计算机视觉注释:工具,类型和资源

在提供机器视觉的AI系统的背后,您将找到一个计算机视觉注释工具。这些工具是获取原始图像数据并将其转化为机器学习模型的训练数据的关键。注释工具可帮助自动驾驶车辆识别交通状况,帮助仓库机器人区分存货,并帮助无人驾驶飞机导航到地址。
在计算机视觉中,注释工具用于各种不同的应用程序。尽管面部识别,物体检测和医学成像都可以在计算机视觉的保护下使用,但每种方法都需要使用不同的注释来实现其目标。知道作业的注释类型是选择正确工具的关键。
在本文中,我们将研究计算机视觉AI的常见图像批注类型,以及用于启动自己的项目的工具和资源。

2D边界框:
在图像,形状或文本上绘制边界框以定义其X和Y坐标。这是训练机器识别不同类型对象的开始。例如,边界框可以帮助自动驾驶车辆区分行人和车辆。对于对象识别和碰撞检测等任务,它们也是必不可少的。
在训练计算机视觉时,注释工具允许人工注释者移动,变换,旋转和缩放边界框。它们还允许分类。高质量注释工具应易于使用且具有高度的灵活性。一个好的注释工具将包括一些功能,例如放大图像和用于定义盒子位置的十字线。这些生活质量的细节使注释者可以更快地工作而不牺牲准确性。
如上所述,包围盒在自动驾驶汽车中很常见。它们还帮助无人机定位地标,并帮助工业仓库机器人技术识别各种不同的物体。

3D边界框/长方体:
3D边界框(也称为长方体)为传统的边界框增加了深度的额外维度。为计算机视觉创建对象的3D表示意味着使机器能够区分对象在3D空间中的位置及其体积。
边界框通常从锚点开始,锚点位于对象的边缘。通过用线条填充这些锚点之间的空间,可以在对象周围创建3D框或长方体。然后,生成的3D表示将显示深度以及位置。
3D边界框在机车机器人技术和自动驾驶汽车中很常见,在这些领域中,仅知道对象存在是不够的。当机器需要了解对象的位置和大小时,3D边界框比传统的2D边界框提供更高的准确性。

