人工智能数据标注:文本标注必须了解的知识点
最近在跟几个文本相关的项目,所以本篇文章就跟大家聊聊数据标注员必须了解的NLP中基础的知识点。在文本标注特点就是这几种标注需求变化最多的,也是最频繁的一种。不管是AI公司做需求的小伙伴,还是在标注公司进行标注的小伙伴都会碰到这样一个问题,就是临时定需求、临时改需求等等很让大家头痛。但是大家有没有想过其根源是什么呢?
文本标注的多样性的核心问题是因为我们博大精深的中文语义理解实在是太难了,对于不同场合的一句话就可以解读出不同的意思,那么就对刚开始做需求和标注的小伙伴产生了极大的困扰。开始去理解的时候可以想的天花乱坠,并且逻辑上貌似都可以说的通,给在实际工作中的大家造成了极大的困扰。那么我们到底如何去避免或者尽量减少这类的问题的发生呢?我从两个角度跟大家聊聊这个问题。
一.标注数据的AI应用场景
AI的应用是我们做任何标注需求或者进行标注必须要考虑到的需求根基,如果标注需求或者标注思考过程脱离场景,那么需求制定和标注将没有任何意义,这个根本的原因不是你标注对与错的问题,而是目前阶段算法局限性的问题导致的。所以场景是大家需求开始的地方。
我举一个例子也是我前一段时间参与的一个文本情感分析的一个项目。
1.数据来源:某宝、某猫、某狗、某京类的电商平台的用户留言。
2.需求客户公司:某洁等这种大品牌日化用品公司。
3.想解决的问题:分析用户在使用过程中的反馈,从而对该公司旗下的品牌在全流程上(从生产到物流到使用完后的体验)有哪些需要改进的地方。
所以可想而知在拿到数据的第一阶段是很头痛的,你会发现维度太多了,而且种类也太多了,每种产品的留言也有可能是不一样的。那么我们就需要从更高维度去分析提出共性和基本处理原则。
所以我们可以从三个维度去考虑。
1.总体原则:这个标注过程中必须遵守的基本原则。
例如:最简原则/最小原则,可以理解成在分词过程中用到的最小颗粒度的分词方法。例:和平饭店,可以分和平饭店整体,也可以分为和平/饭店,那么在这里我们就分为和平/饭店。
2.特殊定义:在标注过程中特殊情况的处理方法。
例如:在分词当中可以遇到的一些专有名词,就不进行拆分等。
3.标注需求:对具体标注过程进行说明。
标注需求部分,我们还是进行两类的区分考虑。
a.词性的角度。
例如:标注的我们需要分为哪些,可以更好的贴切与我们的需求。在本次需求里我们要分析用户对产品的全流程的使用体验,那么能涉及到什么?留言会有什么?首先情感是必须存在的一类。那么什么可以哪些特征词可以表示出客户的情况呢?那么理解到了核心的问题点。特征词和情感词。
b.事件的角度。
什么是事件的角度?本次需求当中需要点会涉及到非常多种类的产品。但是不管什么产品都需要经过一个全流程的事件,最后产生用户反馈。那么在这个全流程过程中哪些点是可以影响用户体验的。这样这个事情的逻辑就出来了,例如:物流、包装、品牌等等。就可以根据实际情况去设定对应的事件了。
上面就是以一个实际的例子去分析了文本场景分析的一个过程,当这个过程梳理完成之后,大家就会发现待处理的数据的结果就会接近唯一值了。希望不管是AI公司制定需求的小伙伴还是标注公司做标注的小伙伴可以参考理解。
二.NLP相关的基础知识
这部分涉及到的内容会非常多,本篇文章仅仅是从标注需求的角度去对NLP的基础知识做一个分享。
1.NLP是什么?
