深度学习在 Airbnb 大规模搜索排名上的实战经验

搜索排名是机器学习中的一个重要应用。在 Airbnb 公司,最初它们是使用梯度提升的决策树模型来做的。随着时间的推移,传统的梯度提升树模型遇到了瓶颈,于是 Airbnb 开始探索利用深度学习来解决搜索排名问题。本文是 AI 前线第 57 篇论文导读,下面我们来深入了解 Airbnb 实践背后的细节和应用深度学习过程中踩过的一些坑。
背景介绍
Airbnb 是一个房屋租赁平台,利用共享经济模式,提供短租服务。客户预定房子的常规模式是首先选择预定房屋的地理位置,然后,通过 www.airbnb.com 网站的搜索引擎来查找可用房间。搜索排名任务在客户查找可用房屋的过程中肩负着重要的责任,它要从成千上万的可用房屋库存中检索并排序然后列出最符合客户需求的房屋。
搜索排名的打分函数最早的第一个版本是手动设计的,后来使用 GBDT(gradient boosted decision tree) 模型替换手动设计的打分函数,Airbnb 的房屋预定得到了大幅度的提升,接着迭代优化了很多次。经过很长一段时间的迭代优化实验,我们发现在线预定房屋的收益达到了瓶颈。所以,在这个时候,我们想尝试一些新的突破。
鉴于这样的背景,本论文分享了如何将深度学习应用于大规模的搜索引擎,打破传统机器学习的瓶颈。本论文的经验适用于已经有自己的机器学习系统,并且开始考虑利用深度学习的团队。在开始打造机器学习系统之前,还是建议团队看一下 Google 的机器学习系统设计准则。
下面讨论的搜索排名只是 Airbnb 模型生态中的一部分,所有的模型最后的目标都是给客户呈现一个最优的房屋预定列表。生态中的模型有一些是预测房东接受客人预定的概率,一些是预测客人在体验上给五星的概率等。本论文只讨论搜索排名的模型,这个模型负责根据客户预定房屋的可能性给房屋检索列表做一个最优的排序。
下图 1 是一个典型的客户搜索会话路径。客户通常有多个搜索,并伴随着点击搜索列表查看详细页。一个成功的搜索会话是以客户开始搜索为开始,以客户预定房屋成功为结束。
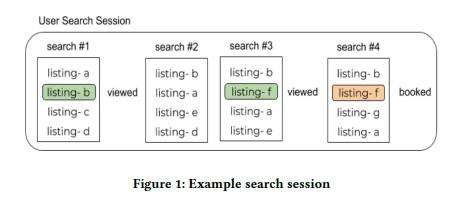
客户的搜索会话行为是通过日志来记录,这些日志会被用来做模型训练。新模型训练的时候,对训练样本进行预处理时,将已经被客户预定的房屋尽可能的指定到排名靠前的位置,来学习打分函数。然后,对训练好的新模型进行 A/B 实验测试,在统计学上观察是否相对现有模型有显著的提升。
下面我们通过几个大的版块来展开讨论:1、总结过去一段时间模型架构是如何演变的;2、特征工程和系统工程的思考;3、介绍一些内部工具和超参数方面的探索;4、总结回顾。
模型演变
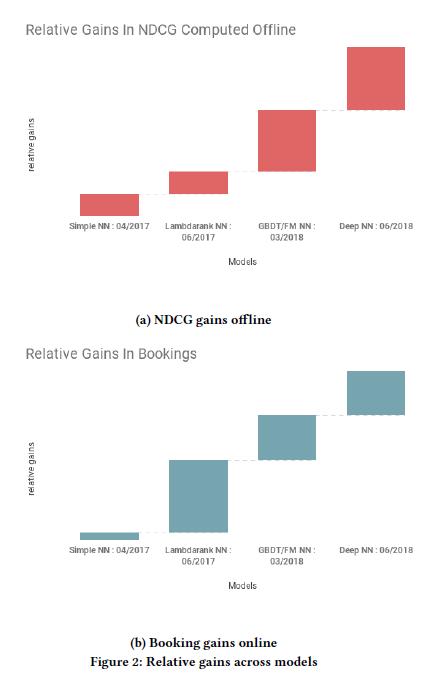
从传统机器学习模型向深度学习模型的转变,不是一种潮流,是一次次优化改进后累积的结果。下图 2 展示了各个阶段离线和在线模型 NDCG 的效果演变过程。
简单的神经网络(Simple NN)
Andrej Karpathy (特斯拉人工智能和自动驾驶视觉总监)在神经网络模型架构设计方面有个建议:不要做英雄主义者。受英雄主义的影响,你就会自己设计非常复杂的模型架构,然后耗费大量的时间和精力来优化模型,最后效果不好不了了之。
