UC 国际信息流推荐中的多语言内容理解
|
|
▌多语言内容理解的需求和挑战 1. 结构化是推荐的基础
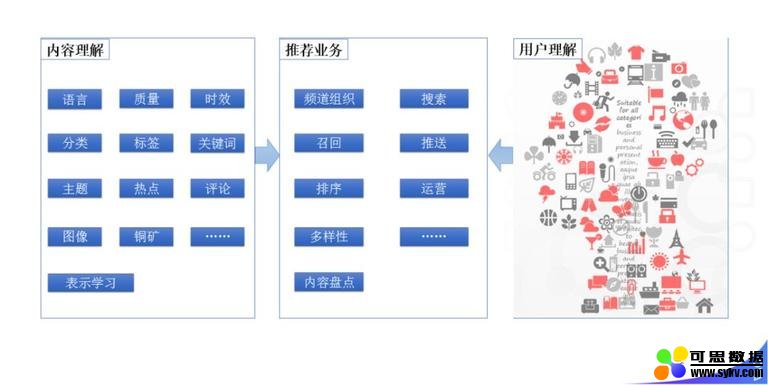
结构化是推荐的基础,对于大多数做推荐的同学应该会比较有感受。可以把推荐系统分为三部分:内容理解和用户理解两个大的离线模块;在线的推荐业务分为召回、排序、多样性等,主要利用离线的 NLP 结构化信号以及离线的用户理解信号来完成推荐的工作,本文主要介绍内容理解的部分。 对于内容理解,我们面临的是多个国家、多种语言的新闻推荐场景:
2. 多语言的业务需求 UC 国际化信息流推荐面临的多语言的业务需求:
3. 技术难点 由此带来的挑战,包括:
所以,在我们的场景下,这是一个典型的资源匮乏型 (Low Resource) 的 NLP 问题。 ▌多语言内容结构化信号建设方法 1. 内容结构化的发展路径 ① 内容结构化信号
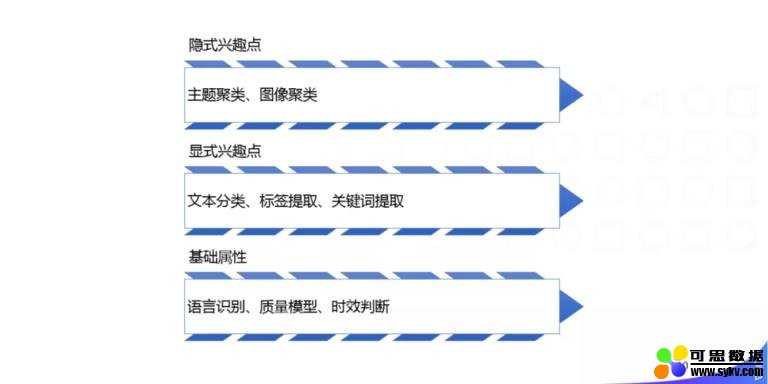
从内容结构化信号整体上来讲,我们从底向上做了很多不同类型的内容结构化信号:
② 基础词法分析——去语言化 因为我们面临了 10 多种语言,多种不同的任务,对后续的算法,如:分类、标签,以及下游的推荐和用户画像来讲,我们期望尽量把语言相关的东西在 NLP 中解决,下游的一系列任务可以去语言化,算法能够通用。所以,我们尽量在基础的词法分析阶段就把语言的鸿沟消除掉。 我们面临的难点是覆盖语言种类比较多,标注标准比较多。所以我们尽量采用的是 Google 开源的 Universal Dependency 数据库,它覆盖了 70 多种语言,100 多个 Treebank。我们期望在所有的语言和任务上采用同样的标准,在词法分析阶段都处理成标准的 schema 以后,下游即使写规则,也不需要换标签集。我们在开源工具的基础上,做了一系列的迭代工作,覆盖了 10 多种语言的词法分析。 ③ 实体识别
