Lucene 倒排索引原理探秘 (2)
|
|
上篇文章 Lucene 倒排索引原理探秘 (1) 详细介绍了 Lucene 索引表的实现,内容涉及关于 Terms Index 以及 Term Dictionary 的剖析。 此文将继续剖析 Lucene 倒排索引实现的另一部分核心内容: 倒排表(Postings)。Lucene 的官方文档关于该部分内容的描述非常丰富,所以学习起来也相对轻松。 Postings 编码
开始之前先介解 Lucene 在 Postings 采用了两个关键的编码格式,PackedBlock 和 VIntBlock。PackedBlock 是在 VIntBlock
VIntBlock 是能够存储复合数据类型的数据结构,主要通过变长整型(Variable Integer)编码达到压缩的目的。此外 VIntBlock 还能够存储
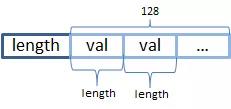
值得一提的是,VIntBlock 可以存储变长数据结构,如.doc 用它存储 DocID 和 TermFreq 时,由于在特定条件下 (TermFreq=1),Lucene 会省略 TermFreq 以提高空间占用率。Lucene 用一个 VInt 来表示 DocID,VInt 则用每个 Byte 左边第一个 Bit 来表示是否需要读取顺续到下个 Byte。也就是说一个 VInt 有效位是 PackedBlockPackedBlock 只能存储单一整数 (Integer/Long) 数组结构。这里主要介绍 PackedInts:它将一个 int[]打包成一个 Block。PackedBlock 只能存储固定长度的数组(Lucene 规定其长度为 128 个元素),它的压缩方式是将每个元素截断为一个预算的长度(length,单位是 bit),以达到压缩的目的。所以当长度 length 不是 8 的倍数时,会出现一个 byte 被多个元素占用的情形。 PackedBlock 需要把整个 int[] 的所有条目指定长度编码,所以 PackedBlock 只能选择 int[] 最大的数来计算长度,否则会让大数失真。反过来,PackedBlock 都选择 64 位,则会浪费空间,不能达到压缩的目的。
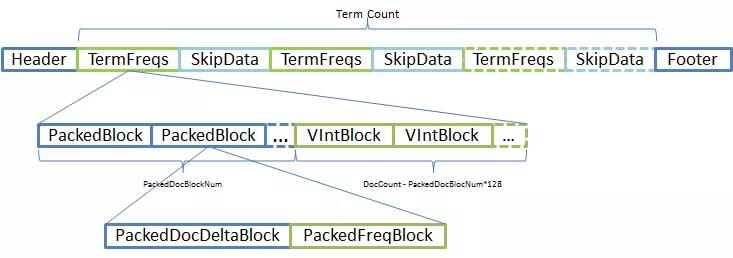
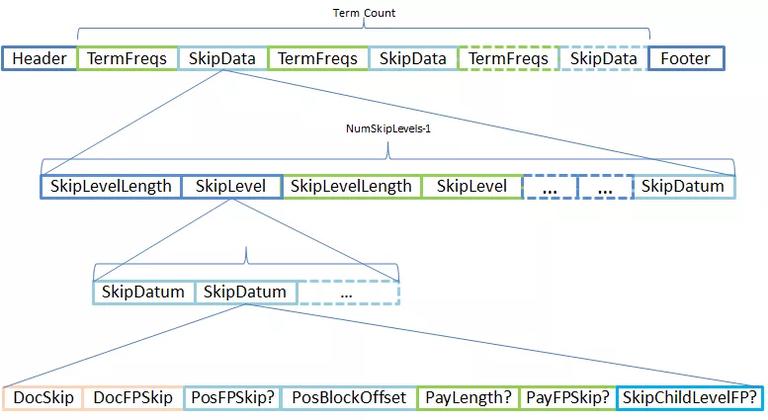
Lucene 预先编译了 64 个 PackedFormat 编码器和解码器,即针对 Long 以内的每种长度都数据都有自己的解码和编码器,以提高编解码的性能。 PackedPosDeltaBlock、PackedDocDeltaBlock 以及 PackedFreqBlock 都采用了 PackedInts 结构,它能存储的信息实际上是很有限的,只能存储 Int 的数组。所以在 PackedPosDeltaBlock 的时候,只能存储 position 信息,在 VIntBlock 则会存储更多必要信息,减少搜索时的 IO 操作。 这也是为什么需要将 DocId 和 TermFreq 拆分成 PackedDocDeltaBlock 和 PackedFreqBlock 两个 Block 存储的原因了。 定长是指 PackedBlock 限定了一个 Block 仅允许存储长度 128 的整型数组,而不是限定 Block 用多少个 Bytes 来存储编码后的结果。另外 Block 存储占用的大小,是按数组中最大那个数的有效 bits 长度来计算整个 Block 需要占用多大的 Bytes 数组的。也就是 Block 的每个数据的长度都是一样,都按最长 bits 来计算。 