Airbnb 上线的第一个版本的神经网络结构非常简单,是一个包含 32 个全连接 ReLU 激活函数的隐层。简单的神经网络使用跟 GBDT 模型一样的特征,线上效果证明跟 GBDT 模型差不多。其中,训练的目标函数都是最小化 L2 回归损失,损失函数中房屋预定的列表被指定为 1,没有预定的列表被指定为 0。
实验证实,NN 网络的 pipeline 可以应用于真实的生产环境,服务线上流量。神经网络的具体 pipeline 在后续的特征工程和系统工程版块展开介绍。
Lambdarank NN
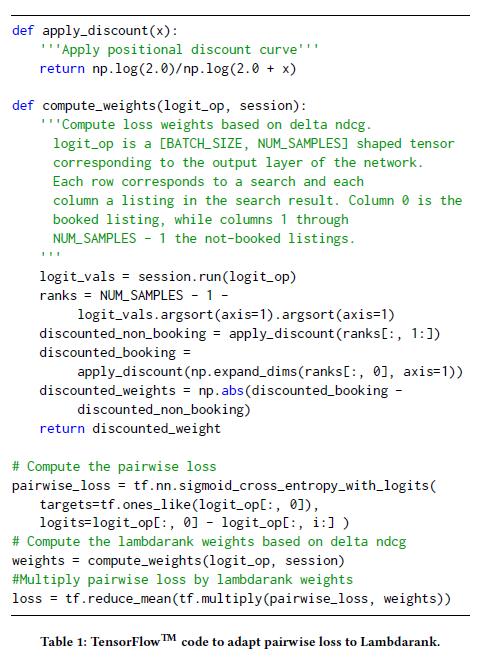
简单的神经网络给了我们一个新的尝试,但还远不够。下面我们做的另外一个尝试是将 Lambdarank 和神经网络结合,其中 NDCG 作为离线搜索排名的主要衡量指标,Lambdarank 提供了一种可以直接优化神经网络 NDCG 的方法。在简单神经网络的回归公式中,这里涉及到两个关键的改进:1、使用{booked listing, not-booked listing}作为训练样本,训练过程中,最小化预定列表和非预定列表得分之间的交叉熵损失。2、 调整两个列表的位置,生成新的 pair 对,在 pairwise loss 上赋予不同的权重。
Decision Tree/Factorization Machine NN 决策树 / 因式分解机 NN
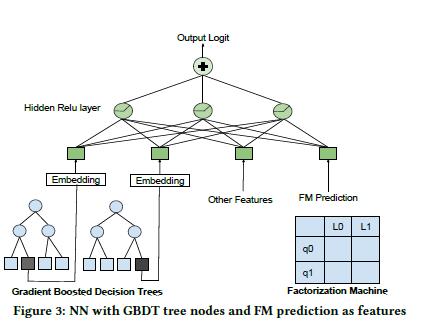
此时,尽管线上使用的是神经网络模型,但是我们同时也在研究其他模型。其中一个比较显著的模型是将 FM 和 GBDT 的输出结果作为神经网络的特征输入的架构模型。如图 3 展示新的模型架构,其中 FM 将预测的结果输入神经网络作为一部分特征,GBDT 模型激活的树节点的索引做为类别特征的 Embedding 结果。
Deep NN
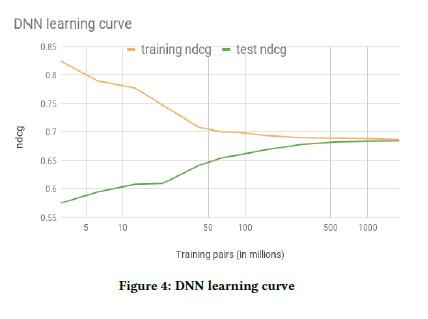
一个典型的神经网络配置是 195 个类别特征 embedding 后,输入到第一个含 127 个全连接 ReLU 的隐层,然后输入第二个含 83 个全连接 ReLU 的隐层。输入神经网络的特征是一些简单的属性特征,比如:价格、历史预定数量等特征。图 4,展示了对比了 NDCG 在训练集和测试集的学习曲线。
特征工程
在特征工程中,常见的处理技巧有计算比率、在滑动窗口上计算平均等,这些都是多年积累的经验。但是,尚不清楚这些特征对于模型是不是最好的,也不能根据最新的信息做出及时的调整。使用神经网络建模的一个最大好处是它可以根据原始数据,在隐含层自己组合特征。为了发挥神经网络的优势,我们发现给神经网络输入原始的数据还远不够,需要在特征工程方面做些基础的转换。传统的机器学习特征工程主要是做计算方面的处理,而神经网络这部分工作在隐含层可以自己完成。在神经网络特征工程中,我们更多的精力是确保输入的特征遵循某些特性。
特征归一化
最开始我们尝试使用 GBDT 的特征,直接输入到神经网络中,结果发现效果非常差。在训练过程中,会发生 loss 饱和的现象,无论如何调整步长都没有效果。最后跟踪问题发现是特征没有做归一化导致的。