我们会做多语言的实体识别,主要利用的是 Wikidata 多语言知识图谱,来挖掘高质量的词典,同时使用半监督或者数据增强的方式标注一部分资源,然后还有一部分人工校对的工作在里面。用的算法和中英文上的并没有太大的区别,主要是 LSTM + CRF 序列标注算法。但是我们在资源方面投入了很大的精力,以数据增强为例,我们可以从学术圈或者公开数据集上拿到很多各个语言的 NER 标注语料,结合我们挖掘出来的多语言的知识图谱,可以直接做数据增强的一些办法(在图片和视觉方面,做数据增强可能很容易,但是在 NLP 角度做数据增强并不是很容易)。比如“巴黎是法国的首都”,如果把“巴黎”换成“伦敦”对于人来说是不可理解的,是错的,但是对于机器训练 NER 来说这是没有问题的,所以我们会用规则或者知识图谱来限制这种数据增强的规模,取得了比较明显的效果。 ④ 多语言分类发展阶段
我们在多种语言上都经历了这样的分类发展阶段:
简单举几个例子:
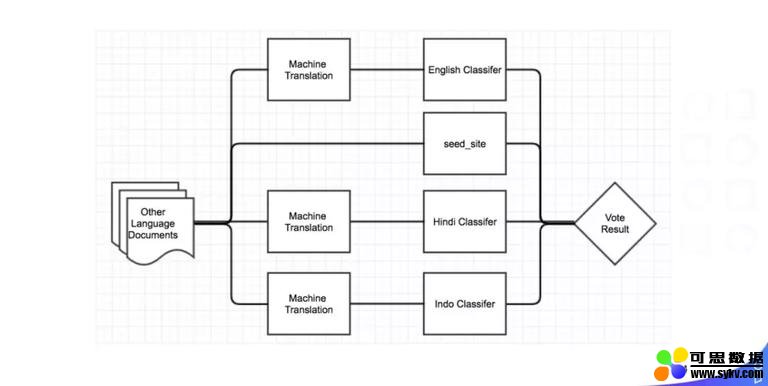
我们所有的分类都是多种策略并行的系统,没有一个语言是单纯的系统或者策略。最开始我们在英文、Hindi、Indo 上投入了很多资源,所以结构化的信号建设基本成熟,因为在后面开展一些小语种的时候,会采用多种的办法做样本迁移和特征的迁移。 比如样本迁移,我们会采用图中的办法:把小语种翻译为三个大语种,用大语种的 model 做分类。
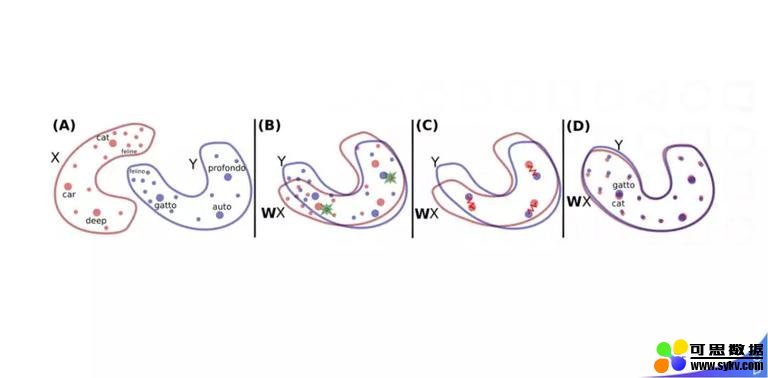
这是 Facebook 提出的多源词向量对齐的办法 MUSE,MUSE 的基本思想是用单语言的训练语料去训练每一个单语种的词向量,然后再加上一个双语词典,可以把不同语言的词向量映射到同一个空间,他们的目标是映射到同一个空间时,表示相同语义的词距离更近。这种方法在一些有共性的语言上,比如印尼语和英语,效果会比较好,但是在语言差异较大时,效果会弱一点,整体上这种方法还是给我们带来了很多可选的样本。 去年 Facebook 又提出了基于句向量对齐的 LASER,由于需要双语机器翻译的语料,应用起来的话限制条件会比较多。