比如:(我们定义一个函数,bit(num) 用来计算 num 占用多少个 bits) 1. 数组中最大的是 1,那么 PackedBlock 的长度仅是 16Bytes。bit(1) * 128 / 8 = 16 2. 数组中最大的是 128,PackedBlock 长度则是 144 个 Bytes。bit(128) * 128 / 8 = 144 3. 数组中最大的是 520,PackedBlock 则需要 160Bytes。bit(520) * 128 / 8 = 160 简单总结一下,PackedBlock 相当于实现了向量化优化,Lucene 通常会将整个 PackedBlock 加载到内存,既可以减少 IO 操作数,又能提高解码的性能。相对而言 VIntBlock 则能够更丰富数据类型,比较适合存储少量数据。 Postings 文件格式说明进入正题,我们知道整个 Postings 被拆成三个文件存储,实际上它们之间也是相对独立的。基本所有的查询都会用.doc,且一般的 Query 仅需要用到.doc 文件就足够了;近似查询则需要用.pox;.pay 则是用于 Payloads 搜索(关于这个之前写一篇博客《Solr 迟到的 Payloads》,介绍了 Payloads 用法和场景 )。 Frequencies And Skip Data(.doc 文件)在 Lucene 倒排索引中,只有.doc 是 Postings 必要文件,即它是不能被省略的。除此之外的两个文件通过配置都是可以省略的。那么.doc 到底存储了哪些关键信息呢?直接上图:
这里画得不够清晰,每个 Term 都有成对的 TermFreqs 和 SkipData 的。换言之,SkipData 是为 TermFreqs 构建的跳表结构,所以它们是成对出现的。 TermFreqs — FrequenciesTermFreqs 存储了 Postings 最核心的内容,DocID 和 TermFreqs,分别表示文档号和对应的词频,它们是一一对应的,Term 出现在文档上,就会有 Term 在文档中出现次数(TermFreqs)。 Lucene 早期的版本还没有 PackedBlock 结构,所以 DocID 与 TermFreq 是以一个二元组的方式存储的。这个结构简单,有助于理解,但却并不准确。既然是想深入剖析,还是有必要还原真相的。
TermFreqs 采用的是混合存储 ,由 Packed Blocks 和 VInt Blocks 两种结构组成。由于 PackedBlock 是定长的,当前 Lucene 默认是 128 个 当用 VIntBlocks 结构时,还是沿用旧版本的存储方式,即上面描述的二元组的方式存储。所以说,将 DocID 和 TermFreq 当成一条数据的说法是不完全准确的。
Lucene 尽可能优先采用 PackedBlocks,剩余部分(不足 128 部分)则用 VIntBlocks 存储。引入 PackedBlock 之后,PackedDocDeltaBlock 跟 PackedFreqBlock 是成对的,所以它的写出来的示意图应该是如下:
每个 PackedBlock 由一个 PackedDocDeltaBlock 和一个 PackedFreqBlock 构成,它们都采用 PackedInts 格式。
例如,在同一个 Segment 里,某一个 Term A 在 259 个文档同一个字段出现,那么 Term A 就需要把这 259 个文档的文档编号和 Term A 在每个文档出现的频率一同记下来存储在 VIntBlock 结构相对复杂一些,它以一种巧妙的方式存储复杂的多元组结构。在.doc 文件中,用 VIntBlock 存储 DocID 和 TermFreqs 二元组。后面将介绍的 Positions 则用 VIntBlock 存储了 Postition、Payload 和 Offset 多元组, byte[] 和 VInt 多种数据类型。
