




数据挖掘
-

F1 Query: Declarative Querying at Scale
F1 Query 是一个大一统的 SQL 查询处理平台,可以处理存储在 Google 内部不同存储介质(Bigtable, Spanner, Google Spreadsheet)上面的不同格式文件。简单...
2018-10-24 11:55:15 -
没有完美的数据插补法,只有最适合的
数据缺失是数据科学家在处理数据时经常遇到的问题,本文作者基于不同的情境提供了相应的数据插补解决办法。没有完美的数据插补法,...
2018-10-23 16:59:51 -
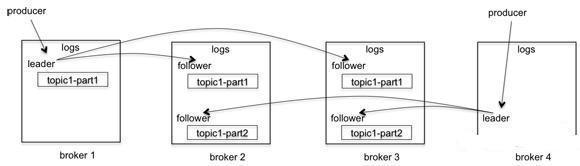
Kafka集群内复制功能深入剖析
Kafka是一个分布式发布订阅消息系统。由LinkedIn开发并已经在2011年7月成为apache顶级项目。kafka在LinkedIn, Twitte等许多公司都得到广泛使用,主...
2018-10-16 18:35:46 -

如何将传统关系数据库的数据导入Hadoop?
大多数企业的关键数据存在于OLTP数据库中,存储在这些数据库中的数据包含有关用户,产品和其他有用信息。如果要分析此数据,传统方法...
2018-10-16 18:35:01 -

论Spark高手是怎样炼成的
彻底掌握Spark框架源码的每一个细节;根据不同的业务场景的需要提供Spark在不同场景的下的解决方案;根据实际需要,在Spark框架基础上进行二...
2018-10-16 18:24:41 -

如何写一个更好的Python函数?
那怎么写好一个Python函数呢?...
2018-10-16 18:24:01 -
Spark灰度发布在十万级节点上的实践
本文介绍了顶级互联网公司数万节点下 Spark 的 CI 与 CD & CD 灰度发布实践。包含如何维护源代码,如何维护 Release 多版本,开发版与正式版,...
2018-10-15 19:04:01 -

数据科学家职位最常问的40道面试题
导读想去机器学习初创公司做数据科学家?这些问题值得你三思!机器学习和数据科学家被看作是下一次工业革命的驱动器。这也意味着有许许...
2018-10-13 23:57:21 -

给Python学习者的文件读写指南(含基础与进阶)
对于初学者来说,一份详尽又清晰明白的指南很重要。今天,猫猫跟大家一起,好好学习Python文件读写的内容,这部分内容特别常用,掌握...
2018-10-12 21:34:42 -

【深度学习】训练深度神经网络的方法 从数据预
深度学习中,为了有效地训练深度神经网络,有一些值得我们强烈推荐的做法。在本文中,我将介绍一些最常用的方法,从高质量训练数据...
2018-10-10 22:57:21 -

Python数据分析笔记——Numpy、Pandas库
Numpy最重要的一个特点是就是其N维数组对象,即ndarray,ndarray是一个通用的同构数据多维容器,其中的所有元素必须是相同类型的。...
2018-10-10 22:56:48 -

用Spark机器学习数据流水线进行广告检测
关于Spark的其它机器学习API,名为Spark ML,如果要用数据流水线来开发大数据应用程序的话,这个是推荐的解决方案。...
2018-10-10 22:56:17 -

使用R进行数据匹配的方法
R中的merge函数类似于Excel中的Vlookup,可以实现对两个数据表进行匹配和拼接的功能。与Excel不同之处在于merge函数有4种匹配拼接模式,分别为...
2018-10-10 22:55:36 -

23个适合Java开发者的大数据工具和框架
目前,编程人员面对的最大挑战就是复杂性,硬件越来越复杂,OS越来越复杂,编程语言和API越来越复杂,我们构建的应用也越来越复杂。根...
2018-10-10 22:55:09 -

深度学习在美团点评中的应用
近年来,深度学习在语音、图像、自然语言处理等领域取得非常突出的成果,成了最引人注目的技术热点之一。...
2018-10-10 22:54:46 -

Python编程需要注意的几个问题
研发人员在使用Python编程时会遇到众多问题,本文主要讲述的在在实际应用中的基本问题:...
2018-10-10 22:54:04 -

【干货】互联网数据挖掘导论
导读:本文说的主题是关于「数据挖掘」,以下为内容大纲,让大家对互联网搜索与挖掘有一个宏观的了解,即知道要做什么和怎么做。注...
2018-10-10 22:50:47 -