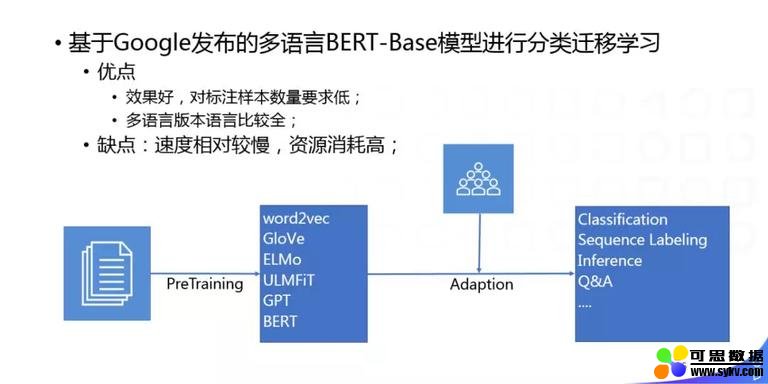
从去年开始,先用大规模的单一语料做 PreTraining,使用 ELMo、GPT 或者 BERT,得到一个单语的文本表示,后面再接一些你自己的任务做 Adaption,已经成了 NLP 的一个基本范式。我们也在很多的任务(如:分类和标签)中采用这种办法,其优点是对标注样本数量要求低,在一些小样本上就可以得到很好的效果,但是也存在着缺点就是速度相对较慢,资源消耗比较高,因为我们的语种比较多,所以还会做一些半监督和知识蒸馏相关的一些探索性工作。 ⑤ 语义标签
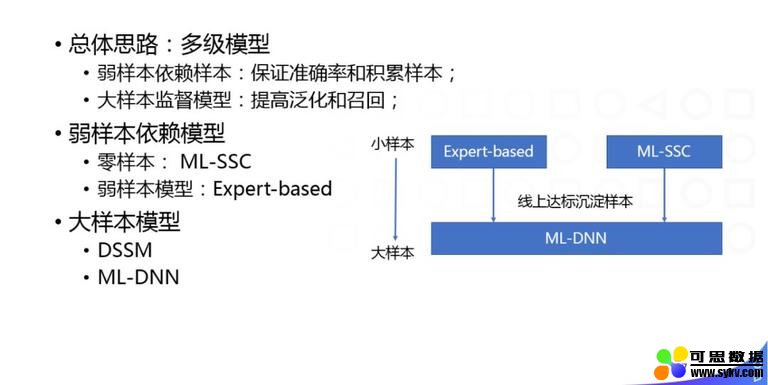
除了分类以外,我们还会做标签,我们的总体思想是一样的,先基于专家经验去累积样本,累积一定样本之后会做一些大规模的有监督学习模型。
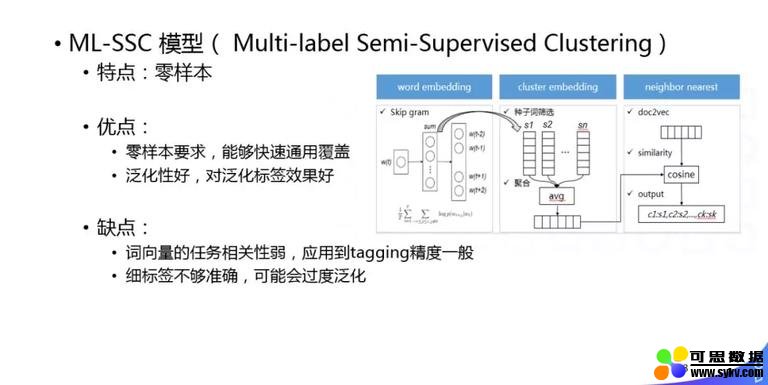
举个简单例子,我们如何做弱样本的依赖模型,它的特点是零样本。如果定义一些语义标签之后,通过 word embedding 先相关很相似的词,然后把这些词做聚类,聚类以后才作为一个语义标签簇的表达,之后直接和 doc 的 embedding 做相似性计算,我们就可以不需要训练样本,完全单语的语料就可以给文章打标签,这种方法对粗粒度的标签效果还可以,但是对细粒度的效果还不行,只能保证一些比较粗的标签的召回,提供一些基础的样本,供后续的人或者算法做二次校验。
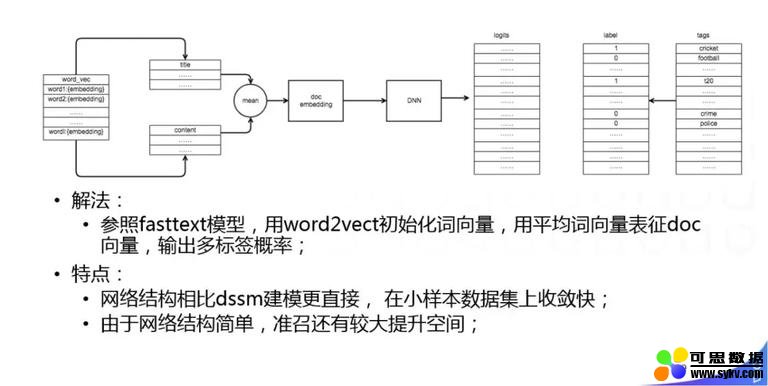
通过各种策略挖掘和人工总结大量样本之后,我们可以使用一些大样本的有监督模型,我们的做法比较简单:参照 Fasttext 模型,用 word2vect 初始化词向量,用平均词向量表征 doc 向量,输出多标签概率,就是把刚刚的做法直接迁到有监督的框架下。它的优势是模型比较简单,结合之前做的一些工作,可以快速的覆盖头部的语义标签。 2. 内容质量模型 刚刚讲的是分类和标签,这种结构化的信号,我们再来讲下内容质量:
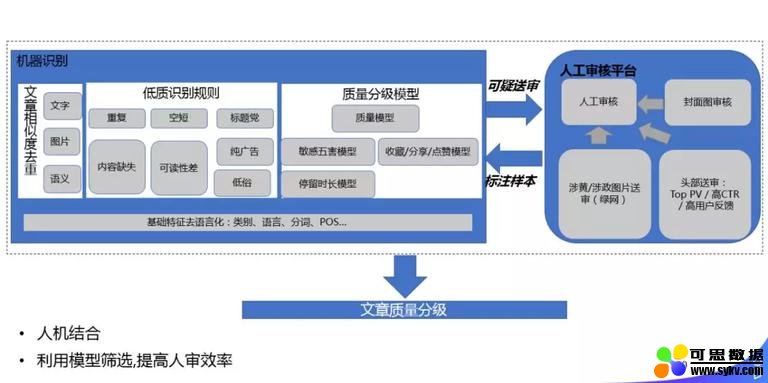
因为质量是新闻推荐的一个基本红线,在国内可能体会更深,像今日头条、快手等有段时间就因为一些质量的问题被下架了,我们在国际化时,也会遇到这样的问题。 我们的质量模型,基本还是一个人机结合的框架。主要通过一些低质的规则,能够把一些高危的 item 直接检测出来,直接干掉;我们还有一个质量的分级模型,会从多个维度做多个子模型,然后再有一个大的模型来融合这些子模型,质量平台输出的一些不太确认的结果会送到人工审核平台去审核,人工审核平台审核后的结果又会返回到质量模型做 training。在这个过程中,整个框架是去语言化的,我们输入的是 NLP 基础结构化的信号(类别、语言、分词、POS 等),后面的算法不会对语言做特殊的处理。
对于质量规则,我们的准确率会比较高,召回低一点,主要是为了保证检测出绝对低质的东西。 对于质量模型,我们主要分为 5 挡,然后做多维度子模型的融合。 3. 图像信息的应用
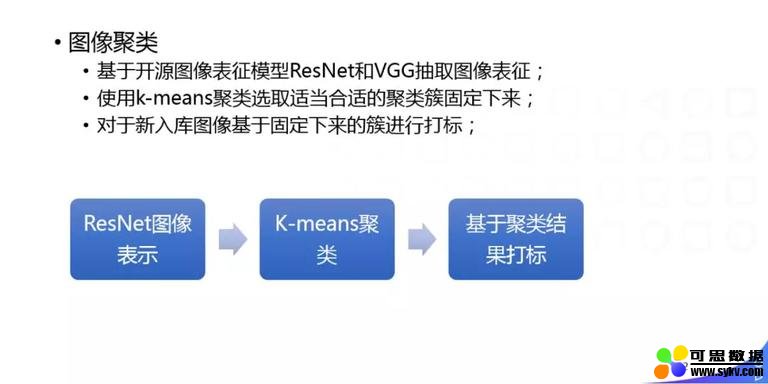
刚刚讲的都是一些用户显式的结构化信号,比如语言、分类、标签等人可理解的一些显式信号,显式信号在不同语言的发展进度和阶段是不一样的,为了让一些小语种追赶上大语种的节奏,我们还会做一些不依赖于 NLP 基础建设的一些用户显式的兴趣挖掘,就是内容结构化上的一些隐式的信号。比如图像方面的一些工作:因为语言在不同国家不同语种上会有资源的问题,对于图像,除了上面的一些文本,其它方面是没有太大语言鸿沟的,所以我们会做一些图像方面的工作,比如图像聚类。 具体的做法是:基于开源图像表征模型 ResNet 和 VGG 抽取图像表征,使用 K-means 聚类选取适当合适的聚类簇固定下来,然后对于新入库图像基于固定下来的簇进行打标。这样会得到什么结果呢?
