苏宁 11.11:一种基于神经网络的智能商品税分类

1. 项目背景
1.1 业务问题描述
目前企业财务人员开取商品增值税发票时,票面上的商品需要与税务总局核定的税分类编码进行关联,按分类编码上注明的税率和征收率开具发票,使得税务机关可以统计、筛选、比对数据等,最终加强征收管理。为了满足这一要求,最关键的地方就在于确定商品的税分类编码。传统的方法是人工筛选商品关键字,然后在税务总局提供的税分类编码列表中查找,无法直接查找到的,根据政策先进行行业、大类的划分,再进行小类细划分,对于无法清楚界定、归类的,按照商品的材料或用途选择最近似的编码,最后根据编码确定商品名称和税率。
例如根据商品名“夏装雪纺条纹短袖 t 恤女春半袖衣服夏天中长款大码胖 mm 显瘦上衣夏”,预测相应的税分类编码(要求类目比较精细)、税分类简称、税分类描述以及对应的税率。商品量为千万甚至亿量级,通常商品名字数不会太多,税分类编码有 4200 多种,常见的商品税分类编码应该少于该数值。
1.2 解决方案
目前存在少部分自动税分类编码系统,采取的方案主要是根据大量的商品关键词建立关键词与税分类编码的一一对应关系,并存储在数据库中,开票人员首先仍然需要人工筛选商品关键词提供给税分类系统,系统在数据库中根据关键词进行查找,输出相应的税分类编码和税率等,如果没有匹配的结果将没有输出。原有系统存在的缺点主要是需要事先人工筛选商品关键词,而目前实际的商品名称五花八门,为了提高商品的检索量添加了大量的修饰词语,在人工筛选关键词这一步仍然存在不少工作量,不能做到完全的自动化处理。
本文的思路主要是将该问题当作一个短文本多分类问题,根据商品名称分词后生成的词向量,基于神经网络学习一个文本分类模型,在此基础上构建一个智能商品税分类系统。
2. 完整的技术方案
2.1 数据接入
大数据平台数据库内存有大量已开票商品数据,从已开票商品数据中提取商品名称、税分类编码和税率三个字段,同时要筛选掉税分类编码字段为空或者编码错误的数据,将最终获取的数据按行存储到文本文件中,为训练商品模型提供数据服务。
2.2 文本预处理
文本预处理是在文本中提取关键词表示文本的过程,主要包括文本分词和去停用词两个阶段。例如商品名“夏装雪纺条纹短袖 t 恤女春半袖衣服夏天中长款大码胖 mm 显瘦上衣夏”经文本分词和去停用词之后商品示例标题变成了下面“ / ”分割的一个个关键词的形式:
夏装 / 雪纺 / 条纹 / 短袖 / t 恤 / 女 / 春 / 半袖 / 衣服 / 夏天 / 中长款 / 大码 / 胖 mm / 显瘦 / 上衣 / 夏。
由于业内中文文本分词方法已经非常成熟,我们采用目前应用较多的中文分词库 jieba 进行分词。
2.3 词嵌入生成
word embedding(词嵌入)生成模型如图 1 所示。
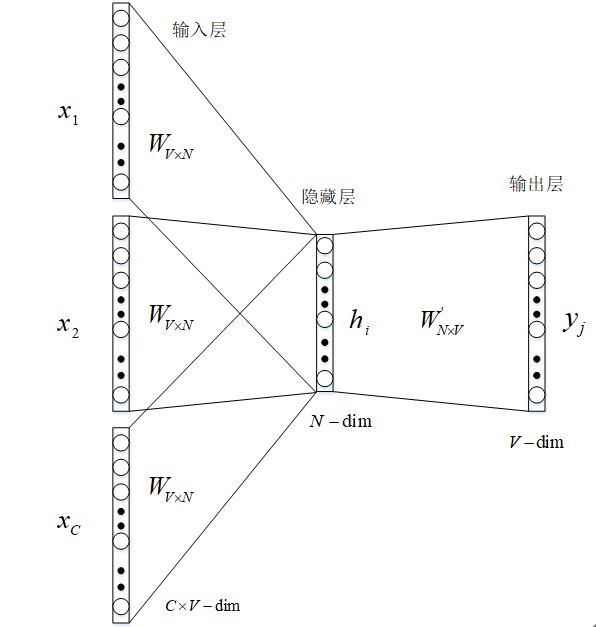
图 1 词嵌入生成模型架构
2.3.1 前向传播

2.3.2 反向传播和随机梯度下降学习权重
在学习权重矩阵 W 与 W’过程中,我们可以给这些权重赋一个随机值来初始化。然后按序训练样本,逐个观察输出与真实值之间的误差,并计算这些误差的梯度。并在梯度反方向纠正权重矩阵,这种方法被称为随机梯度下降,但这个衍生出来的方法叫做反向传播误差算法。具体步骤如下
- 首先定义 loss function(损失函数),这个损失函数就是给定输入上下文的输出词语的条件概率,一般都是取对数,如下所示:
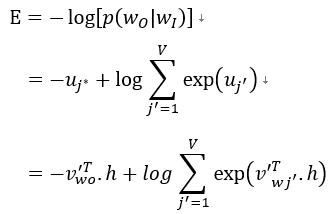
其中 j* 表示目标词在词表 V 中的索引。
- 接下来对损失函数求导,得到输出权重矩阵 W’的更新规则:
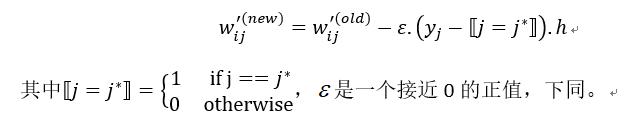
- 类似地可以得到权重矩阵 W 的更新规则:
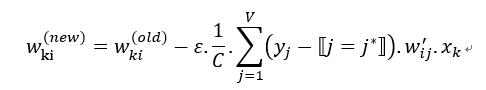
2.3.3 获取词嵌入
在第 2.3.2 节中经过足够次数的迭代,损失函数足够小时,我们可以得到权重矩阵 W,其中矩阵 W 的第 k 行就是词表 V 中编号为 k 的词所对应的词嵌入。
2.4 商品税分类模型
算法模型示意图如图 2 所示。
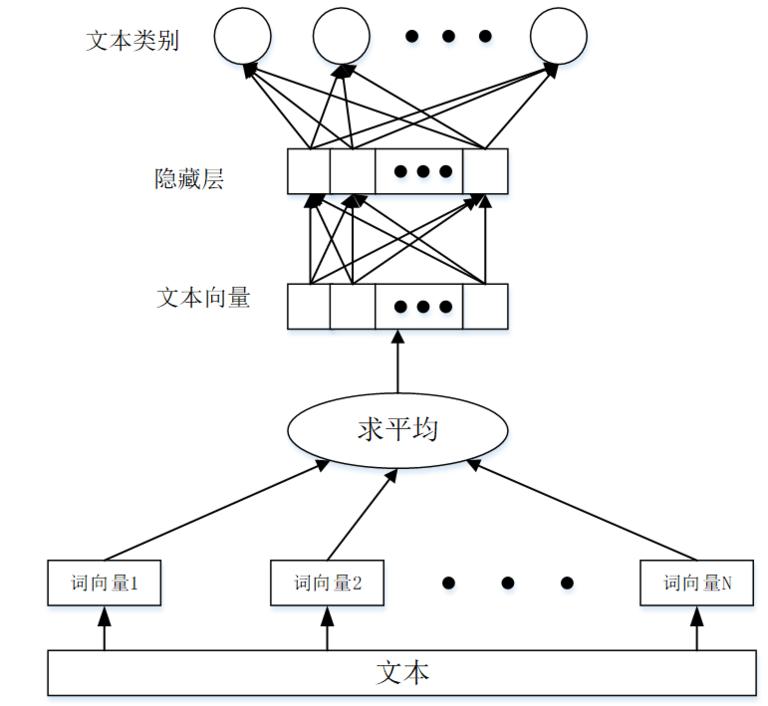
图 2 商品税分类模型架构
2.4.1 模型理解
本算法是一种有监督的模型,与上一节提到的词嵌入生成架构很相似,其结构如图 2 所示。上一节中的词嵌入生成模型,通过上下文预测中间词,而本分类模型则是通过上下文预测标签(这个标签就是文本的类别,本发明中就是商品名对应的税分类编码,是训练模型之前通过人工标注等方法事先确定下来的)。
