苏宁 11.11:搜索引擎 Solr 在苏宁易购商品评价系

背景说明
苏宁易购商品评价系统主要提供商品维度评价数量聚合、评价列表展示功能,并为其他业务系统提供商品评价数据支撑服务。功能涉及对亿级数据的数量聚合、排序、多维度查询等复杂的业务场景,关系型数据库的索引为 B-Tree 结构,适合数值区分度或离散度高的数据,而评价系统中单个商品评价可以达到数十万条,相同星级的评价数则为亿级,故不适宜使用关系型数据库。解决此类海量数据准实时聚合的技术选型有以倒排表作为索引结构的 Solr 和 Elasticsearch(底层都是 Apache Lucene)搜索引擎服务,还有以 bitmap 作为底层索引结构的实时分析统计数据库 Druid,但 Druid 只是支持数据统计功能并不保存原始数据,无法满足商品评价类的功能需求。系统建设之初对团队对 Solr 更为熟悉,故在 Solr 和 Elasticsearch 两者之间选择的 Solr 作为商品评价索引数据存储服务。
评价系统架构
苏宁易购商品评价系统架构如下:
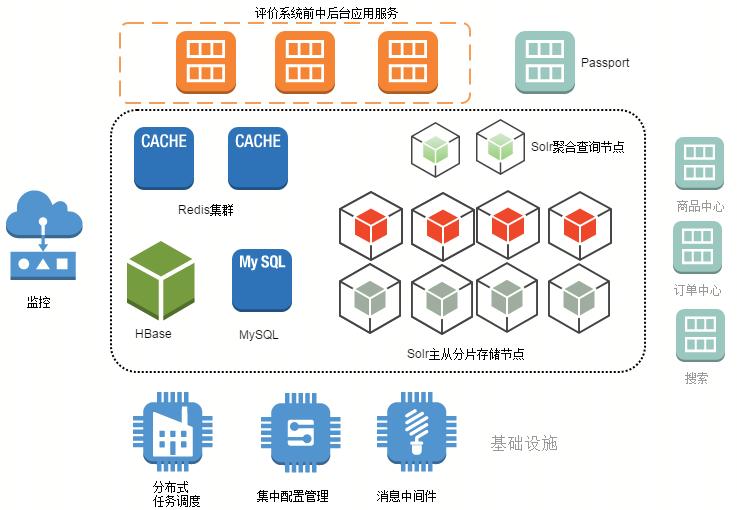
图 2-1
应用服务模块
根据苏宁易购技术规范要求,应用系统架构划分为前中后台三个主模块:
- 前台:为 web、app 提供页面或接口服务,接入苏宁统一认证系统 Passport;
- 中台:通过苏宁自研 RSF 远程服务框架对前台服务和其他业务系统提供功能接口服务;
- 后台:业务系统运营管理功能和任务批处理。
数据存储层
- MySQL:存储和查询登录用户发表的评价,具备 ACID 特性,按照用户 ID 分库分表,根据业务要求和存储容量限制只保留指定时间内的评价数据
- Redis 集群:苏宁在开源 Redis 中间件基础上自研的支持分布式集群、熔断、横向扩容的高可用、海量缓存服务架构,缓存商品评价数量和列表数据,承载用户端的数据访问请求,降低对业务系统的访问压力
- HBase:海量评价内容存储
- Solr:评价索引存储和查询服务
外围系统
- 商品中心:通过 MQ(异步) 和 RSF(同步)接收保存商品主数据如商品信息、类目信息、店铺信息、商品关系信息等
- 订单中心:待评商品主要来源于订单中心通过 MQ 下发的订单信息和订单状态通知,并由评价系统提供订单待评状态查询 RSF 接口,在订单页面展示商品评价发表入口
- 搜索产品线:通过 MQ 下发商品评价数量到搜索产品线,为商品搜索排序计算提供数据支持
基础设施
- 分布式任务调度系统 (UTS):对各业务系统中的定时任务进行集中管理和调度,解决了集群环境下任务并发执行的控制,让业务系统从繁琐的技术细节中释放出来,并提供了对任务调度执行情况的监控和异常短信告警、重试机制,且提供跨业务系统的后继任务调度。
- 集中配置管理 (SCM):基于 Zookeeper 自研的应用配置信息集中统一管理和实时推送服务框架。
- 消息中间件:由于历史原因,苏宁内部有多套 MQ 中间件,包括 IBM MQ,Kafka 和自研的 WindQ。IBM MQ 已经不建议使用,正在逐渐废弃;Kafka 在大数据场景下使用较多;业务系统推荐使用 WindQ,解决了解决多活场景下消息路由,提供消息发送重试熔断、在线动态扩缩容、顺序消费、异构 MQ 桥接等特性。
监控
- 日志:改造 Solr 日志模块,接入苏宁统一日志框架,便于异常问题分析
- 主机:接入 Zabbix 监控体系,监控主机和应用健康状态
- 系统:接入苏宁云迹系统,监控 Solr 请求响应 TP90/99 等指标
Solr 介绍
搜索引擎基础原理
搜索引擎的索引称为反向索引,俗称倒排表,把文本分词得到字典,保存字典项与文档 ID(Lucene 自身 doc ID 而非应用端文档 ID)的关系,在查询时根据字典查询到倒排表文档 ID 集合,再进行交并集操作即可得到结果,其主要结构是字典域、索引域和字段存储域。反向索引如下图:
