一张图实现3D人脸建模!中科院博士ECCV的新研究
通过一段视频,来重建人脸3D模型,没什么稀奇的。

但是,如果只有测试者的一张静态图片呢?
来自中科院模式识别实验室的博士生郭建珠和他的团队,提出了一种新的密集人脸对齐(3D Dense Face Alignment)方法。
新的3DDFA方法,最关键的核心,是3D辅助短视频合成方法,它能模拟平面内和平面外的人脸移动,将一幅静止图像转换为短视频。
由此来完成模型的识别和训练。
郭同学的这篇论文Towards Fast, Accurate and Stable 3D Dense Face Alignmen,已经被ECCV 2020收录。
3DDFA-V2:一静一动
这其实是作者发布的3DDFA的第二个版本,两年前,团队已经发表了3DDFA的第一版。
新版本具有更好的性能和稳定性。此外,3DDFA_V2集成了快速人脸检测器FaceBoxes,取代了原来的Dlib,同时还包括由C++和Cython编写的简单3D渲染。
3DDFA能做到“动若脱兔”(面部特征识别、对齐):

还有动态的3D人脸建模:

3DDFA的另一面,“静若处子”(静态照片3D人脸重建):

除了一静一动,3DDFA还能根据照片对人物姿态做出简单估计:

进行深度图像估计:

还能对图像的PNCC、PAF特征提取:
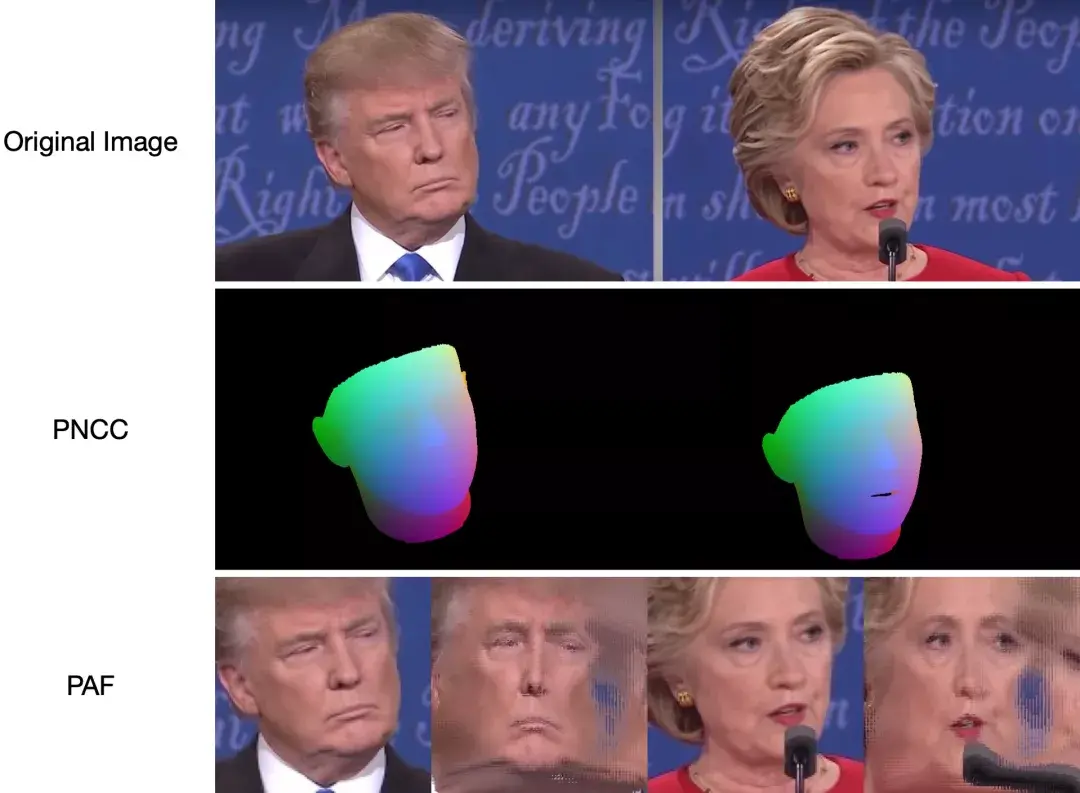
3DDFA-V2可以称得上是一个功能十分强大的面部3D重构工具,同时还集合了其他很多功能。
那么,3DDFA-V2最关键的照片转小视频的功能是如何实现的呢?
3D辅助短视频合成
3D密集人脸对齐方法,需要在在视频上运行,它提供相邻帧间提供稳定的3D重建结果。
所谓稳定,是指在视频的相邻帧中,重建的三维图像的变化应该与真实物体的细粒度移动保持一致。
然而,现有的大多数方法都无法满足这一要求,也难以避免随机抖动的影响。

