




数据挖掘
-

利用 Scikit Learn的Python数据预处理实战指南
简而言之,预处理是指在你将数据“喂给”算法之前进行的一系列转换操作。在Python中,scikit-learn库在sklearn preprocessing下有预装的功能。有...
2018-10-10 22:27:38 -

为什么说 Storm 比 Hadoop 快?
storm的网络直传、内存计算,其时延必然比hadoop的通过hdfs传输低得多;当计算模型比较适合流式时,storm的流式处理,省去了批处理的收集数...
2018-10-10 22:26:56 -

Kafka 在行动:7步实现从RDBMS到Hadoop的实时流传输
本文目标读者是技术人员。 继续读,我会图解Kafka如何从关系数据库管理系统(RDBMS)里流输数据到Hive, 这可以提供一个实时分析使用案例。...
2018-10-10 22:26:14 -

Python在实时嵌入式系统开发中扮演的五个主要角
随着Python的日益普及,人们可能会问,在实时嵌入式系统中是否也有Python的一席之地。...
2018-10-10 22:25:05 -

分布式(hadoop)内核研发面试指南
本文是同学们进入阿里云等公司的hadoop内核研发岗位的一个指引,需要具备哪些要求,如果不具备则可以往这方面努力。...
2018-10-10 22:23:19 -

分享:R工具包一网打尽,超过300+工具
直到前几天我看到这个Awesome R文档,我就静不下来了,对比了目前自己的工作和以后的方向,非常适合我。所以毫不犹豫的把这个文档汉化...
2018-10-10 22:21:24 -
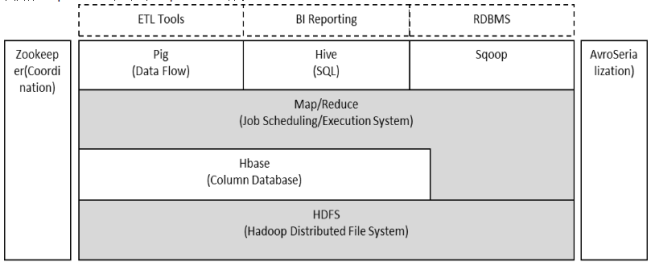
技术分享:Hadoop框架
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop ...
2018-10-10 15:48:42 -
用python管理自己的密码
大数据时代,各种网站都需要你注册账号,使用密码。往往大家为了省事,所有的平台的账号密码是一样的,假如某个网站数据泄露后,那...
2018-10-09 23:12:25 -

学会用Spark实现朴素贝叶斯算法
主要介绍了三个步骤去编写一个简单的朴素贝叶斯算法demo,还有一些值得优化的点,写法也比较偏命令式编程(告诉计算机你想要做什么事...
2018-10-09 23:11:49 -

美国大选Facebook舆情分析——基于R
为了从社交媒体这一渠道对两位候选人的竞选表现和粉丝基础有一个更为具体的了解。我们分析了一年多以来克林顿(大约360万粉丝)和特朗普...
2018-10-09 23:11:24 -

HBase原理-数据读取流程解析
总之,把这么复杂的事情讲明白并不是一件简单的事情,为了更加条理化地分析整个查询过程,接下来笔者会用两篇文章来讲解整个过程,...
2018-10-09 23:10:58 -

使用 MySQL 的视角去看待 MongoDB 数据库
这篇博客着眼于MongoDB和MySQL,从一个SQL用户的角度覆盖了MongoDB的优势、弱点、特性和使用。...
2018-10-09 23:10:10 -

Hadoop生态系统中的容器和微服务 玩出哪些新花样
最近大多数大数据应用都部署在裸设备上,这意味着Hadoop大多数部署在非虚拟化服务器上。随着容器和微服务对应用开发圈产生影响,这种...
2018-10-09 23:09:53 -

Hadoop开发过程中所遇到的那些坑
Hadoop开发过程中常见问题即解决方案。在Hadoop开发的过程中,我们总是遇到各种各样的问题,今天就整理总结一下...
2018-10-09 23:08:58 -

Apache CarbonData:大数据生态一种新的高性能数据格
Apache CarbonData是一种新的高性能数据存储格式,针对当前大数据领域分析场景需求各异而导致的存储冗余问题。...
2018-10-09 23:08:19 -

Facebook针对图数据处理对Apache Giraph 和 Spark Graph
一支Facebook 团队近期发表了一份比较报告,比较对象是他们当前的基于 Giraph的图处理系统和更新的 GraphX (它是流行的 Spark 框架的一部分)。...
2018-10-09 23:06:56 -

阿里云、Amazon、Google 云数据库方案架构与技术分
“「一切都会运行在云端」。云时代早已来临,本文着眼于顶级云服务商云服务商的云数据库方案背后的架构,以及笔者最近观察到的一些...
2018-10-09 22:57:08 -

