手工计算神经网络第三期:数据读取与完成训练
|
|
小伙伴们大家好呀~~用Numpy搭建神经网络,我们已经来到第三期了。第一期教大家如何用Numpy搭建一个简单的神经网络,完成了前馈部分。第二期为大家带来了梯度下降相关的知识点。 这一期,教大家如何读取数据集,以及将数据集用于神经网络的训练,和上两期一样,这次依然用Numpy实现。在开始代码之前,先带大家看看今天我们使用的数据集。 数据集介绍 数据集采用著名的MNIST的手写数据集。根据官网介绍,这个数据集有70000个样本,包括60000个训练样本,10000个测试样本。 数据集下载下来之后,文件分为4个部分,分别是:训练集图片、训练集标签、测试集图片、测试集标签。这些数据以二进制的格式储存。
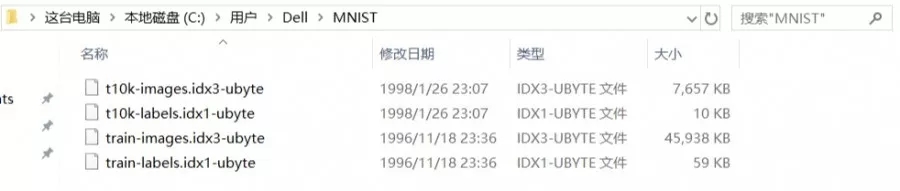
其中,训练集图片文件的前16个字节是储存了图片的个数,行数以及列数等。训练集标签文件前8个字节储存了图片标签的个数等。测试集的两个文件同理。
下载好的文件存储地址 读取数据
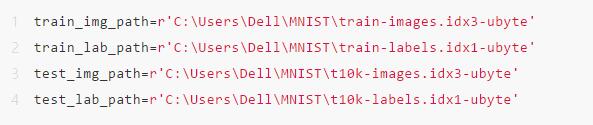
根据文件在本地解压后的储存地址,生成四个地址,上面代码中‘r’是转义字符,因为\在Python中有特殊的用法,所以需用转义字符明确文件地址。 为了让后面的模型表现更好,我们将训练集拆分,拆成50000个训练集和10000个验证集。 注:验证集是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。

因为,文件是以二进制的格式储存,所以数据读取方式是‘rb’。又因为我们需要数据以阿拉伯数字的方式显示。所以这里用到了Python的struct包。struct.unpack('>4i',f.read(16))中的>号代表字节存储的方向,i是整数,4代表需要前4个整数。f.read(16)是指读取16个字节,即4个整数,因为一个整数等于4个字节。 reshape(-1,28*28):如果参数中存在-1,表示该参数由其他参数来决定.-1是将一维数组转换为二维的矩阵,并且第二个参数是表示每一行数的个数。 注:fromfile的用法np.fromfile (frame, dtype=np.float, count=‐1, sep=''),其中:frame : 文件、字符串。dtype :读取的数据类型。count : 读入元素个数,‐1表示读入整个文件。sep : 数据分割字符串。 文件读取完成,接下来按照用图片的方式显示数据。

注意,如果不定义cmap='gray',图片的底色会非常奇怪。
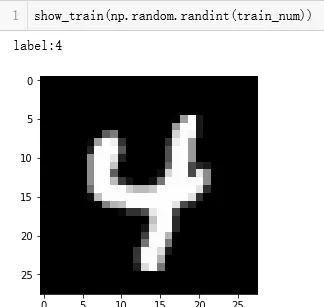
测试一下,定义完函数之后,显示的是这样的~ 数据显示和读取完成,接下来开始训练参数。 训练数据 在开始之前,为了能够上下衔接,我们把第一次课程的代码贴上来~

先定义两个激活函数的导数,导数的具体推到过程在这里不呈现,感兴趣的同学可以自行搜索。

其中tanh的导数 是np.diag(1/(np.cosh(data))**2),进行优化后的结果是1/(np.cosh(data))**2 注:diag生成对角矩阵 ,outer函数的作用是第一个参数挨个乘以第二个参数得到矩阵 然后定义一个字典,并将数解析为某一位置为1的一维矩阵

求平方差函数,其中parameters是我们在第一次课程定义的那个初始化的参数,在训练的过程中,会自动更新。

def sqr_loss(img,lab,parameters): y_pred = predict(img,parameters) y = onehot[lab] diff = y-y_pred return np.dot(diff,diff) 计算梯度

这次的梯度计算公式用到了公式:(y_predict-y)^2,根据复合函数求导,所以有-2(y_prdict-y)乘以相关的导数,这也是grad_b1后面-2的来历。 按理说应该更加导数的定义[f(x+h)-f(x)]/h验证下我们的梯度求的对不对,为了照顾新手同学对神经网络的理解过程,这一步在这儿省略了哈。 下面进入训练环节,我们将数据以batch的方式输入,每个batch定位包含100个图片。batch_size=100。梯度的获取是用平均求得的,代码体现在:grad_accu[key]/=batch_size。

采用copy机制,是避免parameters变化影响全局的训练,copy.deepcopy可以重新拷贝不影响原来的数据。 并且这里用到了公式:
然后定义学习率:

里面的if语句可以让我们看到神经网络训练的进度。
到这里,我们就完成了神经网络的一次训练,为了验证准确度如何,我们可以用验证集看看准确度如何。 定义验证集的损失:

计算准确度:

最后得到结果:
有90%的准确度哎~结果还好,还好,毕竟没有怎么调学习率以及解决过拟合。 好了,这一期的内容就到这了,内容有些多大家多多消化,下一期我们讲讲怎么调节学习率以及看看更复杂的神经网络。 *注:此篇文章受B站up主大野喵渣的启发,并参考了其代码,感兴趣的同学可以去B站观看他关于神经网络的教学视频,以及到他的Github地址逛逛。 视频地址与Github: https://www.bilibili.com/video/av51197008 https://github.com/YQGong 作者:蒋宝尚 |

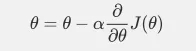


时间:2019-06-05 23:35 来源: 转发量:次

声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。