NLP(Natural Langunge Possns,自然语言处理)是计算机科学领域以及人工智能领域的一个重要的研究方向,它研究用计算机来处理、理解以及运用人类语言(如中文、英文等),达到人与计算机之间进行有效通讯。所谓“自然”乃是寓意自然进化形成,是为了区分一些人造语言,类似C++、Java等人为设计的语音。
2.NLP知识点
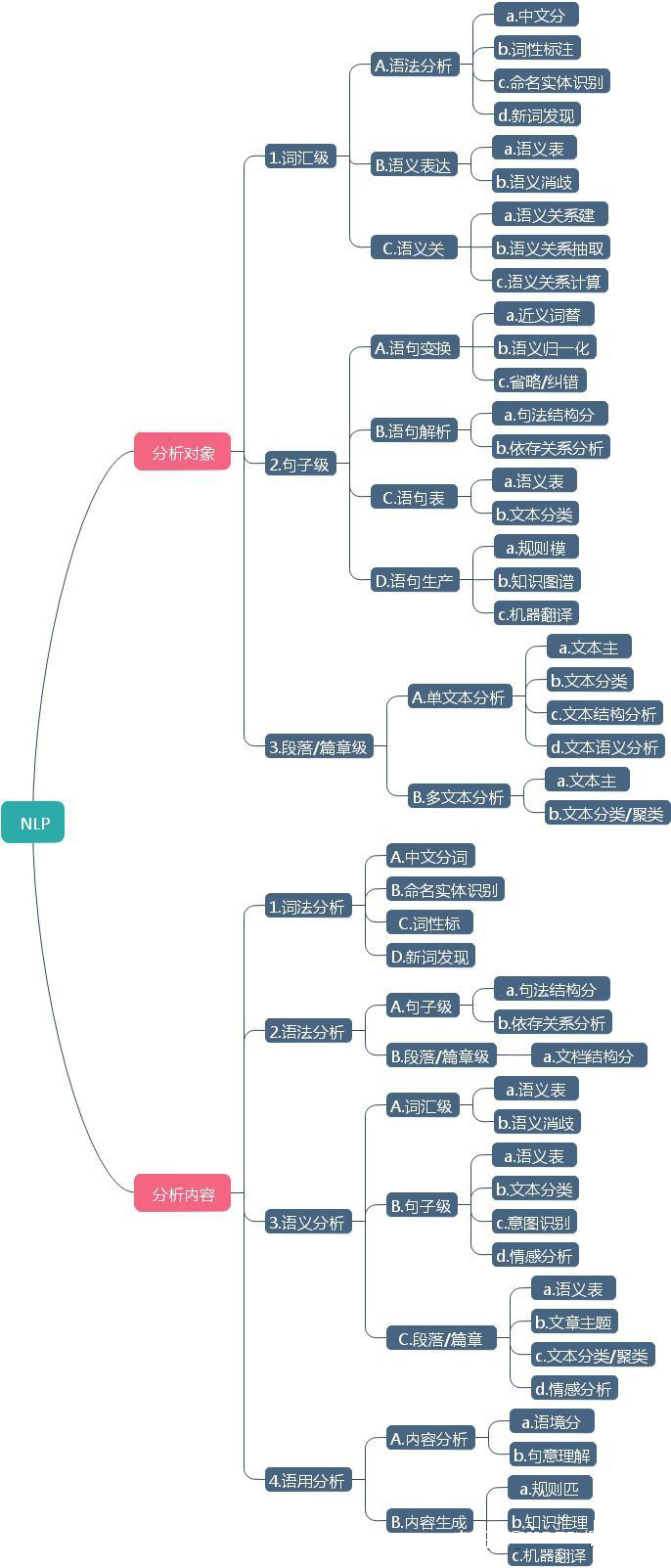
3.NPL在标注中的处理流程
A.获取语料(即语言材料,语料是构成语料库的基本单元。)
- 现成语料
在日常生活中的书籍、文档等等资料都可以整合处理后变成语料库来进行使用。
- 网上抓取语料
网上抓取语料,在互联网上每天都会产生大量的文本,例如微博、论坛、留言等等都是可以抓取获得经过处理作为语料库的。其特点就是容易获取且是电子版可以在抓取的时候直接转换成需要的格式。难点在于网上的文本数据的用法有可能跟我实际生活中有差别需要进行进一步的处理。
-
人工采集语料
对于特殊需求的语料只能进行人工采集,例如儿童的文本对话,日常生活中的对话等等。在特殊场景上应用基本上都需要人工进行采集,采集特点会根据需求场景进行规范语料内容,在特定的规范中发挥人本身在生活中的实际对话进行采集。这类采集目前阶段需求量还是非常大。
B.语料的处理
上面提到的不管是现成的语料、网上抓取语料还是人工采集语料都需要做进一步的处理之后才能应用,那么语料的处理过程往往会占据完整的中文自然语音处理工程中的50%-70%的工作量。基本上需要经过如下4个方面数据清洗、分词、词性标注、去停用词进行语料的处理工作。而这4个方面大部分需要进行人工进行处理。
-
语料清洗
语料清洗一般可以从几个维度进行。- 数据格式清洗(不符合需求格式的数据进行清洗)