地标注释:
地标注释的工作原理是在图像上放置点以标记该图像内的对象。这种标记的范围从单点到注释小对象,再到多点以概述特定细节。用于地标注释的图像可以包括地图,面部,物体和对象。
在计算机视觉项目中,界标注释最常见于准确的面部识别。通过允许多个点来区分唯一面孔的形状和细节,机器可以学会更准确地将一个面孔与另一个面孔区分开。这可以用于解锁手机,识别社交媒体应用程序中的面孔等。
除面部识别外,地标注释还可以帮助进行视频分析。例如,Lionbridge与客户合作,跟踪多个视频帧中某些身体部位的运动。在此项目中,该工具允许多层分类非常重要,例如“肘–左”和“踝–右”。这种灵活性允许进行更高质量的分析。
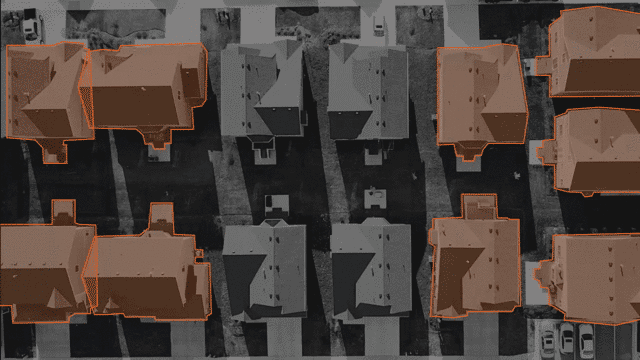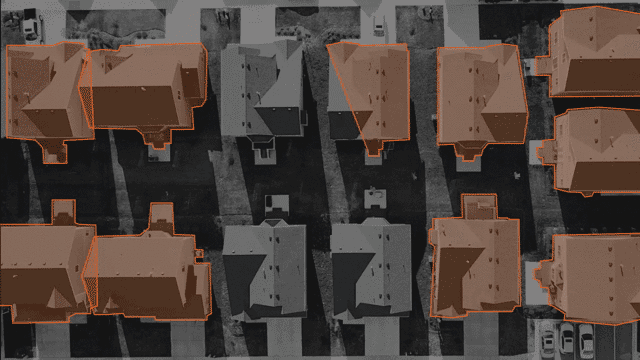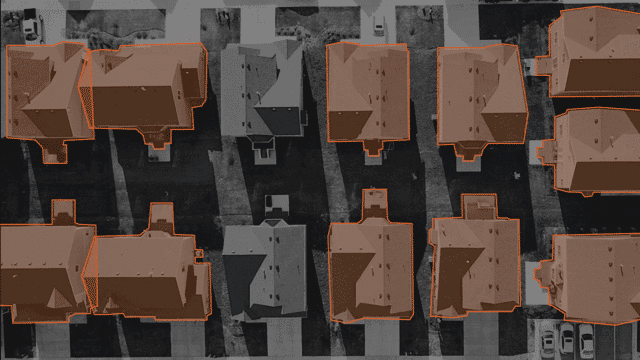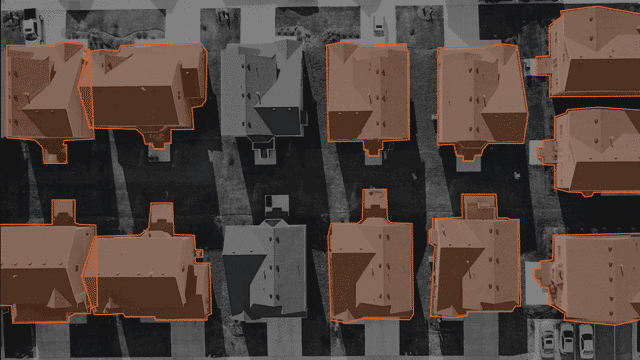
多边形:
尽管边界框对于许多计算机视觉AI任务来说是不错的选择,但有时它们缺少形状不规则物体所必需的精度。例如,考虑路牌或建筑物形状。在这些情况下,多边形注释是一种更准确的解决方案。与具有固定矩形形状的边界框不同,多边形注释允许使用多个角度和线。这意味着注释者可以在某些点上单击并更改方向以最好地坚持对象的形状,而不是在建筑物上绘制框。
多边形注释对航空成像很有帮助,在这种情况下,无人机或卫星从高处定位特定对象通常很重要。对于自动驾驶汽车,当您需要高水平的细节时,多边形注释会有所帮助。这样的一个例子是在繁忙的交通中区分各种对象。
在进行用于计算机视觉的多边形标注时,一个好的标注工具将提供使工作更轻松的方法。寻找诸如缩放和平移控件之类的功能以支持注释者的准确性,或者为注释者之间的一致性使用多遍选项以确保质量。如果您需要在注释中记录文本,例如路牌或广告招牌,请寻找是否可以为每个注释设置可选或强制性注释的功能。
计算机视觉注释工具的其他用途:
以上是计算机视觉最常用的注释类型的摘要,但绝不是唯一的注释类型。在下面,我们列出了您可以在注释工具和平台中找到的其他注释类型。如果您想进一步了解它们的工作方式及其用途,请随时与我们联系。

计算机视觉注释工具和资源
下面我们列出了用于计算机视觉项目的可用工具和资源。您还可以找到有关数据收集,查找数据集和数据标记方法的建议。
用于计算机视觉的图像注释工具:本文列出了24种最佳的可用图像注释工具。它包括通用的开源软件,在线协作工具,数据服务提供商和众包服务。对于了解当前可用的各种工具而言,这是一个有用的资源。
如何查找数据集:互联网包含大量用于机器学习项目的数据,而数据集存储库(例如Kaggle和Google Dataset Search)为开源数据集提供了很好的起点。但是,如果无法在线找到所需的确切数据,则需要内部或在数据服务提供商的帮助下创建自定义数据集。本文将深入研究每种数据集何时适用,并提供入门建议。
机器学习的数据标记方法:根据计算机视觉模型的性质,数据标记既费时又复杂。一些图像识别系统可能只需要在特定对象周围绘制边界框,而另一些图像系统可能需要界标注释或语义分割,这可能会更加复杂。本文介绍了各种数据标记方法,并提供了何时使用每种方法的示例。
结论
对于机器学习模型,计算机视觉的准确度可归结为数据集的准确度。这意味着要确保您拥有一个值得信赖的注释工具,以及一组可靠的注释器来使用它。
该Lionbridge的注解平台旨在应对这一挑战。这是一个灵活的工具包,可为用户提供自由和控制权,以确保满足他们的项目需求。我们设计了易于使用的平台。项目易于创建和自定义,并且可以随着项目的发展进行迭代。它也经过精心设置,因此项目经理可以在一个平台上监督一组跨各种项目类型的注释器。
我们为您的每个项目提供全面的项目管理支持和质量保证。如果您需要其他帮助,我们还可以为特定作业推荐注释器。如果您正在寻找用于机器学习的图像注释解决方案,或者只是想更好地了解该领域,请联系。

时间:2020-08-13 00:14 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















