机器学习的不同类型
|
|
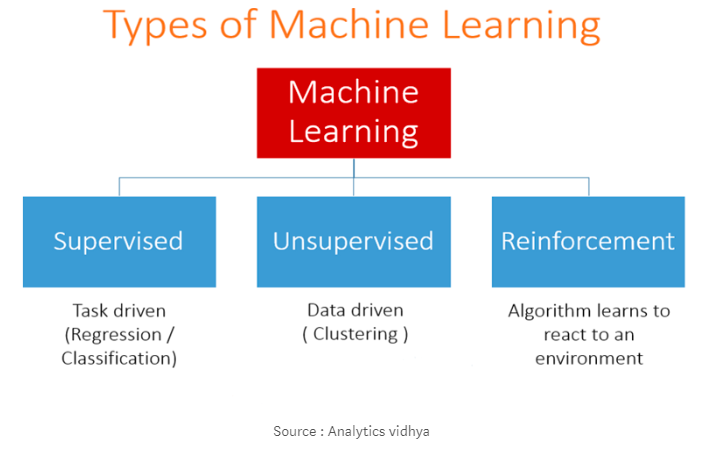
强化学习对于解决问题非常强大且复杂。 有监督学习我们知道,机器学习以数据为输入,我们称这个数据为训练数据。 训练数据包括输入和标签(目标)。 什么是输入和标签(目标)?例如,两个数字相加a=5,b=6结果=11,输入为5,6,目标为11。 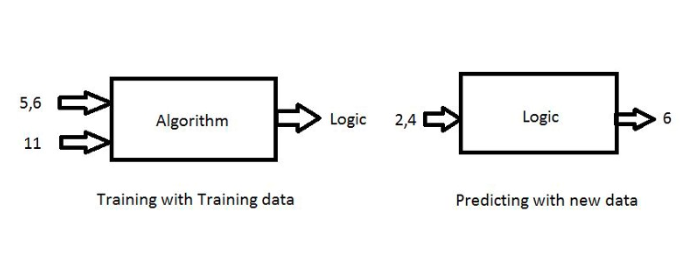
我们首先用大量的训练数据(输入和目标)来训练模型。
这个过程被称为监督学习,它非常快速和准确。 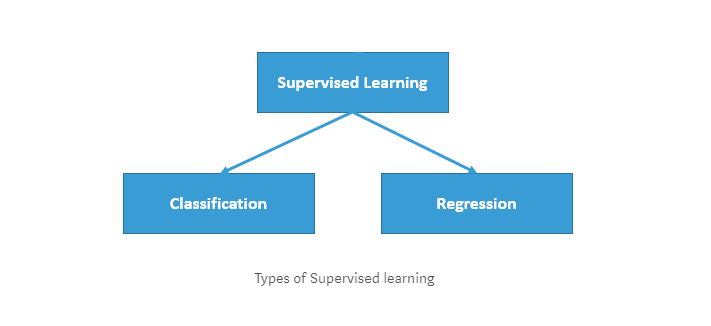
回归:这是我们需要预测连续响应值的一类问题(例如:上面我们预测的数字可以从-∞变化到+∞) 一些示例
等等,我们可以预测很多事情。 分类:这是一类我们预测类别响应值的问题,数据可以被分成特定的“类”(例如:我们预测一组值中的一个值)。 一些例子是:
基本上,“是/否”类型的问题被称为二元分类。 其他例子包括:
这种类型称为多类分类。 这是最后一张图片。 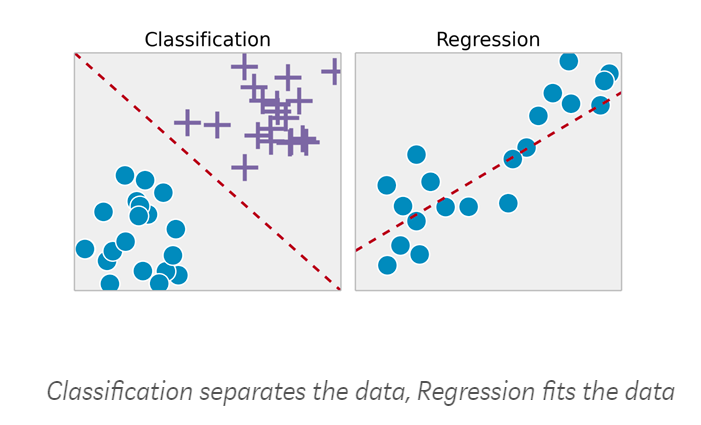
这就是监督学习的全部内容。 无监督学习训练数据不包括目标,所以我们不告诉系统去哪里,系统必须从我们给出的数据中了解自己。 
这里的训练数据不是结构化的(包含噪声数据、未知数据等)。 例如:来自不同页面的随机文章 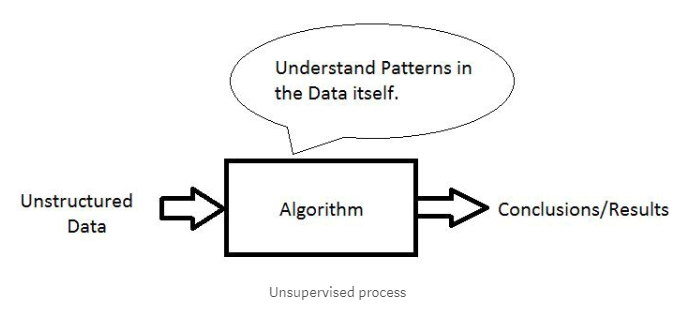
无监督学习也有不同的类型,比如聚类和异常检测(聚类非常有名)。 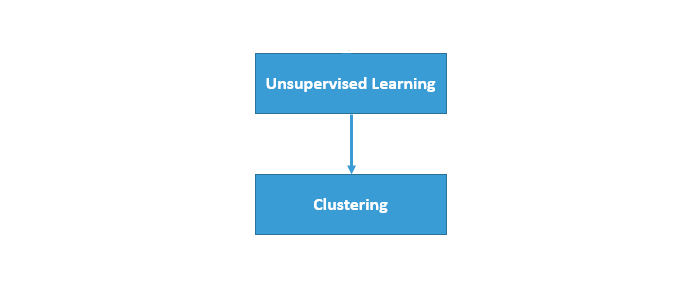
聚类:这是一种把相似的东西聚在一起的问题。 一些例子是:
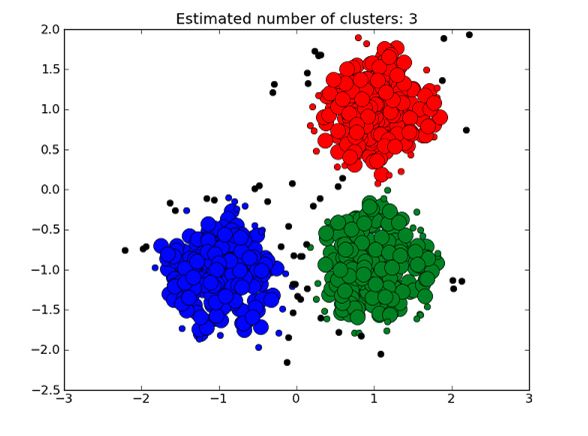
无监督学习是一种较难实现的学习方法,其应用范围不及有监督学习。 我想在另一篇文章中介绍强化学习,因为它很激烈。 所以 这就是这个文章的全部内容,希望你能有所了解。 |
时间:2019-03-28 23:23 来源:未知 转发量:次

声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。