对于决策树来说,特征的数值大小并不是很重要,只要表征有序就可以。而神经网络对数值型特征的大小特别敏感,如果输入特征的数值超过通常特征值的范围,在做反向传播计算的时候,就会引起大的梯度改变。由于梯度消失,会导致像 ReLU 这样的激活函数处于永久关闭状态。为了避免这个现象的发生,我们要保证所有特征的值域在一个小的范围内变化。通常的做法是让特征的分布值域在{-1,1},中心点映射到 0。下面介绍两种常用的转换技巧:1、如果特征的分布符合正态分布,做 (feature_val- 均值)/ 方差变换;2、如果特征的分布符合幂律分布,做 log((1+feature_val)/(1+median)) 变换。
特征分布
除了做特征归一化,还需要确保特征的分布光滑平稳。为什么要保证特征分布的光滑平稳?下面是我们试验中发现的一些理由:
定位异常 ( Spotting bugs): 在处理数亿特征样本时,如何检查其中一部分样本是否有异常是非常困难的。有误差的分布和典型分布是有差异的,找到一个光滑平稳的分布对我们定位异常很有帮助。比如:在某地区的价格记录中,发现跟市价明显不一致的错误。这些错误表现在具体的分布图中是一个尖峰。
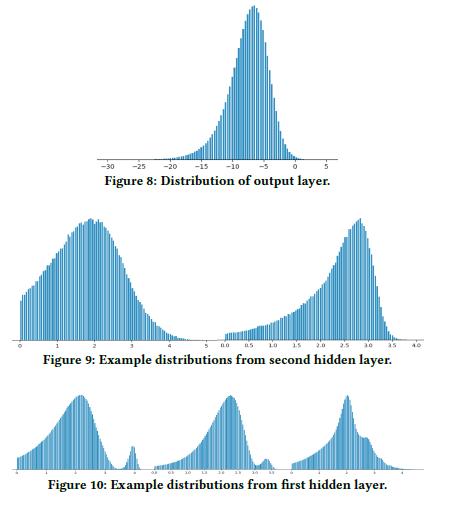
提升泛化(Facilitating generalization):解释为什么神经网络有较好的泛化能力,是一个复杂的前沿研究课题。然而基于我们实际项目观察的经验,输出层的分布会逐渐变得越来越平滑。下图 8 展示了最后一层输出的分布,图 9、图 10 展示了第一层和第二层的分布。其中,在绘制分布图时,做了特殊处理,删除零值,应用 log(1+relu_output) 做转换。
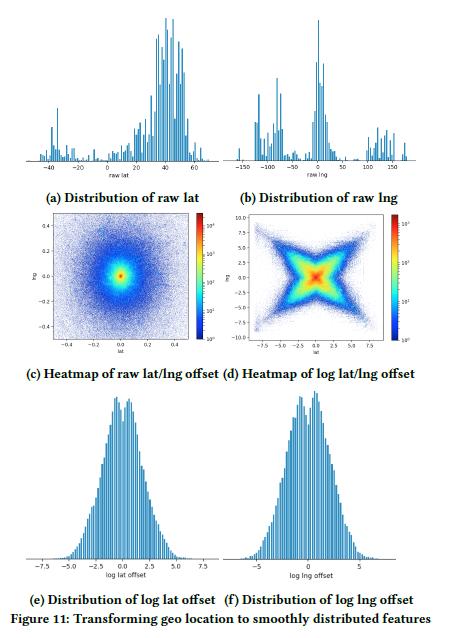
对于地理信息的特征,一般都是使用经纬度来表示。图 11(a)和(b)是原始的经纬度分布信息,为了使地理特征分布更平滑,通过计算与中心点的偏移量来表征地理特征信息。图 11(c)展示了经纬度偏移量比值的原始特征分布,图 11(d)展示了 log 处理经纬度偏移量比值后的特征分布,图 11(e)和(f)是对经纬度偏移量分别经过 log 处理后的特征分布。
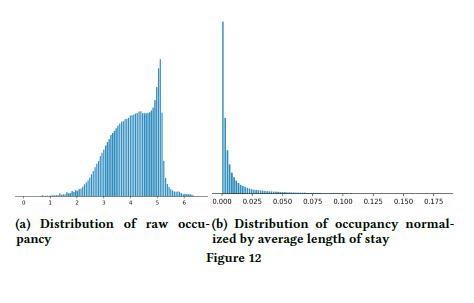
检查特征完整性(Checking feature completeness)某些特征的分布不平滑,会导致模型学习信息缺失。如下图 12(a)展示的是原始房屋占用分布,(b)展示的是(房屋占用 / 居住时长)归一化后的分布,分布不太符合正常理解,调查发现列表中有一些房屋有最低的住宿要求,可能延长到几个月。然而,开始我们没有添加最低的居住时长特征。所以,我们考虑添加最低居住时长作为模型的一个特征。
高数量类别特征(High cardinality categorical features )
对于某个类别 l 特征,不同值的数量非常多,比如邮编、地理位置等特征,我们称为高数量类别特征。对于低数量类别特征使用 one-hot 编码就可以,高类别需要特殊编码。对于 GBDT 模型,它不需要做编码操作,可以自己捕获类别的层次结构。
在神经网络中,对于高数量类别特征处理相对简单。在房屋预定查询中,城市高数量特征的处理只需要将搜索查询中的城市和列表中城市房屋的位置相结合,利用一个哈希函数映射成一个数字即可。这些类别特征映射成 embedding,输入神经网络模型中。模型训练过程中,通过反向传播来学习这些位置偏好信息。