在二维人脸配准中,时空滤波等后处理是减少抖动的常用策略,但会降低精度,造成帧延迟。
此外,由于没有公开的三维密集人脸配准的视频数据库,采用视频进行预训练的方法也行不通。
那么还有其他什么办法能改善静态图像转化视频的稳定性?

3DDFA-V2中采用的是批处理级的3D辅助短视频合成策略。
将一幅静态图像扩展到多个相邻的帧,由此形成一个mini-batch的合成短视频。
一般来说,一个视频的基本模式可以分成:
1、噪声。我们将噪声建模为 P(X)=x+N(0,2), 其中 E=a2I
2、运动模糊。运动模糊可以表示为 M(X)=K*x,其中K是卷积核(算子*表示卷积)。
3、平面内旋转。给定两个相邻帧 xt和 xt+1,平面 从xt和 xt+1变化可以描述为相似变换 T(·)
其中Δs为比例扰动,Δθ为旋转扰动,Δt1和Δt2为平移扰动。
由于人脸具有相似的三维结构,同理也能够合成平面外的人脸移动。
人脸剖面F(-)最初是为了解决大姿势的人脸对准问题而提出的,它被用来逐步增加人脸的偏航角∆φ和俯仰角∆γ。
具体来说,以小批量的方式对多张静止图像进行采样,对于每张静止图像x0,对其进行稍微平滑的变换,生成一个有n个相邻帧的合成视频:
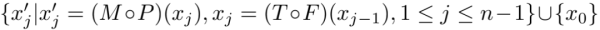
3D辅助短视频合成帧中,相邻两帧如何合成:

如何上手
目前,团队已经将3DDFA-V2开源,且安装使用都非常简单。
安装指令:
- git clone https://github.com/cleardusk/3DDFA_V2.gitcd 3DDFA_V2
安装完成后,需要构建cython版本的NMS和Sim3DR:
- sh ./build.sh
运行演示:
- # running on still image, four options: 2d_sparse, 2d_dense, 3d, depthpython3 demo.py -f examples/inputs/emma.jpg
- # running on videospython3 demo_video.py -f examples/inputs/videos/214.avi
- # running on videos smoothly by looking ahead by `n_next` framespython3 demo_video_smooth.py -f examples/inputs/videos/214.avi
例如,运行
- python3 demo.py -f examples/inputs/emma.jpg -o 3d
将给出以下结果:

跟踪人脸动作的实现只需通过对齐即可。
但如果头部姿势偏角大于90°或运动太快,则对齐可能会失败。可以考虑使用阈值来精细地检查跟踪状态。
加载完成后,可以用任意图像作为输入,运行算法:
- python3 main.py -f samples/test1.jpg
如果你能在终端看到输出日志,这说明成功运行,等待结果即可:
- Dump tp samples/test1_0.plySave 68 3d landmarks to samples/test1_0.txtDump obj with sampled texture to samples/test1_0.objDump tp samples/test1_1.plySave 68 3d landmarks to samples/test1_1.txtDump obj with sampled texture to samples/test1_1.objDump to samples/test1_pose.jpgDump to samples/test1_depth.pngDump to samples/test1_pncc.pngSave visualization result to samples/test1_3DDFA.jpg
3DDFA-V2对计算机的软硬件都有一些要求:
PyTorch 0.4.1版本以上
Python 3.6版本以上(带有Numpy、Scipy、Matplotlib库)
系统:Linux或macOS
研究团队推荐的硬件条件为一块英伟达GTX 1080 GPU和i5-8259U CPU。
当然,除了老黄的卡,你也可以直接在谷歌Colab上体验!
如果这个工具对你有帮助的话,赶紧来试试吧!
3DDFA-V2谷歌Collab: https://colab.research.google.com/drive/1OKciI0ETCpWdRjP-VOGpBulDJojYfgWv
Github项目地址: https://github.com/cleardusk/3DDFA_V2

时间:2020-09-02 23:27 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















