BigGAN 论文解读
《Large scale GANtraining for high fidelity natural image synthesis》这篇文章对训练大规模生成对抗网络进行了实验和理论分析,通过使用之前提出的一些技巧,如数据截断、正交正则化等,保证了大型生成对抗网络训练过程的稳定性。本文训练出的模型在生成数据的质量方面达到了前所未有的高度,远超之前的方法。作者对生成对抗网络训练时的稳定性进行了分析,借助于矩阵的奇异值分析。此外,还在生成数据的多样性与真实性之间做了折中。总体来说,本文的工作相当扎实,虽然没有大的方法上的创新,但却取得了非常好的效果,对稳定性的分析也有说服力。
摘要
尽管最近几年在生成式图像建模上取得了进步,但从 ImageNet 这样的复杂数据集生成高分辨率、多样化的图像仍然是一个具有挑战性的工作。为了达到这一目标,本文作者训练了到目前为止最大规模的生成对抗网络(BigGAN),并对这种规模下的网络在训练时的不稳定性进行了研究。作者发现,将正交正则化用于生成器网络能够起到很好的效果,通过对隐变量的空间进行截断处理,能够在样本的真实性与多样性之间进行精细的平衡控制。本文提出的方法在类别控制的图像生成问题上取得了新高。如果用 ImageNet 的 128x128 分辨率图像进行训练,BigGAN 模型生成图像的 Inception 得分达到了 166.3,FID 为 9.6。
整体简介
得益于生成对抗网络的出现,生成式图像建模算法在最近几年取得了大的进步,可以生成真实的、多样性的图像。这些算法直接从样本数据进行学习,然后在预测阶段输出生成的图像。GAN 的训练是动态的,并且对算法设置的几乎每个方面都很敏感,从神经网络的结构到优化算法的参数。对于这一问题,人们进行了大量的持续的研究,从经验到理论层面,以确保训练算法在各种设置下的稳定性。尽管如此,之前最好的算法在条件式 ImageNet 数据建模上的 Inception 得分为 52.5,而真实数据的得分为 233,还有很大的差距。
本文的工作致力于减小 GAN 生成的图像与 ImageNet 数据集中的图像在真实性与多样性之间的差距。为了解决此问题,本文提出了如下几个主要的创新:
证实了增大 GAN 的规模能够显著的提升建模的效果,在这里,模型的参数比之前增大了 2-4 倍,训练时的 batch 尺寸增加了 8 倍。文章提出了两种简单而又具有一般性的框架改进,可以提高模型的伸缩性,并且改进了一种正则化策略来提升条件作用,证明了这些方法能够提升性能。
作为这些修改策略的副产品,本文提出的模型变得更服从截断技巧。截断技巧是一种简单的采样方法,能够在样本的逼真性、多样性之间做显式的、细粒度的控制。
发现了使大规模 GAN 不稳定的原因,对它们进行了经验性的分析,更进一步的,作者发现将已有的和新的技巧的组合使用能够降低这种不稳定性。但是完全的训练稳定性只有在巨大的性能代价下才能获得。对稳定性的分析通过对生成器和判别器权重矩阵的奇异值分析而实现。
