「AI语音评测」技术简述与应用层级
编辑导语:随着科技的发展,AI人工智能已经运用于我们的学习生活中;语音测评基于在线教育场景,使用语音识别、特征提取、声学模型等技术,提供成人和儿童的口语发音评测;本文作者分享了关于AI语音评测的技术简述与应用层级,我们一起来看一下。

一、前言
「AI语音评测」技术,指的是针对口语发音水平和差错,进行自动评价、检错并提供指导纠正的技术。
该技术经过几十年的发展,在中英文发音标准程度、口语表达能力等评测任务上已经超越了人类口语评测专家水平,目前该技术被普遍使用在中英文的口语评测和定级中。
接下来我们会讨论:
- 「AI语音评测」技术简述;
- 「AI语音评测」多维度应用层级。
二、AI语音评测基本技术简述
1. AI语音评基本规则
对于AI语音评测技术,目前相对流行的是基于DNN-HMM的声学模型,获得音素级别的解码结果以及单词和音素级别的强制对齐结果的方法。
音素:根据语音的自然属性划分出来的最小语音单位。
DNN-HMM:深层神经网络-隐藏马尔科夫模型(Deep Neural Network-Hidden Markov Model),是目前相对流行的声学模型。它的出现基本替代了之前的GMM-HMM模型。
简单的说,能够对音素、单词、句子、段落等多个级别的发音情况进行评价和指导反馈;测评维度包括发音准确度(音素/声调)和流利度、语调、断句、完整度等。
使用该技术方法须满足以下条件:
- 开发前确定针对的评测语种(如英语、日语、德语等);
- 以评测语种母语者标准语音为蓝本;
- 针对评测发音特点设计评测维度;
- 针对学习者母语(如汉语)发音特点定位可能存在的缺陷。
可以得到的结果:
- 段落、句子、单词、音素多个级别维度的,包括语调、断句、完整度、 流利度等多个方面的指导反馈;
- 针对各个级别和维度的分项和综合得分。
2. AI语音评测基本原理
1)整体架构
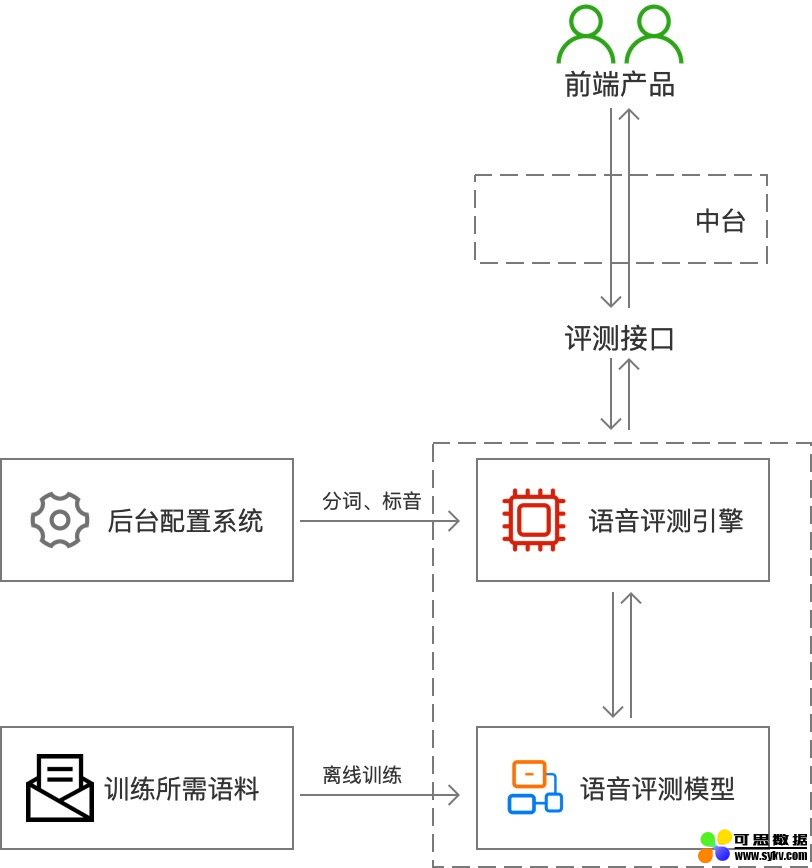
流程:
- 用户根据给定的文本生成语音;
- 前端产品通过「评测接口」上传音频至「语音评测引擎」;
- 引擎以「语音评测模型」为基准,通过解码计算处理得到评测结果;
- 通过「评测接口」将评测结果返回至用户。
几个概念:
- 语音评测引擎:AI评测解码和计算的核心模块,通过语音识别(ASR)解码转译,与给定的文本强制对齐,通过不同维度的算法得出指导反馈和评测得分。
- 后台配置系统:语音评测前,需将给定的文本拆分成独立的单词或单音/音素并存储在后台配置系统中,为语音评测引擎提供对齐标准。
- 语音评测模型 & 训练所需语料:使用评测引擎前,需使用适量的语料离线训练形成语音评测模型,该模型是引擎进行解码计算处理的依据。
2)语音评测引擎原理
通过对整体架构的解读,我们不难发现很大部分工作都是由「AI评测引擎」完成的,接下来我们再简单了解一下评测引擎内部的流程和原理。