这是从我们库中找的一些样本,对印度的一些封面图做了一些基于这样表示的聚类,最左边是聚类的编号,从这些样本中可以看到一些共性,比如第 23 个 topic 都是关于狗的,24 基本都是钱等等,我们可以直接把这些信号用到 rank 或者召回中,比如印度人比较喜欢的我们的一个场景叫 Memes (用户发一张图,上面会加一些文字,其它的什么都没有),这时用图像信息做召回效果会比较好。我们通过这种隐式的聚类的编号,跟分类的一些信号做交叉 mapping,发现这里很多类别直接可以对到二级分类,并且准确度高,这样就可以快速的建立很多分类的样本。 4. 表示学习在内容理解和用户理解中的应用
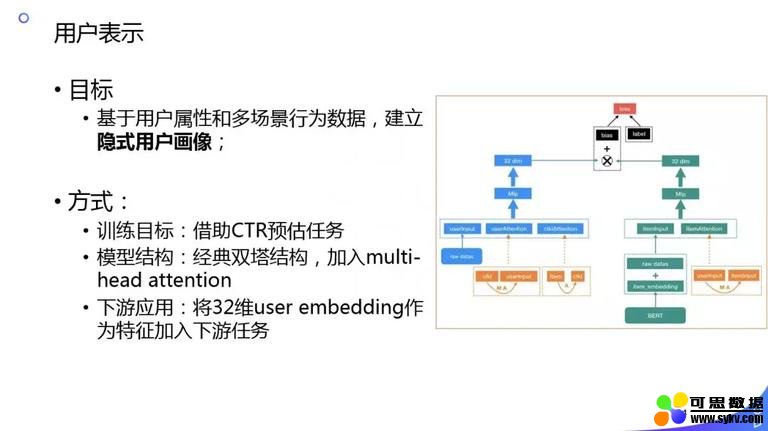
刚刚讲的都是内容理解方面的内容,接下来简单介绍下用户表示。我们在做内容结构化信号时,用户显式可以理解的信号,在不同的语种上,特别是小语种上,我们的迭代速度以及精度跟不上推荐的诉求,这时我们需要用一些隐式的信号,提升推荐的效果。我们的想法是基于预训练在具体任务做 fine-tuning 这种范式已经在 NLP 和图像领域验证过了,所以我们在推荐领域做了这样的尝试: 我们利用用户的消费数据直接建立双塔,类似于 CTR 预估,一边是 user,一边是 item,item 直接用 BERT 的 embedding 作为初始输入,然后两边做双塔结构,这样做的好处是可以引用更多的用户在其他场景下的一些行为,比如用户在浏览器中的一些搜索 query,这时再离线做双塔,user 侧一直往上走,然后 item 侧一直往上走,最后分别得到 user 和 item 的隐含表达,然后再做相似度计算,预估 ctr,但是这不是我们的目的,我们的目的是直接用 user 的表达给下游用。这样在一些稀疏的场景效果提升明显,比如 Push。 ▌总结 简单总结下本次分享的内容:
本次的分享就到这里,谢谢大家。 PS:想加入阿里大鱼技术沙龙的小伙伴,欢迎关注本文公众号,后台回复关键词:[小师妹],加阿里大文娱小师妹的微信号进群,更有相关的职位推荐哦。
分享嘉宾 ▬
汪昆 阿里巴巴 | 算法专家
|






时间:2019-10-10 22:15 来源: 转发量:次

声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。