文章提出的这些修改技巧显著的提升了 class-conditional GAN 的性能。实现时,用 128x128 的 ImageNet 数据集进行训练, Inception 得分和 Frechet Inception 距离在之前最好的方法上有了显著的提升。另外,还在 256x256 和 512x512 的分辨率下训练了模型。此外,还在自己的样本集上进行了训练,证明了本文提出的方法具有通用性。
下图为本文的算法所生成的图像,达到了以假乱真的地步:

背景知识
生成对抗网络由一个生成器 G 和一个判别器 D 组成,前者的作用是根据随机噪声数据生成逼真的随机样本,后者的作用是鉴别样本是真实的还是生成器生成的。在最早的版本中,GAN 训练时的优化目标为达到如下极大值 - 极小值问题的纳什均衡:
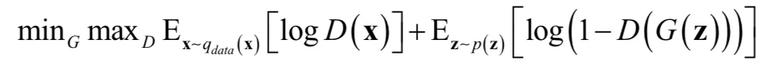
其中 Z∈Rdz 为隐变量,是一个随机向量,从概率分布 p(z) 产生,如正态分布 N(0,1) 或均匀分布 U(-1,1)。当用于图像类任务时,G 和 D 一般是卷积神经网络。如果不使用一些辅助性的增加稳定性技巧,训练过程非常脆弱,收敛效果差,需要精细设计的超参数和网络结构的选择以保证效果。
之前的相关工作
近期的研究工作集中在修改初始的 GAN 算法,使得它更稳定。这些方法中,既有经验性的分析,也有理论性的分析。其中一种思路是修改训练时的目标函数以确保收敛。另外一种思路是通过梯度惩罚或归一化技术对 D 进行限定,这两种方法都是在抵抗对无界的目标函数的使用,确保对任意的 G,D 都能提供梯度。
与文本的方法非常相关的是谱归一化(Spectral Normalization),它强制 D 的 Lipschitz 连续性,这通过对它们的最大奇异值进行运行时动态估计,以此对 D 的参数进行归一化而实现。另外还包括逆向动力学,对主奇异值方向进行自适应正则化。文献 [1] 分析了 G 的雅克比矩阵的条件数,发现 GAN 的表现依赖于此条件数。文献 [2] 发现将谱归一化作用于 G 能够提高稳定性,使得训练算法每次迭代时能够减小 D 的迭代次数。本文对这些方法进行了进一步分析,以弄清 GAN 训练的机理。
另外一些工作聚焦在网络结构的选择上。SA-GAN 增加了一种称为 self-attention 的模块来增强 G 和 D 的能力。ProGAN 通过使用逐步增加的分辨率的图像训练单个模型。
条件 GAN 为 GAN 增加了类信息,作为生成器和判别器的输入。类信息可以采用 one hot 编码,和随机噪声拼接起来,作为 G 的输入。另外,可以在批量归一化层中加入。另外,在 D 中也加入了类别信息。
最后要说的是评价指标,这和数据生成一样困难,目前常用的是 IS 和 FID,本文对算法的比较采用了这两个指标。
Inception Score 使用了如下两种评判标准来检验模型的表现:
-
生成图片的质量
-
生成图片的多样性
其计算方式如下:
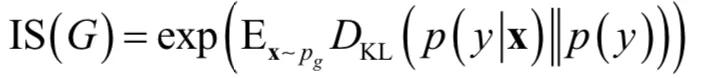