系统工程
我们目前的 pipeline 是:一个访客的搜索查询通过 Java(TM)服务端返回检索结果和分数。Thrift(TM)序列化来存储查询日志,Spark(TM)来处理训练数据,TensorFlow(TM)训练模型,各个工具都是使用 Scala 和 Java(TM)来编写,训练好的模型上传到 Java(TM)服务端给访客提供搜索服务。
Protobufs and Datasets 最开始使用训练 GBDT 的 CSV 格式,输入给 TensorFlow 模型的 feed_dict,后来发现我们的 GPU 利用率只有 25%,大部分的训练时间花费在解析 CSV 数据和拷贝数据到 feed_dict。后来我们做出调整,使用 Protobufs 格式的数据集来训练,速度提升了 17 倍,GPU 利用率提升到 90%。
重构静态特征(Refactoring static features)我们业务中有一些特征变化不大,比如位置、房间卧室的数量等,为了减少每次重复读取磁盘消耗时间,我们将它们组合起来为其创建一个索引,通过 list 的 id 来检索。
Java(TM )神经网络库 在 2017 年我们打算开始将 TensorFlow 生产化的时候,发现没有高效的基于 Java(TM)技术栈的解决方案。在多个语言之间切换,导致产生服务延迟,对我们来说很难接受。所以,我们在 Java(TM)上自己创建了自定义的神经网络打分函数库。
超参数
像 GBDT 中的超参数树的个数、正则化等一样,神经网络也许多超参数。下面是我们调超参数的一些经验分享:
Dropout Dropout 对神经网络防止过拟合是必不可少的,但是在我们的实际应用中,尝试了多种正则化,都导致离线评估效果下降。所以,我们在训练数据集中随机复制一些无效的场景,是一种类似数据增强(data augmentation)的技术,来弥补这种缺失。另外,考虑到特定特征分布,我们手工添加了一些噪声数据,离线评估的 NDCG 提高大约 1%,但是在线统计评估并没有显著的提升。
初始化(Initialization)第一个模型的时候,我们所有权重和 embeddings 都初始化为零,发现效果非常糟糕。再经过调查后,我们现在选择 Xavier 来初始化所有的神经网络权重,使用 random uniform 初始化所有的 embeddings,其分布区间在{-1,1}之间。
学习率(Learning rate)对于我们的应用,发现使用 Adam 优化算法的默认参数很难提升效果,最后选择了 LazyAdamOptimizer,当训练 embeddings 时,非常快。
批处理大小(Batch size)改变 batch size 对训练速度影响非常大,但是它对模型的确切影响是很难把握的。在我们使用的 LazyAdamOptimizer 优化器中,剔除学习率的影响外,我们选择 batch size 的大小为 200 时,对我们目前的模型来说是最好的。
特征重要性
估计特征重要性和模型可解释性是我们迈向神经网络模型领域关键的一步,特征重要性可以指导我们更好的迭代模型。神经网络最大的优势是解决特征之间非线性组合。这同时导致了解哪些特征对模型效果提升起关键作用这件事情变得困难了。下面分享一下我们在神经网络特征重要性方面的一些探索:
分数分解:在神经网络中,试图了解单个特征的重要性会越来越混乱。我们最初的做法是获取神经网络产生的最终得分,并尝试将其分解为各个节点贡献得分。但是,在查看结果之后发现这个想法在逻辑上有个错误:没有一个清晰的方法可以将特定输入节点和经过非线性激活函数(ReLU 等)后的影响分开。
烧蚀试验(Ablation Test):另一种简单想法是一次次删减、替换特征,重新训练然后观察模型的性能,同时也可以考虑特征缺失导致性能成比例下降来衡量特征的重要性程度。然而,通过这种方法评估特征重要性有点困难,因为一些冗余的特征缺失,神经网络模型是可以弥补这种缺失的。这个有点类似于忒修斯悖论,你能在一个特征一个特征删减、替换的过程中,保证整个模型性能没有显著的下降?
置换试验(permutation test):受随机森林模型特征重要性排序的启发,这一次我们尝试复杂一点的方法。在测试集上随机的置换特征,然后观察测试上模型的性能。我们期望的是越重要的特征,越会影响模型的性能。经试验测试发现好多无意义的结果,比如: 列表中房屋的数量特征对于预测房屋预定的概率影响非常大,但是仅仅测试这个特征,其实是无意义的,因为房屋的数量还跟房屋的价格有关联。
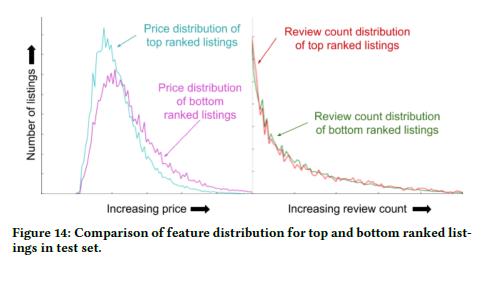
TopBot 分析: TopBot 是我们自己设计的分析特征重要性的工具,它可以自顶向下分析。图 14 展示了如何判断特征重要性,从图中可以看出 price 特征比较重要,review count 特征不是特别重要。
回顾总结
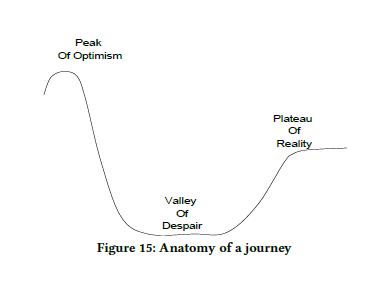
图 15 展示了我们经历深度学习的历程。在无处不在的深度学习成功案例中,我们很乐观的认为深度学习将会取代 GBDT 模型,并给我们带来巨大的收益。最初的讨论都是围绕其他保持不变的情况下,仅替换当前的 GBDT 模型为神经网络模型,看能带来多大的收益。这使我们陷入了绝望的低谷,没有得到任何的收益。随着时间的推移,我们意识到仅仅替换模型不够,还需要对特征处理加以细化,并且需要重新思考整个模型系统的设计。受限于规模化,像 GBDT 这样的模型,易于操作,性能方面也表现不错,我们用来处理中等大小的问题。
基于我们尝试的经验,我们极力向大家推荐深度学习。这不仅仅是因为深度学习在线获得的强大收益,它还改变了我们未来的技术路线图。早期的机器学习主要精力花费在特征工程上,转移到深度学习后,特征组合的计算交给神经网络隐层来处理,我们有更多的精力思考更深层次的问题,比如:改进我们的优化目标。目前的搜索排名是否满足所有用户的需求?经过两年探索,我们迈出了第一步,深度学习在搜索排名上才刚刚开始。
论文原文链接:
https://arxiv.org/pdf/1810.09591.pdf
会议推荐:12 月 20-21,AICon 将于北京开幕,在这里可以学习来自 Google、微软、BAT、360、京东、美团等 40+AI 落地案例,与国内外一线技术大咖面对面交流。

时间:2018-11-25 13:18 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















