揭秘LinkedIn!全球最大的招聘推荐系统如何被机器
|
|

来源:towardsdatascience LinkedIn是迄今为止市面上极受欢迎的招聘平台之一。来自世界各地的招聘者每天会从LinkedIn上网罗挑选适合他们招人岗位的候选人。 像LinkedIn Recruiter这款产品,就可以帮助招聘者创建并管理一个人才库,最大限度地提高招人成功率。这款产品的高效性能是通过一系列极其复杂的搜索和推荐算法来实现的,这些算法利用了最先进的机器学习架构,也考量了很多实际因素。

除了在构建一个世界上最有价值的数据集之外,LinkedIn一直在通过各种实验来突破机器学习技术,希望把人工智能的一流体验带入LinkedIn产品中。 招聘产品的推荐功能对LinkedIn的机器学习技术提出了很大的挑战。除了处理庞大且不断增长的数据集,招聘产品还需要处理很多随机且复杂的查询和筛选需求,并提供与之非常相关的结果。搜索环境是如此多变,以至于很难将这个问题简单转换为机器学习的模型来解决。以招聘产品为例,LinkedIn使用了一个包含三个因素的标准来描述搜索推荐模型需要实现的目标。 1.关联:搜索结果不仅需要返回给相关的候选人,还需要显示可能对目标职位感兴趣的候选人。 2.智能查询:搜索结果不仅应该返回匹配特定条件的候选人,还应该返回相近条件的候选人。例如,搜索机器学习应该返回在技能集中列出数据科学的候选人。 3.个性化:通常,为一家公司寻找到理想候选人考虑的因素并不在搜索条件里。还有些时候,招聘人员也不确定使用什么标准。个性化搜索结果是任何成功的搜索和推荐体验的关键因素。 LinkedIn招聘产品搜索和推荐体验的第四个关键标准不像前三个标准那么明显,它关注的是简单的衡量指标。为了简化推荐体验,LinkedIn对一系列关键指标进行了建模,这些指标是成功招聘的有效指标。例如,站内信阅读数量似乎是判断搜索和推荐过程有效性的一个明确指标。从这个角度来看,LinkedIn将这些数据作为衡量其机器学习算法优化程度的关键指标。
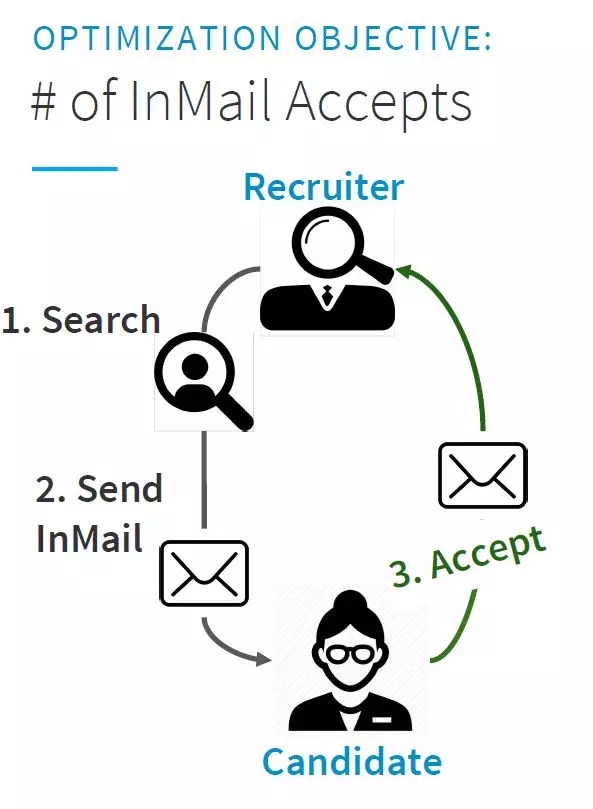