其中 y 为类别标签,x 为样本向量,pg 为生成器生成的样本所服从的概率分布,DKL 为 KL 散度。IS 的值越大越好。p(y) 是生成图片的类别 y 关于生成器 G(z) 的边缘概率分布:
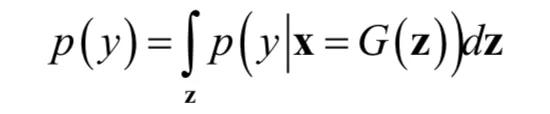
如果生成图片的类别只有一种,那么生成图像的 IS 依然会很高,这是 IS 显著的缺点。而 Fréchet Inception Distance(FID) 相较于 IS 更加适合用于图片生成质量的评价,与 IS 不同,越小的值意味着更好的生成图片的质量以及更丰富的图片的多样性。在所有生成的图像仅为一种类别时,其取值将会很高。FID 的计算方式是使用 Inception 网络中的某一层的特征,并使用多元高斯分布对提取的特征进行建模。假设训练样本对应的特征 featx ~N(μx,∑x),生成图片对应的特征 featg ~N(μg,∑g) 则:
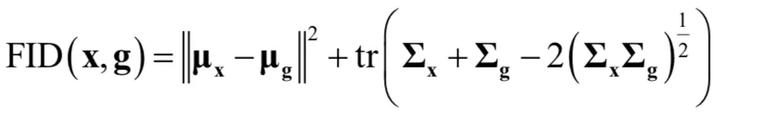
tr 为矩阵主对角线元素之和,即矩阵的迹。
增大 GAN 的规模
本文的重点是探讨增大模型的规模,训练样本的 batch 尺寸来获得性能上的提升。作为基础模型,选用了 SA-GAN,使用 hinge loss 目标函数。通过 class-conditional BatchNorm 为 G 提供类信息,通过 projection 为 D 提供类信息。优化器的设置与文献 [4] 相同,对 G 使用了谱归一化,但学习率减半,G 每迭代一次,D 迭代两次。另外,使用了正交初始化和 Xavier 初始化。每个模型按照输出图像分辨率来选用对应数量核数的 TPU 进行训练,如输出 128x128 分辨率的图像就使用 128 个核 TPU 进行训练。值得注意的是,G 的批量归一化是在对所有设备一起进行的,而不是每个设备单独做自己的归一化。
首先做的是增大 batch 的尺寸,并立刻发现这种做法所带来的效果。下表的前面 4 行列出了不同 batch 尺寸时的得分:

从上表中的第二行和第五行记录了在不使用任何其他文中提到的改进措施情况下,batch size 分别为 256 和 2048 时的实验结果。可以看出,在 batch size 增大 8 倍之后,IS 就获得了 46% 的提升。作者推断这是因为 batch size 增大之后,每个 batch 中的数据覆盖到的模式更多,一场能为生成器和判别器提供更好的梯度。但是,单纯的增加 batch size 带来了非常明显的副作用:在迭代次数较少的情况下,效果反而更好,如果继续训练,训练过程不再稳定,并出现训练坍塌的现象。关于这个现象的原因将在下文的分析部分详细剖析。
接下来所做的是增加网络的宽度,即通道数,每一个层增加 50%,网络的参数因此增加了一倍。这样做带来了 21% 的 IS 提升。增加网络的深度则没有带来这样的性能改善,反而,在 ImageNet 数据集上导致了性能的下降。作者认为这是因为在参数增加的情况下,模型的能力相对于数据集的复杂度过剩导致的。与增加 batch size 不同的是,增加宽度并不会导致训练坍塌的情况出现,只会带来性能的下降。