Storm,Trident,Spark Streaming,Samza和Flink主流流处理
分布式流处理是对无边界数据集进行连续不断的处理、聚合和分析。它跟MapReduce一样是一种通用计算,但我们期望延迟在毫秒或者秒级别。...
2018-10-09 22:57:08 -

Storm,Trident,Spark Streaming,Samza和Flink主流流处理
在上篇文章中,我们过了下基本的理论,也介绍了主流的流处理框架:Storm,Trident,Spark Streaming,Samza和Flink。今天咱们来点有深度的topic,...
2018-10-09 22:57:08 -

大数据时代,“未来战警”应该长什么样?
说起“未来战警”,脑海中首先浮现的是浑身钢筋铁骨,拿着高科技装备威风凛凛的的模样。不过这种设定显然观赏性大于实用性,对于解...
2018-10-09 22:57:08 -

Spark 生态系统组件
Spark 生态系统以Spark Core 为核心,能够读取传统文件(如文本文件)、HDFS、Amazon S3、Alluxio 和NoSQL 等数据源,利用Standalone、YARN 和Mesos 等资源调...
2018-10-09 22:55:58 -

基于Kafka和ElasticSearch,领英是如何构建实时日志
今天和跟大家分享我们在用ElasticSearch和Kafka做日志分析的时候遇到的问题,系统怎么样一步一步演变成现在这个版本。你如果想拿ElasticSea...
2018-10-09 22:55:58 -

TensorFlow版本号升至1.0,正式版即将到来
现在,TensorFlow 的一岁生日之后两个月,TensorFlow 社区终于决定将 TensorFlow 的版本号升至 1 x,并也已于昨日发布了 TensorFlow 1 0 0-alpha,其新...
2018-10-09 22:55:58 -

Apache Beam成功孵化为Apache顶级项目:将统一大数据
1 月 10 日,Apache 软件基金会宣布,Apache Beam 成功孵化,成为该基金会的一个新的顶级项目。...
2018-10-09 22:55:58 -

Apache Beam:下一代的数据处理标准
本文主要介绍Apache Beam的编程范式——Beam Model,以及通过Beam SDK如何方便灵活地编写分布式数据处理业务逻辑,希望读者能够通过本文对...
2018-10-09 22:55:58 -

智慧城市离不开的四层数据“架构”
智慧城市中的智慧水资源 能源 交通 建筑管理等均是通过一个中央系统建立起来的。遍布城市的传感器网通过感测物理环境中的活动将数据...
2018-10-09 22:55:58 -

如何使用Apache Flume抓取数据
如何Apache Flume抓取数据,在抓取的过程中应该注意什么问题,本文简单介绍了以上问题。一、什么是Apache FlumeApache Flume是用于数据...
2018-10-09 22:55:58 -

谷歌提出深度概率编程语言Edward:融合了贝叶斯
深度神经网络的本质是组合式的(compositional)。用户可以以创造性的方式来将层连接起来,而无需担忧如何去执行测试(前向传播)或推理(基于...
2018-10-09 22:55:58 -

成本与性能兼得 简化Hadoop云部署的高招
对于大数据管理和分析应用程序云服务,用户的关注度正不断增长,而为了应对这一趋势,供应商已经开始努力简化Hadoop的云部署流程,并...
2018-10-09 22:55:58 -

新手必读:关于SQL选择查询
1 只要结果不问过程当我们写出一条SQL语句后,SQL语句是到数据库中去执行的,具体怎么理解和执行SQL是数据库的事,我们关心的事儿就是如...
2018-10-09 22:55:58 -

大数据从何而来?不得不知的7个数据源供应平台
国内外比较知名的数据API产品,基础性的可能更多会选择百度APIStore、聚合数据、Haoservice;而对于行业、专业有特别需求的用户来说,通联...
2018-10-09 22:55:58 -

Hadoop oozie sqoop --奇葩问题汇总
不管oozie还是sqoop都是通过hadoop来运行,所以若有什么问题,在$HADOOP_HOME logs userlogs目录下查找log进行问题定位,并且依赖什么的都最好放在...
2018-10-09 22:55:58 -

Python中Requests库的高级用法
前面讲了Python的urllib库的使用和方法,Python网络数据采集Urllib库的基本使用 ,Python的urllib高级用法 。...
2018-10-09 22:54:25 -

JavaScript 与 Java、PHP 的比较
网站开发的实践从设计方面开始,包括客户端编程语言。大体上说,在网页设计中使用了三种语言:HTML,CSS和JavaScript。自从网站发明以来,...
2018-10-09 22:54:25 -

Google的软件工程经验总结
Google 使用分布式编译系统,叫做 Blaze。Blaze 提供了标准的命令,用于编译和测试库中的所有代码。Blaze 这种统一的编译工具,让 Google 公司...
2018-10-09 22:54:25