流程:输入声音讯号→ASR语音识别→多维度算法→反馈&得分。
输入声音讯号:通过接口将音频文件传输至后台语音评测引擎。
语音识别(ASR):ARS(Automatic Speech Recognition)是一种将人类语音转换为文本的技术。在这里的作用是将上传的音频内容转换成文本。
ASR过程是相对复杂的,这里简述其中几个步骤:
- 预处理:在开始语音识别前,需把首尾端静音切除,降低对后续步骤造成干扰,这一般称作VAD;这可以减少音频数据长度,提高识别精准度;如果预处理内容全部在云端,“信号处理”(降噪)也会在预处理阶段进行。
- 特征提取:特征提取将提取出来的特征作为参数,为模型计算做准备。简单理解就是语音信息的数字化,然后再通过后面的模型对这些数字化信息进行计算;语音文字识别情况下,主要是提取音素特征;其他情况如情绪识别,还需要提取响度/音高等参数。
声学模型(AM)/语言模型(LM)/词典(lexicon):
- 声学模型(AM):将声学和发音学技术进行整合,以特征提取模块提取的特征为输入,计算音频对应音素之间的概率;简单说就是把声音转成音素,类似把声音转成拼音;优化声学模型同时也需要适量的音频数据进行训练。
- 语言模型(LM):将语法和字词知识整合,计算字词在句子里出现的概率,简单理解就是计算几个字词组成句子的概率。
- 词典(lexicon):词典(lexicon)就是发音字典,中文里就是拼音与汉字的对应,英文里就是音标与单词的对应;其目的是根据声学模型识别出来的音素,来找到对应的单词,在声学模型和语言模型建立桥梁,将两者联系起来。

通过以上三者的结合计算,得到音频的解码和音频转译文字后的强制对齐结果,此结果用于多维度评测反馈和得分的计算。
评测结果算法:
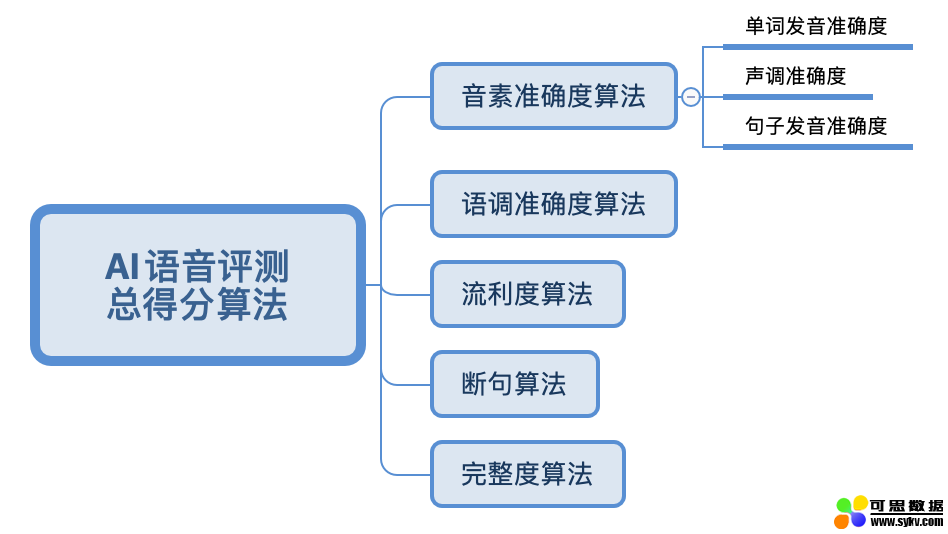
评测结果是多维度的,包括音素、语调、流利度、断句、完整度等内容;但不同语种下评测维度是不同的,这与语言的特性有关,因此需要针对不同语种单独定制评测的维度。
以日语为例,不仅包括上述常规的语调,流利度等常规维度,同时也有单词音调、日语音拍、音高等其他维度的分析。
至于每个维度的具体算法,就牵涉的一些技术性更强和数学算法的内容了,因此这里不做过多解释。如果可能,我们以后单独探讨不同语种下不同维度算法的原理。
三、「AI语音评测」多维度应用层级
任何AI技术的进步,应该体现在更加适应人类的思维方式,而不再感觉像是一个API终端。
接下来围绕「AI语音评测」罗列几个维度的应用层级,看看它具体能做什么。
1. 评测主体维度
评测主体维度是最容易被理解的,具体分为以下几个维度:
- 层级一:音素,例如音标中的[a:],[æ]等。
- 层级二:单词/单音,如[英语字母ABCD]或[单词good],[日语假名あいう]或[单词お母さん]等。