最实用的机器学习算法Top5
本文将推荐五种机器学习算法,你应该考虑是否将它们投入应用。这五种算法覆盖最常用于聚类、分类、数值预测和朴素贝叶斯等四个门类...
2018-10-10 22:48:11 -

实用又强大,6 款 Python 时间& 日期库推荐
在使用 Python 的开发过程中,除了使用 datetime 标准库来处理时间和日期,还有许多第三方的开源库值得尝试。...
2018-10-10 22:45:03 -

ZooKeeper原理及其在Hadoop和HBase中的应用
ZooKeeper是一个开源的分布式协调服务,由雅虎创建,是Google Chubby的开源实现。分布式应用程序可以基于ZooKeeper实现诸如数据发布 订阅、负载...
2018-10-10 22:43:39 -

用数据说话,R语言有哪七种可视化应用?
R语言提供了一系列的已有函数和可调用的库,通过建立可视化的方式进行数据的呈现。在使用技术的方式实现可视化之前,我们可以先一起...
2018-10-10 22:43:00 -

用Apache Flink的保存点技术重新处理数据流
在本文中,我们会讲述如何使用保存点功能来重新处理数据,并一定程度地深入底层,讲述这个功能在Flink中是怎么实现的。...
2018-10-10 22:42:28 -

一篇文章全面解析大数据批处理框架Spring Batch
针对OLTP,业界有大量的开源框架、优秀的架构设计给予支撑;但批处理领域的框架确凤毛麟角。是时候和我们一起来了解下批处理的世界哪...
2018-10-10 22:41:27 -

如何利用 Python 打造一款简易版 AlphaGo
2017 年伊始,再度出山的 AlphaGo 化名 Master 在网络围棋平台上打遍棋界无敌手。你是否也想打造一个自己的 AlphaGo 呢?GitHub 用户 Brian Lee(brile...
2018-10-10 22:40:14 -

Apache Kylin在唯品会大数据的应用
随着传统基于RDBMS的EDW往大数据的演进的过程中,Batch可处理的数据量越来越大,时间越来越快,但是Ad-hoc的响应速度却始终是大数据的瓶颈...
2018-10-10 22:39:20 -

大数据等最核心的关键技术:32个算法
奥地利符号计算研究所的Christoph Koutschan博士在自己的页面上发布了一篇文章,提到他做了一个调查,参与者大多数是计算机科学家,他请这...
2018-10-10 22:37:21 -

Torch7 开源 PyTorch:Python 优先深度学习框架
PyTorch 是一个 Python 软件包,其提供了两种高层面的功能:使用强大的 GPU 加速的 Tensor 计算(类似 numpy)构建于基于 tape 的...
2018-10-10 22:35:27 -
高可用的大数据计算平台如何持续发布和演进
本文主要谈及大数据系统如何做系统迭代,以及大规模系统因为其大规模没有可能搭建对等的测试环境,需要进行在线测试方面的内容,更...
2018-10-10 22:34:17 -

基于Spark的公安大数据实时运维技术实践
本文首先对公安运维管理现状做了简要介绍,然后介绍公安实时运维平台的整体架构,再以交换机Syslog信息为例,详细介绍如何使用Flume+L...
2018-10-10 22:33:39 -

Spark的调度策略详解
Spark的调度策略 Spark目前有两种调度策略,一种是FIFO即先来先得,另一种是FAIR即公平策略。所谓的调度策略就是对待调度的对象进行排序,...
2018-10-10 22:33:01 -

深度学习利器:TensorFlow实战
深度学习目前已经被应用到图像识别,语音识别,自然语言处理,机器翻译等场景并取得了很好的行业应用效果。至今已有数种深度学习框...
2018-10-10 22:32:18 -

深度学习框架TensorFlow在Kubernetes上的实践
本文介绍如何通过TensorFlow实现深度学习算法,并将深度学习运用到企业实践中。...
2018-10-10 22:30:48 -

携程是如何把大数据用于实时风控的
携程作为国内OTA领头羊,每天都遭受着严酷的欺诈风险,个人银行卡被盗刷、账号被盗用、营销活动被恶意刷单、恶意抢占资源等。...
2018-10-10 22:30:15 -

分享:32个Hadoop问题及解决方案
今天讲一讲关于Hadoop的问题、原因以及解决方法。...
2018-10-10 22:29:04 -

一只特立独行的伪Hadoop批发商
在Hadoop圈子里面炒得最火热的当然莫过于Cloudera和Hortonworks之间的风风雨雨恩恩怨怨。但是今天我们暂且略去不表,聊聊另外一个批发商。它...
2018-10-10 22:28:29