优化目标:接收到的站内信数量。从招聘者开始1、搜索 2、发站内信到候选人 ,然后候选人3、接受阅读并反馈给招聘者 科学:从线性回归到梯度增强决策树 LinkedIn Recruiter最初的搜索和推荐经验是基于线性回归模型。虽然线性回归算法很容易解释和调试,但它们在LinkedIn等大型数据集中找不到非线性关联。为了改善这种体验,LinkedIn决定使用梯度增强决策树(GBDT)来将不同的模型组合成更复杂的树结构。除了更大的假设空间外,GBDT还具有其他一些优点,如能够很好地处理特征共线性、处理不同范围的特征以及缺少特征值等等。 与线性回归相比,GBDT本身提供了一些切实的改进,但也未能解决搜索体验的一些关键挑战。有一个著名的例子,输入搜索牙医的请求,却返回了具有软件工程头衔的候选人,因为搜索模型优先考虑寻找工作的候选人。为了改善这一点,LinkedIn添加了一系列基于成对优化技术的上下文感知功能。从本质上讲,该方法扩展了GBDT的两两排序目标,以比较相同背景下的候选人,并评估哪个候选人更适合当前的情况。
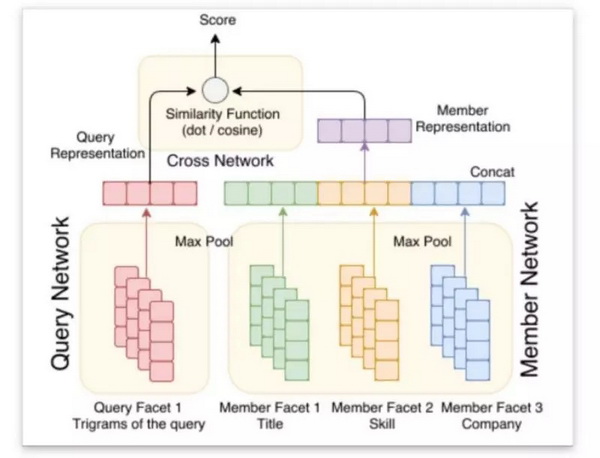
Linkedin Recuriter的另一个挑战是,如何将应聘者与“数据科学家”和“机器学习工程师”等相关头衔匹配起来。仅使用GBDT很难建立这种相关性。为了解决这个问题,LinkedIn引入了基于网络嵌入语义相似特性的代表学习技术。在这个模型中,搜索结果将根据查询的相关性由具有类似职位的候选人补充。
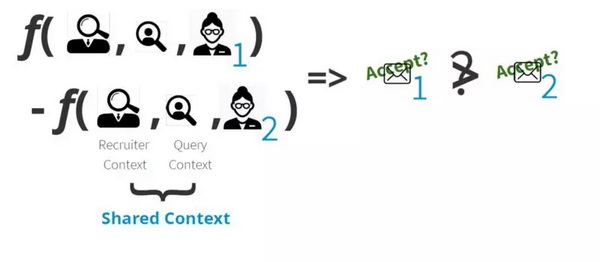
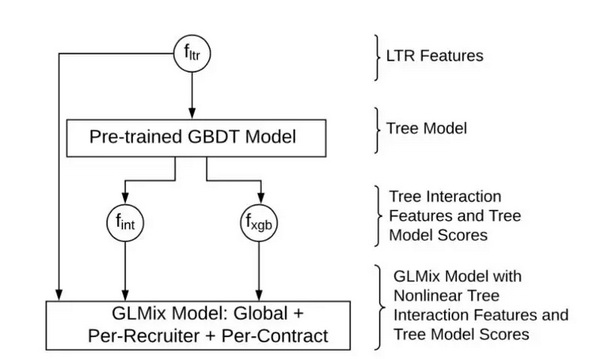
可以说,LinkedIn Recruiter面对的最难解决的挑战是个性化。从概念上讲,个性化可以分为两大类。实体级个性化侧重于在招聘过程中考虑进去不同参与个体的偏好,如招聘人员、合同、公司和候选人。 为了应对这一挑战,LinkedIn采用了一种著名的统计方法,称为广义线性混合(GLMix),它使用推理来改进预测问题的结果。 具体来说,LinkedIn的招聘人员使用了一种架构,它结合了学习排名功能、树交互功能和GBDT模型评分。将学习到等级的特征作为预先训练的GBDT模型的输入,该模型生成编码为树交互特征的树集合和每个数据点的GBDT模型得分。然后,利用原始的学习排序特性及其以树交互特性和GBDT模型评分形式的非线性转换,广义线性模型可以实现招聘级和合同级的个性化。
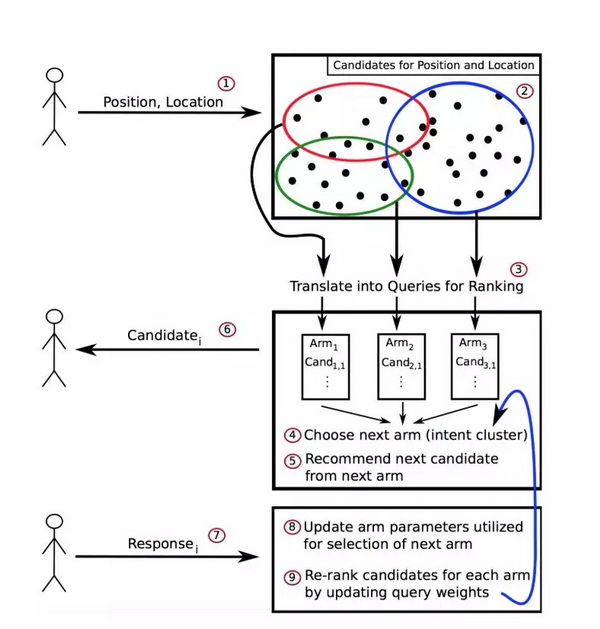