- 层级三:句子,由多个独立的单词拼接而成。
- 层级四:段落,由多个独立的句子拼接而成。
- 层级五:文章,由多个独立的段落拼接而成。
针对以上五个层级,「AI语音评测」都给出了对应的解决方案,一般情况下该维度发展至句子层级即可满足大部分需求。
2. 指导反馈维度
指导反度维度是「AI语音评测」的核心维度,该维度直接展示了不同层级中指导反馈内容角度和粒度。
让我们以一个用户练习口语场景为例,每进阶一个层级,都应降低用户的思考负担,让用户得到更接近“口语教师”的指导反馈。
层级一:仅提供用户发音和标准发音回放功能
层级一与「AI」技术无任何关系,几乎所有的评测工作都留给了用户;用户手动播放每一组自身读音与标准读音,用听觉感知发音差距。
本层级用户体验:除非很简单的发音,否则大多用户对发音细节、进步程度和改进点感到茫然。

仅提供发音回放功
层级二:提供用户发音评分
层级二是个巨大的进步,因为这一步进入了「AI」领域;用户将给定文本的发音上传至评测引擎,引擎将评测得分反馈至用户,除此之外再无其他反馈。
在很多情况下这只是一个临时的解决方案(一般受研发能力或产品阶段目标的限制),但无论是产品过渡还是功能尝试都可能是当时最优解决方案。
本层级用户体验:用户收到了量化的反馈,也可以感知到一些自身的进步,但用户仍不知道怎样从70分变成100分。

层级三:细粒度评分反馈
层级三是在层级二的基础上,增加了细粒度的评分反馈。
包括以下粒度的评分:
- 每个音素的评分;
- 每个单音/单词中发音和声调的单项评分和整体评分;
- 如果是句子,包括完整、流利、发音、语调、断句等多个维度的评分。
层级三评测已经进入到细粒度(音素)级别,但除了细粒度的评分结果外,没有其他内容的反馈。
本层级用户体验:用户可以更精准定位到发音问题所在,但对于“纠正发音问题”还差一步。

层级四:细粒度指导反馈
层级四是在层级三的基础上,增加了更加细致精确的指导反馈。
为了更好理解这种指导反馈,这里举两个例子:
① 单词示例:英语文本grandmother[ˈɡrænmʌðər]。
如用户实际发音为[ˈɡrændmɔːdər],则可给出的指导反馈有:
层级三中所有的单词得分反馈。
层级四优化的单词反馈:
- “[m]的发音前不应该有[d]”;
- “[ʌ]的发音不应该读成[ɔː]”;
- “[ð]的发音不应该读成[d]”;
示例小结:以上反馈直接展示了音素级别的错误与正确读法的差别。
② 句子示例:英语文本「I want to go to school.」。
如用户实际发音为「I…want…to go go?」,则可给出的指导反馈有:
层级三中所有的句子得分反馈。
单词示例①中单词示例的每一个单词音素的反馈。
层级四优化的句子反馈:
- 完整度:遗漏词汇—to & school,复读词汇—go;
- 语调:应该为降调,不应该为升调;
- 流利度:语速过慢,应加快速率;