这里每一个 PackedBlock 结构都包含了一个
在 VIntBlock 上如何存储 DocDelta 和 TermFreq? 如果设置了不存储 TermFreq 时,Lucene 将所有 DocDelta 以 Variable Integer 的编码方式直接写到文件里。当设置为存储 TermFreq 信息时,实际上,TermFreq 信息会被按需存储。Lucene 做了一个小优化,即当 TermFreq=1 时,TermFreq 将不被存储。那么原本 DocDelta(DocID 的增量)后面紧跟一个 Frequencies 的情况变得不再确定,因为压根无法知道 DocDelta 后面还有没有 TermFreq 信息。那应该如何识别 TermFreq 信息是否存在?Lucene 先把数值向左移动一位,然后用最右的一个 Bit 的标记是否存储 TermFreq。最后右边的一个
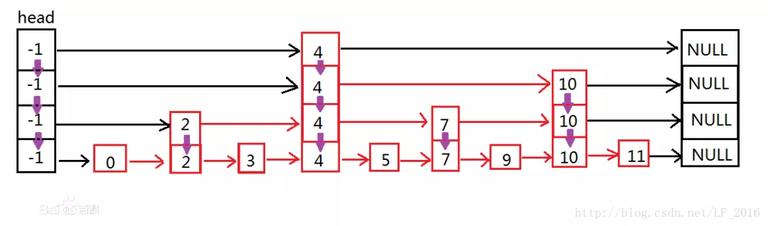
左移一位,实际上等同于 DocFreq=1 时,Lucene 做一个叫 Singletion(仅出现在一个文档中)的优化,此时就没有 TermFreq 和 SkipData。因为 TermFreq 等同于 TotalTermFreq(上篇文章介绍过,存储在.tim 的 FieldMetadata 上)。 Multi-level SkipList — SkipDataSkipData 是.doc 文件核心部件之一,Lucene 采用的是多层次跳表结构,首先我们先预热一下 SkipList 的逻辑结构图,最后剖析 Lucene 存储 SkipList 的物理结构图。下图 (源自网图) 很好的描述了 SkipList 的结构:
跳表的原理非常简单,跳表其实就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。首先在最高级索引上查找最后一个小于当前查找元素的位置,然后再跳到次高级索引继续查找,直到跳到最底层为止,这时候以及十分接近要查找的元素的位置了 (如果查找元素存在的话)。由于根据索引可以一次跳过多个元素,所以跳查找的查找速度也就变快了。 ——— 百度百科 将搜索时耗时转嫁给索引时,这就是 Lucene 索引的“空间换时间”的基本思想。为此 Lucene 为 Postings 构建 SkipList ,并把按层级将它系列化存储。第一个 SkipLevel 是最高,拥有最少的索引数。 Lucene 在索引时构建了 SkipList,在 Segment 中每个 Term 都有自己唯一的 Postings,每个 Postings 都有需要构建一个 SkipList,这三者是一一对应的。所以画出来结构图如下:
除了第 0 层之外所有 SkipLevel 的每个跳表数据块(SkipDatum)会存储了指向下一个 SkipLevel 的指针。图中 SkipChildLevelFPg 带 通过 SkipList 可以找到 DocID 和 TermFreq 之外,还能找到 Positions、Payloads 和 Offsets 这三部分信息。因此,在搜索时通过 SkipList 可以快速定位 Postings 的所有相关信息。 关于 Lucene 构建 SkipList 的几点细节 (Lucene 规定 SkipList 的层级不超过 10 层): 1. 第 0 层,SkipList 为每个 Block 增加索引,所以 VIntBlock 不在 SkipList 上。 2. 第 9 层,SkipList 的第一个节点是在第 89 (227)Block。(这个数确实有点大)