从模型架构上看,沿用了词嵌入生成模型的单层神经网络的模式。模型的输入是一个 n-gram 词嵌入的序列(由词嵌入模型生成的 1~n 个连续的词嵌入求和得到 ),输出是这个词序列属于不同类别的概率。对词嵌入加权平均之后映射到隐藏层,再由隐藏层映射到输出层,对输出层的结果进行 softmax 分类可以得到文本属于各个类别的概率,可以得到 loss function 为:

2.4.2 层次化 softmax
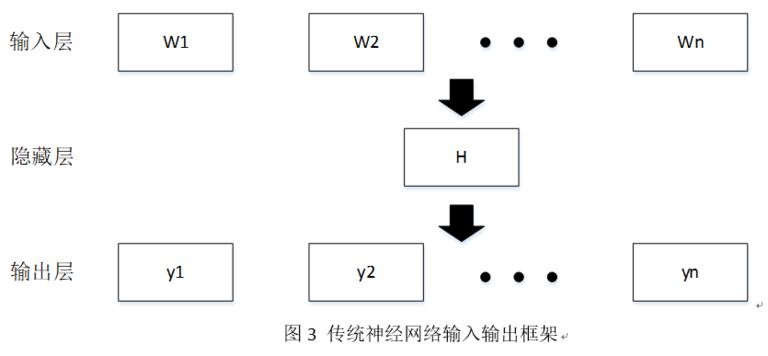
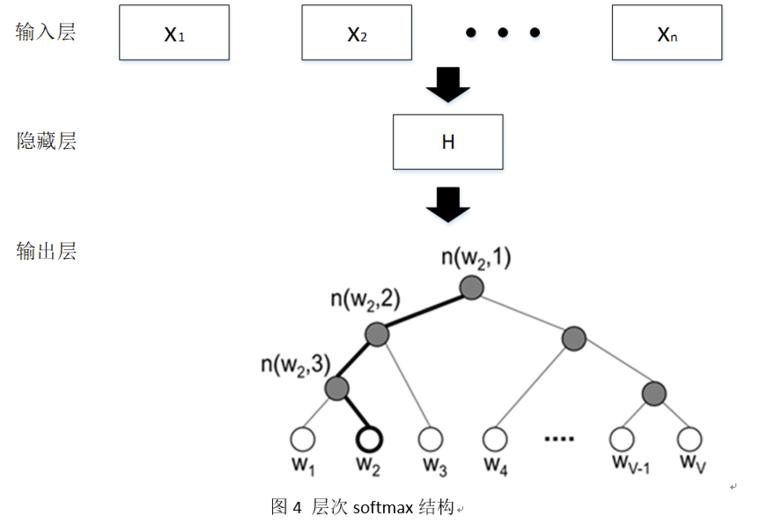
传统神经网络输入输出框架如图 3 所示,hierarchical(层次化) softmax 结构如图 4 所示。本模型的 softmax 层与传统的神经网络有一定区别,hierarchical softmax 结构是把输出层改成了一颗霍夫曼树,其中图中白色的叶子节点表示词汇表中所有的 |V| 个词, 黑色节点表示非叶子节点,每一个叶子节点也就是每一个 label(标签),都对应唯一的一条从 root(根)节点出发的路径。我们的目的是使的 W=W0 这条路径的概率最大,即:P(W=W0|W1) 最大, 假设最后输出的条件概率是 W2 最大,那么我只需要去更新从根结点到 W2 这一个叶子结点的路径上面节点的向量即可,而不需要更新所有 label 的出现概率,这样大大的缩小了模型训练更新的时间。
2.4.3 反向传播与模型训练
本模型训练时采用 500 万条已开票数据,根据第二节所述进行分词,选择其中 400 万条数据作为训练集,剩下 100 万条数据作为测试集,注意数据要以 UTF-8 格式存储,格式如附图 5 所示。训练方法采用与词嵌入生成模型类似的反向传播和梯度下降去更新权重矩阵 A 和 B。在 32G CPU×3 条件下,模型训练时间约 40 分钟左右,训练结束后会得到一个二进制文件,该文件内存储了权重矩阵的数值,约 40M 大小。利用 100 万条测试数据对模型性能进行验证,得到模型预测商品税分类编码准确率达 95.48%。
2.4.4 前向传播与模型使用
将输入的商品名分词与去停用词后,通过词嵌入生成模型生成词嵌入,再根据生成的词嵌入组合成 n-gram 特征,n-gram 特征就是商品税分类编码分类模型的输入,根据训练出的模型权重矩阵 A 将 n-gram 特征加权平均后输入到隐藏层,再根据训练出的权重矩阵 B 将隐藏层的输入线性变换到输出层,最后将输出层的结果通过 softmax 函数 f 得到编码分类结果,如下式所示:
label=f(BAx_n)
由于商品税分类编码唯一标示商品,可以根据编码在税务总局提供的税分类表格中检索到商品所属大类、细分类别名称以及对应的税率。
2.5 模型部署与包装
模型训练完成后为了便于用户使用,将其部署到服务器上提供远程调用服务,这里我们采用基于 Google 的远程过程调用框架 gRPC 的方案,数据存储格式采用 Google 的 protocol buffer(协议缓冲区)格式,该格式比传统的 json 等格式效率更高、速度更快。在服务器上启动服务后,经验证用户每次调用的时间大约为 300-500ms,能够满足正常生产需要。
3. 本技术方案带来的有益效果
方案整体实施流程如图 5 所示。
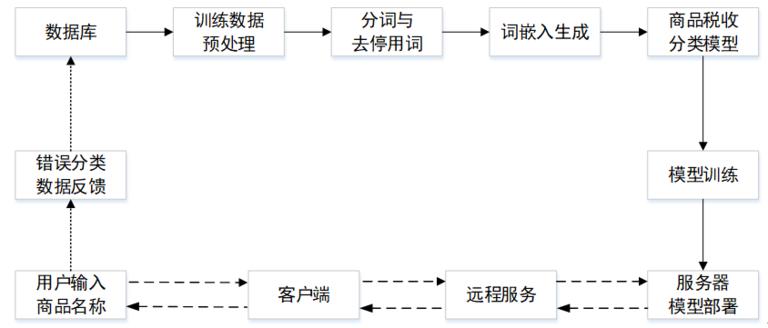
对比现有技术,一方面是传统的人工查找方法,在筛选商品关键词后,需要人工进行商品所属大类和细分类别的分类,而现有商品税分类编码共有 4227 种,种类繁多且容易混淆,人工选择工作量较大且容易出错。另一方面目前类似的自动编码系统,对输入要求非常严格,需要人工筛选准确的商品关键词输入系统,而目前实际的商品名称错综复杂,在人工筛选关键词这一步仍然存在不少工作量,此外该系统输出准确率也较为一般。使用本技术方案,系统部署十分方便,只需配置好环境即可马上投入使用,同时系统可以直接输入商品名称,不需要做任何人工处理,能够节省大量人力成本,而且预测税分类编码准确率达 95% 以上,此外系统支持持续学习更新,系统升级时只需要替换模型文件,更新和维护都非常方便。
作者介绍
欧文祥,苏宁易购 IT 总部员工平台研发中心算法工程师,负责商品税分类、豆芽人脸识别活体检测等算法开发。曾从事无线通信算法开发,具有较丰富的算法开发经验,自学能力较强。对机器学习、深度学习相关前沿技术感兴趣,在信号处理、图像处理、图像识别、文本分类等领域有相关经验和项目实践。

时间:2018-11-19 13:10 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