- 断句:停顿过长—I和want之间,want和to之间;
示例小结:以上反馈多维度展示了句子中错误与正确情况的差别。
本层级用户体验:用户已经可以精确定位问题并且得到具体解决方法;但目前为止依旧还是文字式的反馈,无论用户是否懂得音素(音标),自然语音的反馈无疑更加容易接受。
层级五:TTS结合
层级四在语音评测指导反馈方面几乎达到了顶级,再结合自然语音的反馈会更加契合口语学习的场景。
TTS技术简述:TTS(Text To Speech,文本转语音)是语音合成应用的一种,它将文字或者文件转换成自然语音输出,主要的技术框架包括“MARY”、“SpeakRight Framework”、“Festival”、“FreeTTS”等。
在层级四中,我们举例了英语单词grandmother[ˈɡrænmʌðər]误读为[ˈɡrændmɔːdər]的情况。
结合TTS技术后,我们可以给出以下自然语音提示:
- 自然语音:“[m]前不应该有[d],请注意这个d不发音”;
- 自然语音:“[ʌ]不应该读成[ɔː],请注意长大嘴巴,不要发长音”;
- 自然语音:“[ð]不应该读成[d],请注意这是咬舌音”;
本层级用户体验:在有足够细粒度指导反馈的前提下,TTS的结合让评测结果已经基本达到了“口语教师”级别。

示例:结合TTS更直观的反馈问题(此处有发音指导)
3. 与其他技术结合的可能性
通过「AI语音评测」技术,在给定文本的前提下,已经可以给出非常精准的指导反馈了;但如果上升到口语学习级别,还是远远不够的——毕竟口语不是简单的发音练习,语境、语法、迅捷响应等其他方面也是非常重要的。
接下来我们简单提出一些与其他技术结合或者优化的猜想尝试解决口语学习的难题。
1)语境模拟:与「交互AI」结合
根据已成熟和可实现的交互AI技术,基于用户提供的口语语音内容,反馈的层级包括:
- 层级一:仅提供固定回复(非AI);
- 层级二:提供非固定回复,可智能判断回复优先级;
- 层级三:主动式对话介入,能主动引起/转换关联话题
- 层级四:能够反馈用户语音场景契合度(用户内容是否符合当前语境)。
小结:「交互AI」是一个非常庞大的体系,但应用的广泛性正在使其形成产业化规模化,中小企业也能够对接高级「交互AI」也许很快就能实现。
2)语法:与「AI语法检查」结合
AI语法检查技术是指将提供的句子或段落进行语法检查并指出语法问题和指导反馈;通过该技术,口语学习者可以获得语音内容语法方面的指导反馈。
举例1:给定文本「I want to fly to the Moon.」,如用户发音「I want to fly to Moon.」此时在提示语法检查应给予对应提示:
- 发音问题:“漏读—the”(AI语音评测结果);
- 语法问题:“Moon是唯一的,应在Moon前加冠词the”;
但在给定文本的情况下并不能完全体现语法检查的优势,一般在交互AI介入的场景下会更加合理。