- 脏数据清洗(对我们不需要的数据进行清洗)
- 数据内容清洗(例如我们只需要文章标题,不需要作者就需要根据实际需求进行对已有的数据进行清洗)
- 分词
分词是对文本分析非常重要的一步,但分词方法又有很多种,所以我们就需要根据我们项目需求,提前设定好分词的颗粒度、以及一些特殊词的分法。以免后期处理产生歧义。这一部分可以结合分词算法来加快数据标注的进度。但是分词算法也有非常多,需要大家根据大家的需求进行选择。如:正向最大匹配算法、逆向最大匹配算法、最大Ngram分值算法、全切分算法、双向最大最小匹配算法等等。
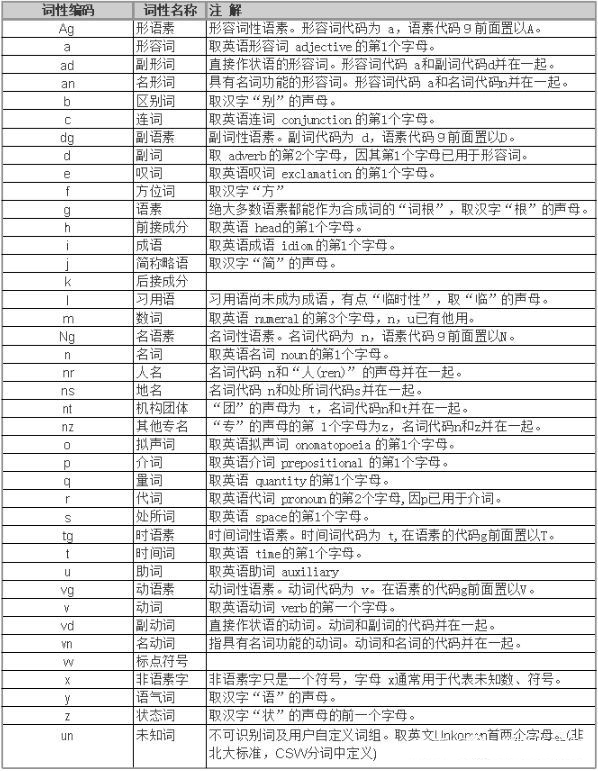
- 词性标注
词性标注,就是给每个词语打标签,如形容词、动词、名词等。词性标注在大部分的处理中是非必须的,只是类似情感分析、知识推理等是需要的。但是相对其他标注词性的标注也是需要更多专业知识的。
-
去停用词
停用词一般指对文本特征没有任何贡献作用的字词,比如标点符号、语气、人称等一些词。去停用词的操作一定要根据场景进行,有些场景是需要语气词来进行判断情感。
4.NLP应用场景
NLP可以在很多领域上进行应用,下面列举了几个。
- 机器翻译
- 情感分析
- 智能问答
- 文摘生成
- 文本分类
- 舆论分析
- 知识图谱
- 销售分析
以上就是整理的在文本标注时能用到的NLP的基础知识点,希望可以在大家工作或者学习当中提供帮助,不管是AI公司做需求的同学还是在标注公司做标注的同学一定要了解,这会对你理解需求起到非常好的作用。也欢迎大家留言交流。

时间:2020-04-19 23:43 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