LinkedIn招聘官所要求的另一种个性化体验是在当前搜索环节里的体验升级。利用离线学习模型的一个缺点是,当招聘人员审查推荐的候选人并提供反馈时,这些反馈是不会被采用到当前搜索环节里的。为了解决这个问题,LinkedIn Recruiter使用了一种被称为“多武器强盗模型”的技术来改进不同候选人群体的推荐。体系结构首先将工作的潜在候选人划分为技能组。然后,利用一个多武器强盗模型,根据招聘人员当前的意图来了解哪一组更适合,并根据反馈更新每个技能组中的候选人排名。
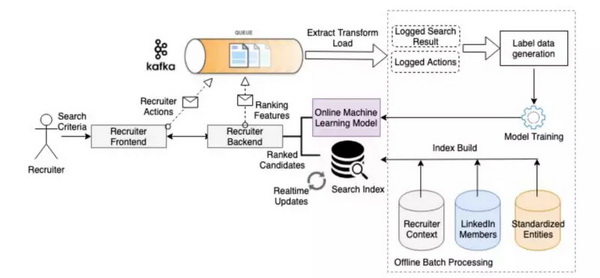
架构 LinkedIn Recruiter的搜索和推荐体验基于一个名为Galene的专有项目,该项目建立在Lucene搜索堆栈之上。上一节描述的机器学习模型有助于为搜索过程中使用的不同实体构建索引。
招聘人员搜索体验的排名模型基于一个具有两个基本层的体系结构。 L1:挖掘人才库,并对候选人进行评分/排名。在这一层中,候选检索和排序以分布式方式完成。 L2:改进入围人才,以应用更多的动态功能使用外部缓存。
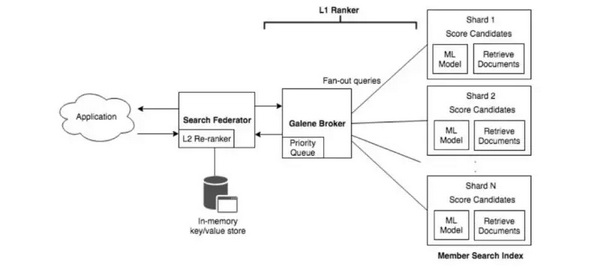
在该体系结构中,Galene代理系统将搜索查询请求分散到多个搜索索引分区。每个分区检索匹配的文档,并将机器学习模型应用于检索到的候选文档。每个分区对候选项的子集进行排序,然后代理收集排序后的候选项并将它们返回给联邦服务器。连接使用附加的排序功能对检索到的候选项进行进一步排序,并将结果交付给应用程序。 LinkedIn是大规模构建机器学习系统的公司之一。LinkedIn Recruiter使用的推荐和搜索技术的想法与不同行业的许多类似系统有着惊人的相关性。LinkedIn工程团队发布了一份详细的幻灯片来展示他们是如何构建世界级推荐系统的。 相关报道: https://towardsdatascience.com/inside-the-machine-learning-powering-linkedin-recruiter-recommendation-systems-7da503ad55c0 |
时间:2019-05-30 00:08 来源: 转发量:次

声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。