据类型是列表(list),list是一种有序的集合,可以随时添加和删除其中的元素,列表中的每个元素都分配一个数字,是它的...
2018-10-09 22:38:17 -

深入理解Python装饰器
Python是一门追求优雅编程的语言,它很容易上手,也很容易写出意大利式的代码。本文将介绍如何使用Python进阶编程之装饰器,来帮助您写...
2018-10-09 22:38:17 -

Hadoop3.0集群安装知识
本文档介绍如何安装和配置Hadoop集群,从少数节点到数千个节点的超大型集群。...
2018-10-09 22:38:17 -

数据挖掘:关联规则Apriori算法
总结了关联规则挖掘的经典算法Apriori算法,这个算法利用了一个定律:如果一个集合不是频繁项集,则它的所有超集都不是频繁项集,自下...
2018-10-09 22:38:17 -
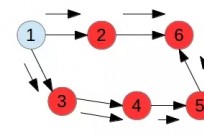
Spark:有向无环图(DAG)检测
Spark 是一种与 Hadoop 相似的开源集群计算环境,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,...
2018-10-09 22:38:17