由于 G 的条件 BatchNorm 层有大量的参数,本文没有采用这种做法。本文选择了共享的类嵌入,线性投影到各个层的 gains 和 biases,在减小了计算需求和内存需求的情况下,训练速度提升了 37%。另外,还使用了层次隐变量空间,具体做法是将噪声向量送人到 G 的多个层中,而不只是输入层。使用这种方法可以是的不同分辨率不同层级的特征被噪声向量直接影响。
## 用截断技巧在真实性和多样性之间做折中
生成器的随机噪声输入一般使用正态分布或者均匀分布的随机数。本文采用了截断技术,对正态分布的随机数进行截断处理,实验发现这种方法的结果最好。对此的直观解释是,如果网络的随机噪声输入的随机数变动范围越大,生成的样本在标准模板上的变动就越大,因此样本的多样性就越强,但真实性可能会降低。首先用截断的正态分布 N(0,1) 随机数产生噪声向量 Z,具体做法是如果随机数超出一定范围,则重新采样,使得其落在这个区间里。这种做法称为截断技巧:将向量 Z 进行截断,模超过某一指定阈值的随机数进行重采样,这样可以提高单个样本的质量,但代价是降低了样本的多样性。下图证明了这一点:

通过这种截断处理,可以在生成的数据的真实性和多样性之间进行折中。
另外还对生成器使用了正交性条件,这种正则化定义为:
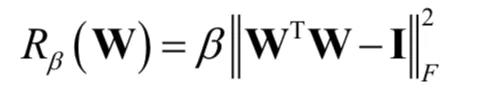
其中 W 是权重矩阵,β是超参数。这种正则化限定性太强,本文实现时做了一些修改,保证在放松约束的同时模型又具有光滑性。实验中发现效果最好的是:

其中,1 是元素值全为 1 的矩阵。这种简单的正则化旨在最小化 filter 之间的余弦相似度,对性能有显著的提升。
总结
实验结果发现,现有的 GAN 技巧已经足以训练处大规模的、分布式的、大批量的模型。尽管这样,训练时还是容易坍塌,实现时需要提前终止。
分析
这一段对 GAN 的稳定性进行了分析,着重探索了影响稳定性的因素,并给出了一些解决方案。对稳定性的分析通过对权重矩阵的奇异值进行分析而实现。作者对生成器和判别器的稳定性分别进行了分析。
生成器的不稳定性
对于 GAN 的稳定性,之前已经有一些探索,从分析的角度。本文着重对小规模时稳定,大规模时不稳定的问题进行分析。实验中发现,权重矩阵的前 3 个奇异值σ0,σ1,σ2 蕴含的信息最丰富。
在训练中,G 的大部分层的谱范数都是正常的,但有一些是病态的,这些谱范数随着训练的进行不断的增长,最后爆炸,导致训练坍塌。如下图所示:
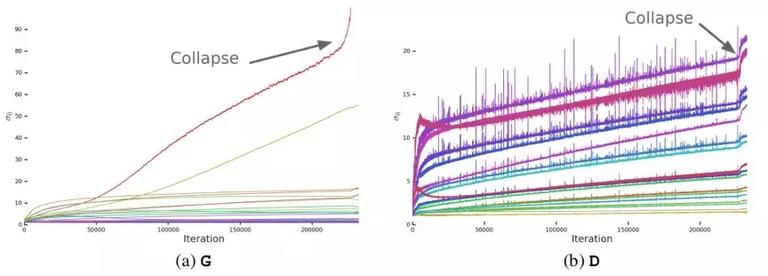
为了确定上面的结论纠结是导致训练坍塌的原因,还是仅仅只是一个现象,在这里对 G 使用了正交正则化方法,抵抗谱爆炸问题。首先,对各个权重的最大奇异值直接进行正则化。其次,用部分奇异值分解对最大特征值进行截断处理。给定权重矩阵 W,它的第一个奇异向量 u0 以及 v0,σclamp 为σ0 为截断后的值。权重的更新公式为:
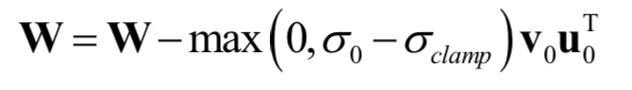
在实验中发现,无论是否做谱归一化,上面这种技巧都可以防止奇异值的逐步增长和爆炸。这也证明了光使用这种技巧无法保证训练的稳定性,因此还需要考虑判别器 D。
判别器的不稳定性
和生成器 G 一样,这里也通过分析判别器 D 的权重矩阵的谱来揭示其行为,然后通过添加一些额外的约束条件来稳定其训练过程。通过观察 D 的σ0 发现,和 G 不同的是,D 的谱有很多噪声,σ0/σ1 的表现很正常,奇异值在整个训练过程中会增长,在崩溃时会发生跳跃,而不是爆炸。
D 的谱的峰值表明,它周期性的接收大的梯度,但 Frobenius 范数却是光滑的。意味着这种作用主要集中在最大的几个奇异方向。作者设想,这种噪声是最优化算法在对抗训练过程中产生的,因为 G 会周期性的产生强烈扰动 D 的批次样本。如果这种谱噪声与不稳定性有因果关系,那么一个很自然的解决办法是使用梯度惩罚,显式的对 D 的雅克比矩阵的变化进行正则化。实验中使用了下面的惩罚项:
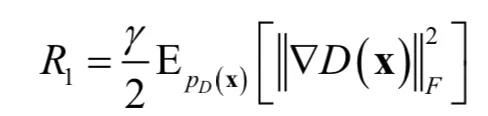
其中γ的值设置为 10。结果训练变得稳定,并且提高了 G 和 D 的谱的光滑性和有界性。但性能却严重退化,IS 值降低了 45%。降低惩罚值部分的缓解了这种退化,但增加了病态谱。用各种不同强度的正交正则化,dropout,L2 正则化重复这种实验,揭示了类似的行为。即加大惩罚项,训练变得稳定,但性能变差。
另外,在实验中还观察到在训练中 D 的损失函数降到了 0,但在崩溃发生时会发生尖锐的反弹即向上的跳跃。对这一现象的一种解释是 D 发生了过拟合,记住了之前的训练样本,而不是学习生成的样本和真实样本之间的有意义的分类边界。为了测试 D 的记忆,用 ImageNet 的训练和测试集对没有崩溃的判别器进行了性能测试,并统计多少比例的样本被判定为真实的或生成的。结果是,对训练样本集的准确率是 98%,对测试样本集的准确率是 50-55%,和随机猜测没有什么区别。这证明 D 确实记住了训练样本,作者认为这与 D 的角色一致,不是显式的进行泛化,而是提取训练样本集,为 G 提供有用的训练信号。
总结
作者得出的结论是,稳定性不单单来源于 G 或者 D,而是两者在对抗训练过程中相互作用的结果。它们病态条件的症状可以用来跟踪和鉴别不稳定性,确保合理的条件被证明对于训练是必须的但对防止训练崩溃时不充分的,即必要不充分。对 D 进行严格的限制能确保稳定性,但会严重损失最终生成的数据的质量。以现有的技术,可以放宽这个条件并允许崩溃在训练出一个好的结果之后发生和达到更好的数据生成效果。

实验
在实验中,作者使用了 ImageNet 和自己的数据集作为评测,与之前的方法进行了比较。下面分别进行介绍。
ImageNet 上的结果