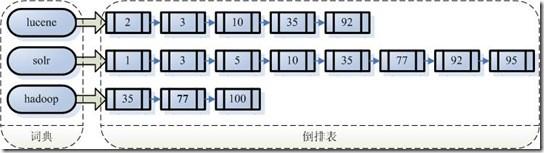
图 3-1
在 Solr4.0 之后为了满足排序和关键字聚合的需求场景,Lucene 提供了 DocValues 特性,又被称为正排表,使用列式存储保存文档 ID 和字典项的关系,不再使用之前 FieldValue Cache 机制,提升性能并降低对内存的使用和虚拟机 Full GC 的风险。在 Elasticsearch 中所有字段都是默认开启此特性,但在 Solr 中需要使用者进行显式配置生效。DocValues 存储结构可分为两种,一种是原值,一种是字典项 ID。
- 单数值型和原始字节型字段,其基本结构包含字段原值的 long[] 数组,如带有三个数值的文档 DocValues 结构:
doc[0] = 1005 doc[1] = 1006 doc[2] = 1005
- 其他可索引类型字段,其结构也是一个 long[] 数组,只不过数组中的值为字典项 ID( 可能有多个),例如有 3 个字符型字段的文档:
doc[0] = "aardvark" doc[1] = "beaver" doc[2] = "aardvark"
假如“aardvark”在字典表中 ID 为 0,”beaver”在字典中 ID 为 1,则实际结构为:
doc[0] = 0 doc[1] = 1 doc[2] = 0
字典表数据为:
term[0] = "aardvark" term[1] = "beaver"
注:字典表所有 term 都是有序的,故 DocValues 可以直接用于排序。
Solr&Lucene 架构体系
Solr 是一个高性能、基于 Lucene 的开源全文搜索服务,提供丰富的查询语言,同时实现了可配置、可扩展并对查询性能提供了优化,提供完善的功能管理界面;在 Lucene 基础上对易用性和可用性进行了大量封装如 Schema 配置化、请求分发处理机制、插件化机制、数据导入、分布式、监控指标采集等,架构体系如下:
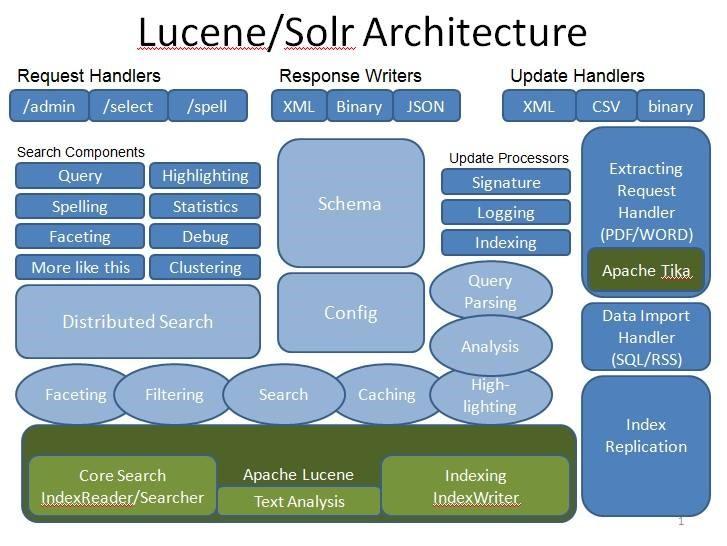
图 3-2
苏宁商品评价系统结合自身业务特点采用了 Solr 主从节点和聚合查询节点的组合架构,而不是通用的 Solr Cloud 架构,主要考虑到两点:
- 横向扩容机制完全可控,根据商品编码单调递增特性,可以随时扩充新节点,节点路由机制由业务系统控制。
- 单独搭建聚合查询节点,在跨多个 Solr 节点查询时由聚合节点实现聚合查询功能,特别是在聚合商品评价列表查询场景下,降低对数据节点的性能压力。
Solr 特性应用
多维度数量聚合
商品详情页展示商品 / 供应商维度审核通过的好中差评数量、标签数量、个性化评价项等数量,使用的是 Solr facet 机制。

图 4-1
-
单个字段 facet 如好中差评数据量 (上图方框处) 涉及星级字段直接设置 facet.field 参数
/solr /select?q=*:*&wt=json&indent=true&facet=true&facet.field=qualityStar
- 多条件 facet 如有图评价和已追评(上图圆圈处)评价数量,应使用 facet.query 机制把每个 facet.qery 查询当做单独 facet 值,一次性查询出结果而不是发起多次普通总数查询
/solr/select?q=*:*&wt=json&indent=true&facet=true&facet.query=picVideoFlag:1&facet.query=againReviewFlag:1
多维度列表查询
根据查询条件直接查询评价 ID 即可,限制查询字段并支持分页,因商品评价无需计算文档相似度且开启缓存可提升查询性能,故使用 filter query 替代 query 作为查询条件:
/solr/select?q=*:*&fq=(auditStat:0+OR+auditStat:1)&start=0&rows=10&fl=commodityReviewId