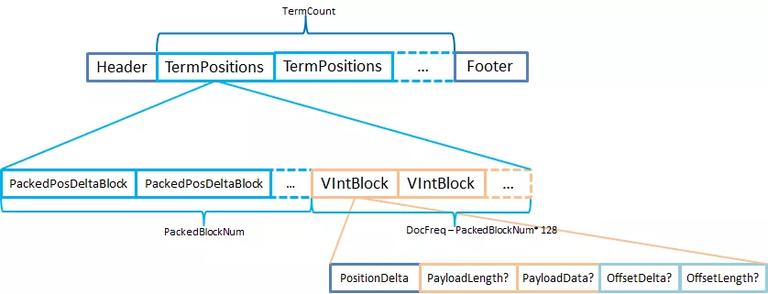
3. 第 n 层,SkipList 的第 m 个节点的位置是第 跳表的第一层是最密的,越高层越稀疏。按层级从低到高依次系列化为写入.doc 的 SkipData 部分。换言之,SkipDatum 个数越多,SkipLevelLength 则会越大。 SkipLevelLength 说明当前层次 Skip 系列化之后的长度,SkipLevel 是包含该层的所有节点的数据 SkipDatum。SkipDatum 包含四部分信息,doc_id 和 term_freq、positions、payloads、以及下一层开始的位置(是第 N 层指向第 N-1 层的前一个索引)。 SkipList 主要是搜索时的优化,主要是减少集合间取交集时需要比较的次数,比如在 Query 被分词器分成多个关键词时,搜索结果需要同时满足这些关键词的,此时需要将每个 Term 对应的 DocId 集合进行析取操作,通过跳表能够有效有减少比较的次数。 Postitions(.pos 文件).pos 文件存储所有 Terms 出现文档中的位置信息。为了更好的搜索性能,Lucene 还在 VIntBlock 上存储了部分 payloads 和 offsets 信息。实际上只有 VIntBlock 才有能力来存储复杂的数据结构,PackedBlock 是不具备这样的能力的。具体请参考下面的示意图:
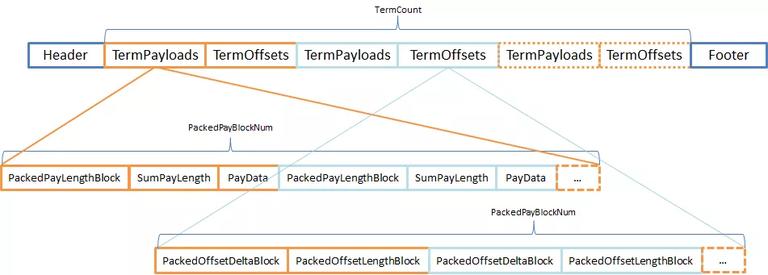
Lucene 把同一个 Term 的所有 position 信息存储在同一个 TermPositions 上,并没有逻辑或者物理上的划分。将在一个文档里出现的所有位置信息,按出现的先后顺序依次写入。 关键在于,position 与 TermFreq 并不是在一维度上,TermFreq 的数值就是 position 的个数。也就是说,通过.pos 文件无法知道每个 position 的具体含义,PostingsReader 通过.doc 文件的 DocID 和 TermFreq 信息才能算出 Postition 的是在哪个文档上的哪个位置。 Payloads and Offsets(.pay 文件)Payloads,可以理解为 Term 的附加信息,它是与 Term 成对出现的,类似于 Map。在用法上也是如此,Payloads 的信息需要用 byte 数组存储,所以在 TermPayloads 并不能用 PackedBlock 结构来存储。TermOffsets 由 2 个 int 来表示 Offset 的开始位置和长度,可以将它们拆成两个等 size 的 int[],因此可以用 PackedBlock 存储。如下图:
总结开篇先学习了 Lucene 用于存储 Postings 的两种结构,PackedBlock 和 VIntBlock。PackedBlock 是 Lucene4.0 引用的,它的核心就是一个 int[],为 Postings 提供向量化优化,VIntBlock 也是一种很巧妙且优雅的结构,能存储复杂的类型。
而后,在介绍.doc 文件格式的同时,又对上面的两大结构深入剖析,了解这两个结构是理解 postings 的基础。接下来剖析了.doc 文件上采用的 SkipList 数据结构,主要是搜索时集合间 Lucene 倒排索引部分内容到这里全部结束,包含很多优雅的设计和巧妙的结构,其中蕴含的 Lucene 设计之美,值得我们反复研读。 |

时间:2019-07-31 14:03 来源: 转发量:次

声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。