用Amazon SageMaker训练和部署机器学习模型

【51CTO.com快译】Amazon SageMaker在re:Invent 2017大会上宣布,这是AWS的一种托管机器学习服务。它在云端支持训练和托管机器学习模型。客户可以在英伟达Tesla K80和P100 GPU支持的集群上运行训练作业。训练作业的结果(准备用于推理的模型)可作为实现可扩展预测的REST API来呈现。
该服务还支持超参数调优,数据科学家和开发人员可以借助该服务,找到最适合某一个算法和业务问题的最优参数。比如说,为了解决典型的回归问题,超参数调优猜测哪些超参数组合可能获得最佳结果,并运行训练作业来测试这些猜测。测试完第一组超参数值之后,超参数调优使用回归来选择要测试的下一组超参数值。
Amazon SageMaker的最佳设计决策之一是,使用Jupyter Notebooks作为开发工具。鉴于Notebooks在数据科学家当中的熟悉和普及程度,准入门槛很低。AWS开发了一个原生Python SDK,可以与NumPy、Pandas和Matplotlib等标准模块混合搭配。
Amazon SageMaker与相关的AWS服务紧密集成,因而轻松处理模型的生命周期。借助面向AWS的Python SDK:Boto3,用户可以存储数据集,并从Amazon S3存储桶中检索数据集。还可以从云端数据仓库Amazon Redshift导入数据。该服务与IAM集成以进行身份验证和授权。使用Amazon EMR运行的Spark集群可与SageMaker集成起来。AWS Glue是用于数据转换和准备的首选服务。
Docker容器在SageMaker的架构中发挥着关键作用。AWS为常见算法提供了容器镜像,比如线性回归、逻辑回归、主成分分析、文本分类和对象检测。在开始训练作业之前,开发人员应将数据集的位置和一组参数传递给容器。然而,高级Python API对处理容器所涉及的步骤作了抽象处理。最后,经过训练的模型也被打包成用于呈现预测API的容器镜像。SageMaker依赖用于存储镜像的Amazon EC2 Container Registry和托管模型的Amazon EC2。
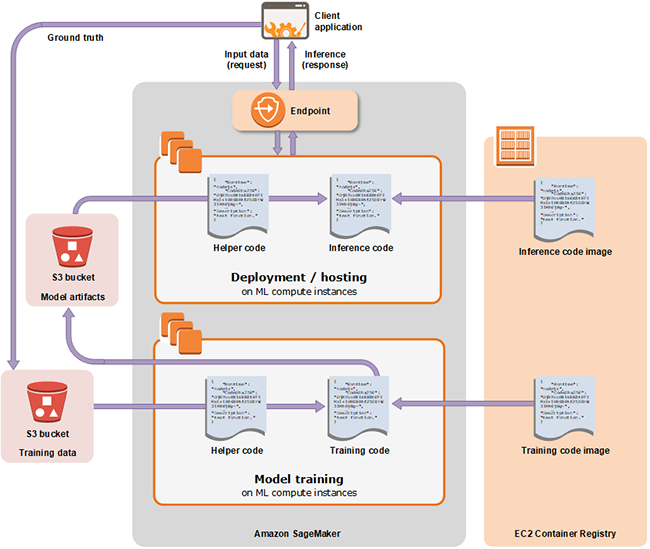
Amazon SageMaker有三个基本组件:托管的Jupyter Notebooks、分布式训练作业以及呈现预测端点的模型部署。
不妨仔细看一下针对部署在Amazon SageMaker中的机器学习模型来训练和预测所涉及的步骤。
数据准备和探索
Amazon SageMaker要求数据集在S3 Bucket中可用。上传数据之前,客户可以选择在外部服务中执行ETL操作,比如AWS Glue、AWS Data Pipeline或Amazon Redshift等服务。
数据科学家可以使用包括Pandas和Matplotlib在内的熟悉工具来探索和可视化数据。
在准备和探索数据之后,数据集将转换成SageMaker模型要求的一种格式。由于该平台根源于Apache MXNet,它使用框架中定义的Tensor数据类型。数据集上传到S3存储桶之前,需要将NumPy数组和Pandas数据框序列化成MXNet Tensors。
模型选择和训练
Amazon SageMaker有内置算法可以对训练模型的低级细节进行抽象处理。每种算法都可作为将数据集和指标作为参数的API来使用。这消除了选择适合训练的那种框架带来的麻烦。一旦开发人员决定了使用什么算法,剩下来的就是调用映射到该特定算法的API。
在幕后,SageMaker使用Apache MXNet和Gluon框架,将API转换成创建作业所需的多个步骤。这些算法打包成存储在Amazon ECR中的容器镜像。
除了Apache MXNet外,SageMaker还将TensorFlow呈现为原生框架。开发人员可以编写用于创建自定义TensorFlow模型的代码。
还可以使用自定义框架,比如PyTorch和Scikit-learn。SageMaker要求这些框架封装在容器镜像中。Amazon发布的说明性指南包含Dockerfile和用于创建自定义镜像的帮助脚本。就在开始训练作业之前,使用低级Python API,就可以将Amazon SageMaker指向自定义镜像,而不是内置镜像。
模型训练
Amazon SageMaker的训练作业在基于Amazon EC2实例的分布式环境中运行。API需要实例数量与实例类型一起,才能运行训练作业。如果训练复杂的人工神经网络,SageMaker要求基于K80或P100 GPU的ml.p3.2xlarge或更好类型的实例。
从Jupyter Notebook开始时,训练作业同步运行,显示基本的进度日志,一直等到训练完成再返回。
模型部署
在Amazon SageMaker中部署模型是分两步走的过程。第一步是创建端点配置,该配置指定了用于部署模型的机器学习计算实例。第二步是启动机器学习计算实例,部署模型,并呈现URI进行预测。
端点配置API接受机器学习实例类型和实例的初始计数。如果是推理神经网络,配置可能包括GPU支持的实例类型。端点API按照上一步定义的内容来配置基础设施。
Amazon SageMaker支持在线预测和批量预测。批量预测使用经过训练的模型来推断存储在Amazon S3中的数据集,并将推断结果保存在创建批量转换作业的过程中所指定的S3存储桶中。
与谷歌云机器学习引擎和Azure机器学习服务相比,Amazon SageMaker缺少使用本地计算资源来训练和测试模型的功能。即使是简单的机器学习项目,也需要开发人员创建托管的Notebooks以及用于训练和预测的实例,因而这项服务成本高昂。
预计Amazon会在今年的re:Invent大会上宣布SageMaker的多处改进。

时间:2018-11-15 23:43 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