需要注意的是 filter cache 是以单个 filter query 为键缓存结果,可以根据业务需求要求拆成多个 filter query,设置不同缓存策略以提升缓存利用率。
分组查询
需要说明的是 Solr 分组关键字 group 的含义与关系型数据库的 group by 中的 group 并不相同,在 Solr 中指的是对查询的结果文档根据指定的字段进行分组,而非关系型数据库对字段分组,如苏宁商品评价需要展示每个评价的第一条商家回复内容,通过 Solr 查询商家回复并根据评价 ID 进行分组后取第一条记录即可(查询条件为评价 ID 列表),参数说明如下:
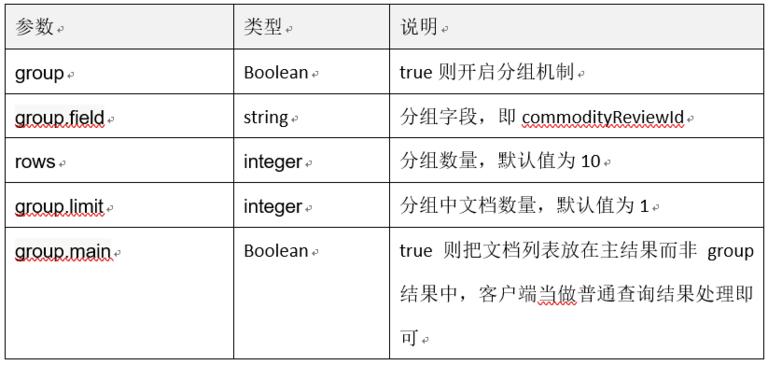
表 4-1
自定义排序
在使用 Solr 对结果集排序一般有两种方式:
-
一是在写入索引时单独字段保存数值,在查询时使用 sort 字段直接排序即可,优点是简单,但调整排序规则时需要重建所有索引。
-
二是函数查询机制,在 Solr 标准查询解析器中使用 solr 内置的函数, 指定 sort 字段为函数内容或在 DisMax 中指定 bf 参数都可以满足业务需求,例如 sort=div(popularity,price)desc,score desc 格式,div 函数表示 popularity 和 price 两个字段相除。
大部分排序都使用第二种方式,但此方式对性能会有影响,特别是在涉及到多个字段时且参与排序的文档数较多时,其内部执行过程需要获取每个匹配 doc 的字段值进行计算,即使字段开启 docValues 特性对存储、IO 和内存空间也有一定压力。
提升函数排序的性能也有两种方式:
- 一是粗略的计算排序值,或写索引时即有一定顺序,查询时进行截断,只返回一定数量的文档,再进行二次排序,即通常电商搜索中粗排和精排过程。
- 二是把涉及到的排序字段合并到一个字段并开启 docValues 特性,例如【评价时间 | 会员等级 | 评价星级 | 内容长度 | 图片个数 | 内容质量分 | 图片质量分 | 人工审核权重】此种格式,并编写自定义函数解析计算这个组合字段的排序值;继承 org.apache.Lucene.queries.function.ValueSource 实现排序值计算,继承 org.apache.solr.search.ValueSourceParser 实现此函数的解析创建即可。这也是苏宁商品评价系统准备采用的方式。
facet.method 参数的选择
Lucene 字段级 facet 有三种机制:
- enum:遍历字段下所有的字典项,对所有字典项的倒排文档 ID 和查询结果文档 ID 进行交集运算得到结果
- fc:根据查询结果的每个文档 ID 从 Field Cache 中查询字段值,计算每个字段值的次数得到结果
- fcs:类似于 fc,不同点是基于 Lucene 中每个段单独的 Field Cache
facet.method 参数指定在对字段进行聚合时使用上述哪种算法,根据上述实现机制说明可知对于值区分度低的字段,适合选择 enum 机制;对于有大量不同值的字段合适使用 fc 机制,若 Solr 开启了近实时搜索 (NRT) 特性,fcs 机制则是更好的选择,因其在生成新索引段时旧索引段缓存不用重新加载。
分布式聚合查询
苏宁易购商品电商模型中 SPU 和 SKU 可以在商品上架时根据产品特性和销售情况动态调整组合,查询 SPU 商品评价时就会出现跨多个节点的场景,需要支持跨节点的分布式查询并对聚合结果集进行二次处理,如数量的累加、列表二次排序和分页等,为此搭建空数据的 Solr 节点作为聚合查询节点。业务方根据 SPU 和 SKU 关系得出节点编号和节点的地址,改写查询请求添加 shards 参数转发给聚合节点即可,示例如下:
/solr/select?q=*:*&wt=json&indent=true&facet=true&facet.query=picVideoFlag:1&facet.query=againReviewFlag:1&shards=solr1:8080/,solr2:8080/,solr3:8080/
此特性原理是使用多线程查询多个 Solr 节点,在内存中对结果进行合并,故使用此特性也有一定限制:
- 列表分页须限制大页码,防止列表合并分页时内存溢出或产生 Full GC 问题,性能急剧下降并可能拖垮服务节点
- 相关性排序和 facet 特性可能与单节点查询结果可能不同
- 注意设置线程池数量和 HTTP 超时时长
- 文档在所有节点必须唯一,不允许重复
- 不支持 pivot facet 和 join 特性
性能调优
-
开启 filter cache,以查询条件为 key,文档 ID 列表为值保存在 cache 中,可以大幅提升数量聚合性能,但需要注意不适合字段值离散度较高的查询,否则产生大量 key 会把 cache 中的热点缓存替换出去,缓存命中率下降反而影响性能,可以通过设置 cache=false 或在函数查询中设置 fq={! cache=false} 参数屏蔽当前请求的 cache 机制
-
文档数较多且命中率低,需要关闭 documentCache 和 queryResultCache
-
设置 newSearcher 和 firstSearcher 两个 Listener 的查询语句,对重新打开的 IndexSearcher 进行预热
-
JVM 使用 CMS GC 策略,并设置 CMSInitiatingOccupancyFraction 值为 60,保证在主从同步时 Solr 有足够的堆内存,降低因 CMS GC 内存碎片导致 Full GC 的风险。
配置示例如下:
<query>
<maxBooleanClauses>2000</maxBooleanClauses>
<filterCache class="solr.FastLRUCache" size="8192" initialSize="4096" autowarmCount="80%" />
<enableLazyFieldLoading>true</enableLazyFieldLoading>
<listener event="newSearcher" class="solr.QuerySenderListener">
<arr name="queries">
<!-- 预加载查询 -->
</arr>
</listener>
<listener event="firstSearcher" class="solr.QuerySenderListener">
<arr name="queries">
<!-- 预加载查询 -->
</arr>
</listener>
<useColdSearcher>false</useColdSearcher>
<maxWarmingSearchers>1</maxWarmingSearchers>
</query>
展望
目前在 CDN 缓存和 Redis 缓存失效情况部分请求的压力还是回源到 Solr,对于 Solr 的直接依赖较大,且更新索引时偶尔还是会触发 Full GC,影响业务的稳定性。下一步需要对缓存架构重新设计,设计缓存异步更新和熔断机制,限制用户请求直接落到 Solr 服务上,提升接口 QPS、系统稳定性和评价展示生效实时性。
另外还在规划引入 Elasticsearch 作为后台业务索引,前后台索引进行分离,降低前后台耦合度和系统风险,更便于业务开发。
作者介绍
胡正林,苏宁易购 IT 总部消费者平台研发中心高级架构师,十余年软件开发经验,熟悉大型分布式高并发系统架构和开发,目前主要负责易购各系统架构优化与大促保障工作。
架构大数据

时间:2018-11-15 22:58 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















