搜索引擎倒排索引的设计与实践
|
|
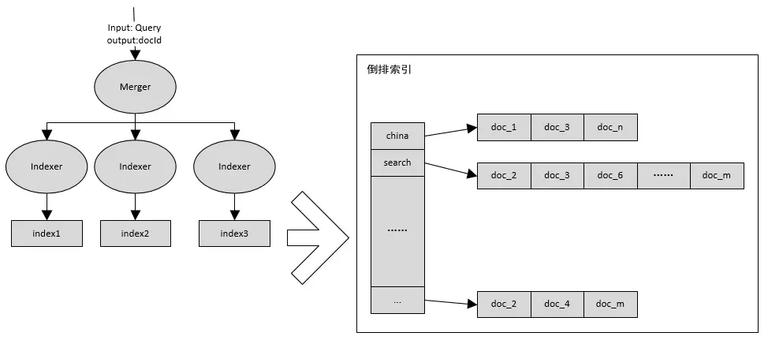
搜索引擎如何工作?信息检索已经发展的非常成熟了,应该所有人都不陌生。我有幸这几年接触过并且实际做过一些搜索引擎开发的工作,特此总结并分享给大家。实际上,一个成熟的搜索引擎是想当复杂的,比如百度的,就分 nginx,vui,us,as,bs,da….. 等等这些模块,当然这些简写的字母大家也不必了解,只要知道它确实复杂就可以。 今天我所讲的是一个简化版的搜索引擎,简化到只涉及到倒排建立和拉取。虽然简单,但是它是整个搜索引擎的最核心组件。一个最简单的搜索引擎如下图所示:
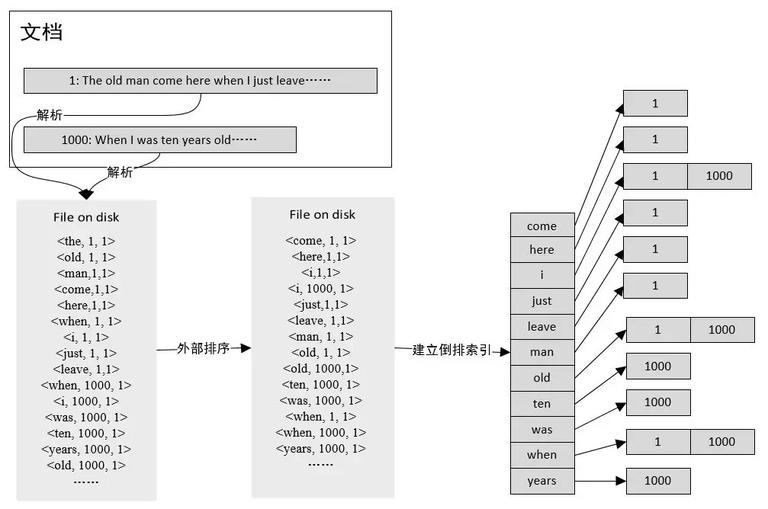
倒排索引长成什么样子呢?就是图中标记的那样,每个词后面有一个拉链,拉链中存放包含该词的文档编号,利用这个数据结构能快速的找到包含某一个词的所有文档。 今天介绍则是搜索引擎的核心中的核心:倒排索引。接下来的所有内容都围绕着倒排索引展开。 如何建立倒排索引对几亿甚至几十亿几百亿规模的文档集合建立倒排索引并不是一件很轻松的事情,它将面对着 IO 以及 CPU 计算的双重瓶颈,需要根据实际情况找到最优方法,接下来介绍两种不同的建立倒排的方式。 单遍内存型
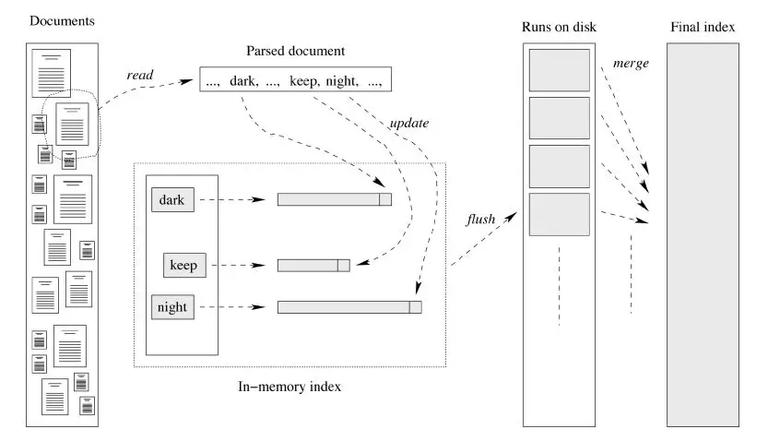
内存中维护每个词对应的文档编号列表,当一个词对应的 buffer 满时,把内存中的数据 flush 到磁盘上,这样每个词对应一个文件。最后按照词编号由小到大的合并所有文件,得到最终的倒排索引。
多路并归型
步骤如下:
与内存型相比,这种方式适合在内存小,磁盘大的情况下进行倒排索引的建立,它的优缺点如下。
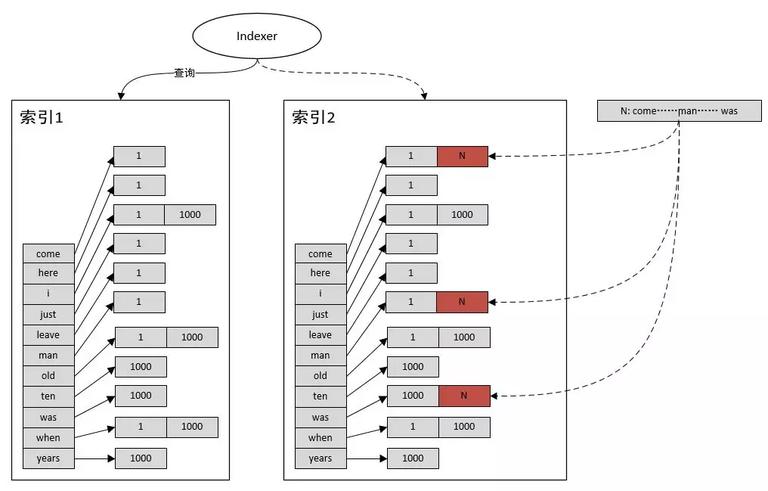
索引切分考虑到在海量文档下,倒排索引非常大,单台机器无法在内存中装下全部索引,所以有必要把索引进行切分,使得每一个索引服务只对文档中一部分的内容进行拉取、计算。常见的有两种可选择的方式。
按文档编号切按照文档编号把文档分成几个小的集合,对每个小的文档集合单独建立索引。在这种方式建立索引上进行查询时,merge 需要把查询请求下发到所有的后端 indexer 服务(因为每个 index 都有可能存在包含查询词的文档),indexer 服务的计算量比较大。但是它也有一个优点:每个词的倒排拉链的长度可控。 按 term 切分按照词进行索引划分,每个索引只保存若干词的所有文档编号。在这种方式建立的索引上进行查询时,merge 可以根据查询词精确的把请求下发到对应的 indexer 上,减少了后端 indexer 的计算量。 但是这么做引入几个新问题:
那么在实际中该如何进行索引切分呢?主要看是什么类型的查询、查询的量、以及文档集合的规模。
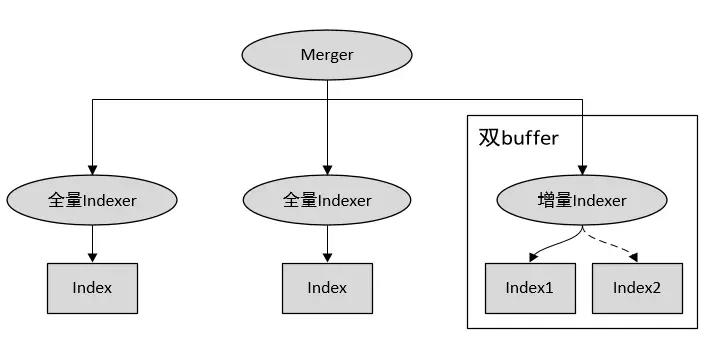
增量索引很多搜索引擎都注重时效性搜索,比如对于时下刚刚发生的某件热门事件,需要搜索引擎能够第一时间搜索到该热门事件的页面,这该如何做到呢?由于建立一次全量文档倒排的时间基本都是按天计,如果不设计一些实时增量索引,那么根本满足不了时效性的检索。下面介绍增量索引,可以解决时效性搜索问题。 倒排索引双 buffer 设计方案
增量步骤:
这样可以保证实时的动态更新,但是它的缺点也很明显:必须使用 2 倍索引大小的内存,机器成本比较高,实际中更常用的是下面一种方案。 增量索引服务 + 双 buffer 方案
全量索引服务用来查询截止到某一个日期的全部文档,增量索引服务使用双 buffer 设计方案查询最近一段时间(可能是小时级或者分钟级)内实时更新的文档内容,然后定期(每天、每周、每月一次)把最近一段时间更新的文档追加在全量索引中。这样做的好处就在于只有少量近期更新文档的查询需要使用双倍内存,机器成本降低。需要注意的一点是,用这种方式建立增量索引时,必须更新全局 word 的 df 信息,对于发现的新词还需为其添加全局唯一 id,这些信息统统要更新到线上正在运行的全量索引服务。 利用 Hadoop 并行建立倒排索引
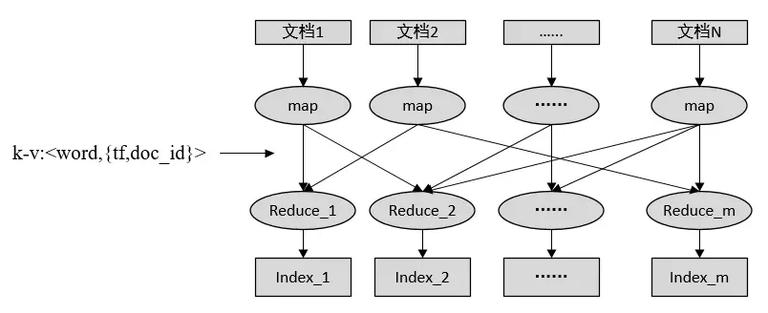
对于超大规模的文档集合,可以使用 Hadoop 建立倒排索引。
实际工作中,为了增加 map 端读数据性能,并不是每个文档存放成单独一个文件,而是先把文档序列化成文件中的一行,这样每个文件可以存放多个文档内容,这就减少了小文件数,增加了 map 端的吞吐量。 总结倒排的建立还有查询涉及到的技术内容远远不止于此,在这里可以推荐两本书给大家,有兴趣的小伙伴可以进行深入的学习,共同进步。
|


时间:2018-09-16 22:44 来源: 转发量:次

声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。