举例2:
AI:「What is your dream?」,用户:「My dream is flying to Moon.」
结果反馈:
- 发音问题:…(AI语音评测结果);
- 语法问题:“Moon是唯一的,应在Moon前加冠词the”;
以此,用户可以在类真实语境下练习口语,并可以同时得到发音和语法两大方面的反馈。
3)AI引擎本地化
在我们的产品使用AI技术初期,一般会选择「前端产品调用AI接口——云端后台引擎计算——结果返回至前端产品展示」的模式,目的是尽量不影响产品主体功能和提高研发效率。
但随着AI在我们的产品中权重越来越高,用户对AI功能的效率要求日益严格——“零延迟响应”、“离线响应”逐步成为用户体验很重要的部分;如果我们的产品正被大量用户诉求高效率AI,AI引擎本地化就不得不提上日程了。
AI引擎本地化是指将之前已经在后台构建好的计算引擎迁移至前端产品中(前提是前端产品必须是有能力承载这些引擎的,如App或其他客户端,网页或小程序就比较困难了);迁移后在使用AI功能时,前端产品内部即可完成计算并给予反馈,从而实现了“零延迟/离线响应”的效果。
以「AI语音评测」为例,引擎本地化即是将原本在云端后台处理的“预处理”模块、“声学模型”模块和“声学处理”模块全部迁移至前端产品中。
但引擎本地化影响并不全是正向的,以下罗列了部分引擎本地化的优劣:
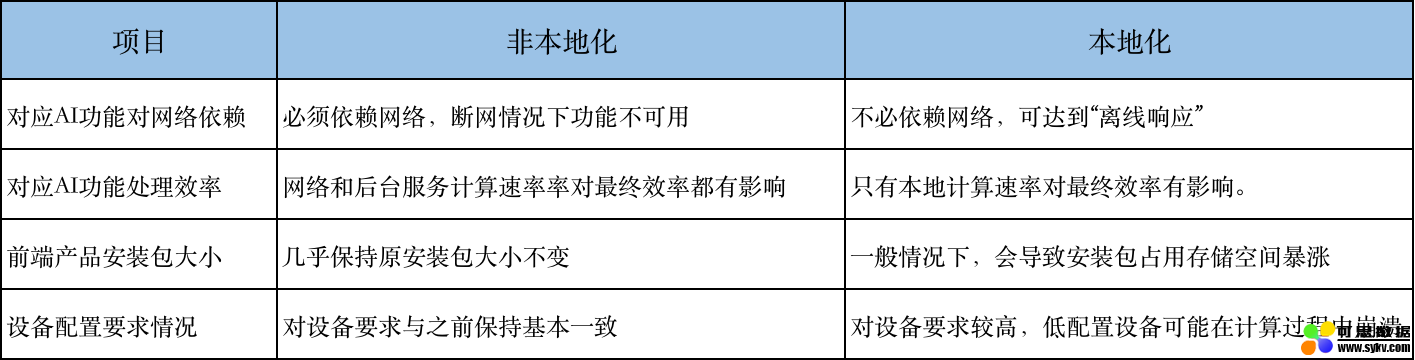
由此我们可以看出,AI引擎本地化需要根据产品实际情况来决定是否要进行,或者设置一系列的配置项来规避本地化带来的问题,如:
- 提取后台引擎核心模块进行本地化,非核心模块保留后台服务,大幅度提高响应效率;
- 自动检测低配置设备,对于低配置设备不运行本地化计算;
以上分别介绍了“交互AI”、“AI语法检查”、“AI引擎本地化”与「AI语音评测」技术的一些结合。
以上技术之间并没有绝对的依赖关系,也没有顺序差别,是否需要结合或者怎样结合完全依据对产品本身的需求分析。
当然也会有其他技术结合的可能(如自适应AI、表情识别AI),这里就不再一一列出。
四、总结
在上述讨论中,我们通过介绍「AI语音评测」技术和应用层级作为切入点,上升到口语学习并引出与其他技术结合的应用场景;相信通过AI技术的融会贯通,口语学习也终究会变得易如反掌。
尽管很多相关的AI技术目前还没有达到即插即用的程度,但他们中的大多数已经处于孵化或者初级阶段,“万物皆AI”的趋势已经不可逆转。
本文由 @产品汪 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。

时间:2020-10-18 10:20 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