作者用 ImageNet ILSVRC 2012 数据集对模型进行了验证,包括 128x128,256x256,以及 512x512 三种分辨率。生成器和判别器的网络结构如下图所示:
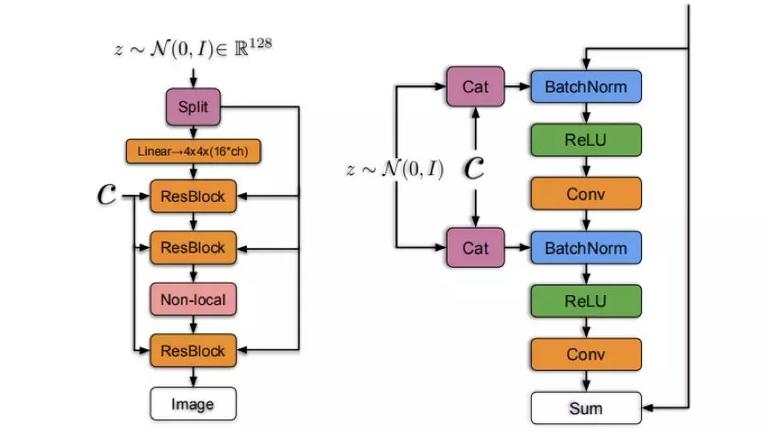
参数设置为下表第 8 行:

对于 128X128 分辨率的模型,生成器和判别器的网络结构如下图所示:
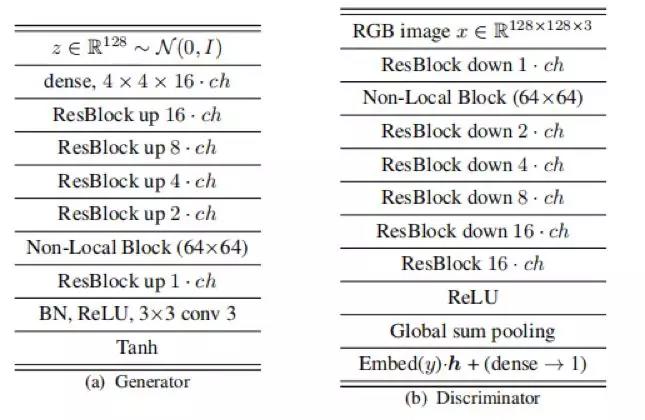
最后的结果如下表所示:

本文提出的方法能够在生成的样本的质量和多样性之间组折中,不同的 IS 下,可以得到不同的 FID。IS-FID 曲线如下图所示:
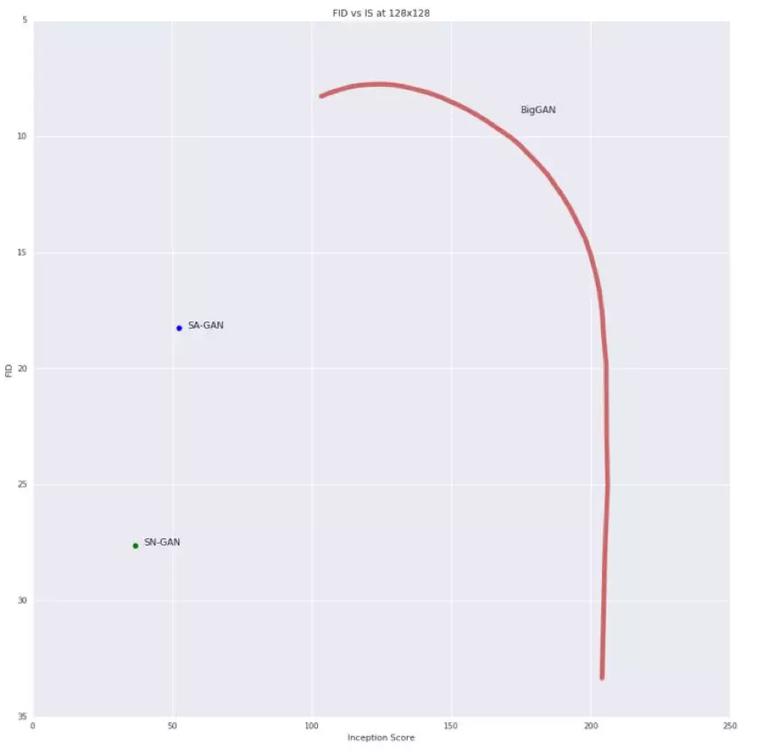

内部数据集上的结果
为了验证本文提出的方法对更复杂、更大规模、更多样性的数据集也有效,作者在自己内部的数据集上也进行了测试。这个数据集有 292M 张图像,包括 8.5K 个类。比 ImageNet 大两个数量级。有些图像有多个标签,即输入多个类,对这种情况,作者随机从这些标签中选择一个使用。为了计算在这个样本集上训练的 GAN 的 IS 和 FID,作者使用了在这个样本集上训练的 Inception v2 分类器。实验结果如下表所示:

所有模型在训练时的 batch 尺寸都是 2048。
总结
本文证明了将 GAN 用于多类自然图像生成任务时,加大模型的规模可以显著的提高生成的图像的质量,对生成的样本的真实性和多样性都是如此。通过使用一些技巧,本文提出的方法的性能较之前的方法有了大幅度的提高。另外,还分析了大规模 GAN 在训练时的机制,用它们的权重矩阵的奇异值来刻画它们的稳定性。讨论了稳定性和性能即生成的图像的质量之间的相互作用和影响。
参考文献
[1] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair,
and Aaron Courville Yoshua Bengio. Generative adversarial nets. In NIPS, 2014.
[2] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training GANs. In NIPS, 2016.

时间:2018-12-03 22:25 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]分析了 600 多种烘焙配方,机器学习开发出新品
- [机器学习]2021年的机器学习生命周期
- [机器学习]物联网和机器学习促进企业业务发展的5种方式
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]机器学习中分类任务的常用评估指标和Python代码实现
- [机器学习]机器学习和深度学习的区别是什么?
相关推荐:
网友评论:















