Yoshua Bengio首次中国演讲:深度学习通往人类水平
「机器学习研究不是关于 AI 应该具备哪些知识的研究,而是提出优秀的学习算法的研究。」
11 月 7 日,Yoshua Bengio 受邀来到北京参加第二十届「二十一世纪的计算」国际学术研讨会。会上以及随后受邀前往清华时,他给出了题为「深度学习通往人类水平 AI 的挑战」(Challenges for Deep Learning towards Human-Level AI)的演讲。本文在 Yoshua Bengio 的授权下介绍了整篇演讲。
演讲中,Bengio 以去年发布在 arXiv 的研究计划论文「有意识先验」(The consciousness prior)为主旨,重申了他与 Yann Lecun 十年前提出的解纠缠(disentangle)观念:我们应该以「关键要素需要彼此解纠缠」为约束,学习用于描述整个世界的高维表征(unconscious state)、用于推理的低维特征(conscious state),以及从高维到低维的注意力机制——这正是深度学习通往人类水平 AI 的挑战。
虽然主题看起来比较广大,但实际上,Bengio 讨论了非常多的技术细节内容。

图:Bengio在清华。
Bengio 认为,直观上而言,目前的深度神经网络非常擅长于从文字图像等原始数据抽取高层语义信息,它们会直接在隐藏空间做预测,这就类似于在无意识空间做预测。但是实际上每一次预测所需要的具体信息都非常精简,因此实际上我们可以使用注意力机制挑选具体的信息,并在这种有意识空间进行预测,这种模型和建模方法才能真正理解最初的输入样本。
演讲
今天我将介绍我与合作者共同探讨的一些问题,关于深度学习研究的下一步发展以及如何通向真正人工智能。
在此之前,我想先纠正一个目前看来非常普遍的误解,即「深度学习没有理论依据,我们不知道深度学习是如何工作的。」
我的很多工作都围绕深度学习理论展开。这也是为什么我在大约 12 年前开始研究深度学习的原因。虽然深度学习仍然有诸多未解之谜,但现在我们已经对它的很多重要方面有了更好的理解。
我们更好地理解了为什么优化问题并不像人们想象中那样棘手,或者说局部极小值问题并不像 90 年代的研究者认为的那样是一个巨大障碍。我们更好地理解了为什么像随机梯度下降这样看起来非常「脑残」的方法实际上在优化和泛化方面都非常高效。
这只是我们在过去十年中学到的一小部分,而它们有助于我们理解为什么深度学习真正好用。数学家和理论研究者仍然对此展现出了极大的兴趣,因为深度学习开始在诸多领域变得极为重要。

从人类的两种认知类型解释经典 AI 与神经网络的失败
我今天演讲的主题是「通往人类水平的 AI」:我们试图让计算机能够进行人与动物所擅长的「决策」,为此,计算机需要掌握知识——这是几乎全体 AI 研究者都同意的观点。他们持有不同意见的部分是,我们应当如何把知识传授给计算机。
经典 AI(符号主义)试图将我们能够用语言表达的那部分知识放入计算机中。但是除此之外,我们还有大量直观的(intuitive)、 无法用语言描述的、不能通过「意识」获得的知识,它们很难应用于计算机中,而这就是机器学习的用武之地——我们可以训练机器去获取那些我们无法以编程形式给予它们的知识。

深度学习和 AI 领域有很大进步、大量行业应用。但是它们使用的都是监督学习,即计算机无需真正发掘底层概念、高级表征和数据中的因果关系。事实上,如果你用不同的方式攻击这些模型,就像很多对抗方法所做的那样,仅仅微调输入,也会使模型变得非常愚蠢。

举例来说,我们在一篇论文中改变图像的傅立叶频谱,变换后,图像的类别对于人类来说仍然很明显,但是在自然图像上训练的卷积网络的识别率则变得非常糟糕。
对我来说,现在的系统的失败之处在于,它们无法捕捉我们真正想让机器捕捉到的高级抽象(high level abstraction)。事实上,这是我和合作者希望设计出能够发现高级表征的学习机器的原因:这样的表征可以捕捉构成数据的根本因素。
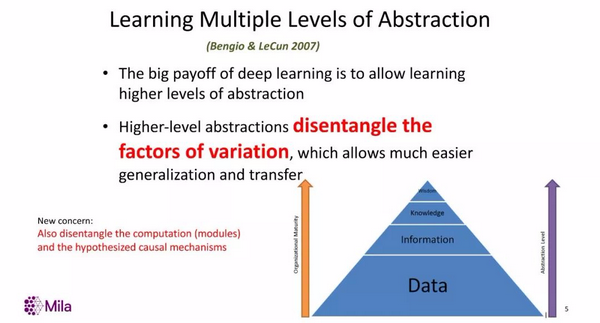
我在大约十年前介绍过「解纠缠」(disentangle)这个概念,即在一个好的表征空间中,不同要素的变化应该可以彼此分离。(而在像素空间中,所有的变化都彼此纠缠着的。)十年之后,我们认为,除了解纠缠变量,我们还希望系统能解纠缠计算。解纠缠和因果的概念相关,而因果正是机器学习界需要重点关注的领域,我将在之后回到这个话题的讨论。

五年前,我在一篇综述论文提出,为了还原那些可以解释数据的根本要素,我们需要引入知识。我们不能只是从零开始学习,还需要对世界作出一些可能比较温和的假设。这对于解纠缠变量会有帮助。空间、时间以及边际独立性可能是一些过于强的假设,但也值得考虑。
一个先验是某些要素对应于世界的某些「可控层面」(controllable aspect)。例如我手上这个翻页器,它有一个三维坐标,而我可以通过移动它改变坐标。这种空间位置体系在我们的大脑中也明确存在,因为这是我们能控制的世界层面。
因此在世界的意图、动作、策略和层面的表征之间有着很强的联系。与其用最底层的像素表征关于世界的信息,对于智能体而言,用更高级的、可交互的、与控制相关的要素来表征信息会方便的多。

在谈及具体的深度学习工作之前,让我先介绍一下心理学家是如何划分人类认知活动的,这有助于我们理解当前深度学习的优势以及我们应该如何走向人类水平的 AI。
人类的认知任务可以分为系统 1 认知(System 1 cognition)和系统 2 认知(System 2 cognition)。系统 1 认知任务是那些你可以在不到 1 秒时间内无意识完成的任务。例如你可以很快认出手上拿着的物体是一个瓶子,但是无法向其他人解释如何完成这项任务。这也是当前深度学习擅长的事情,「感知」。系统 2 认知任务与系统 1 任务的方式完全相反,它们很「慢」。例如我要求你计算「23+56」,大多数人需要遵循一定的规则、按照步骤完成计算。这是有意识的行为,你可以向别人解释你的做法,而那个人可以重现你的做法——这就是算法。计算机科学正是关于这项任务的学科。
而我对此的观点是,AI 系统需要同时完成这两类任务。经典 AI 试图用符号的方法完成系统 2 任务,其失败的原因很多,其中之一是我们拥有的很多知识并不在系统 2 层面,而是在系统 1 层面。所以当你只使用系统 2 知识,你的体系缺少了一部分重要的内容:那些自下而上的有根源知识(Grounded knowledge)。有根源自然语言学习(Ground language learning)是 NLP 的一个子领域,研究者试图用除了文本之外的其他形式,例如图像、视频,去将语言与感知层面的知识联系起来,构建一个世界模型。

意识先验
我接下来将介绍意识先验,意识领域的研究正逐渐变成主流。我在这里将聚焦于意识的最重要问题:当你注意某些东西,或者在你的意识中浮现了某些东西的时候,你意识到了它的某些现实层面情景。
深度学习的表征学习关注信息如何被表征,以及如何管理信息。因此对于意识先验很基本的一个观察是,在特定时刻处于你意识中的想法(thought)是非常低维的。其信息量可能不超过一句话、一张图像,并且处于一个你可以进行推理的空间内。
你可以将一个「想法」看做是经典 AI 中的一条「规则」。每个想法只涉及很少的概念,就像一句话中只有几个单词。从机器学习的角度来看,你可以利用很少的变量进行预测,准确度还很高。这种具有良好性质的低维表征空间是非常罕见的,例如,尝试通过给定的 3 到 4 个像素来预测 1 个像素是不可行的。但是人类可以通过自然语言做到这一点。例如,如果我说「下雨时,人们更可能会撑伞。」这里仅有两个二值随机变量,是否下雨和是否撑伞。并且这种语句具备很强的预测能力。即使它仅使用了很少的变量,也能给出很高概率的预测结果。也就是说,根据很少的信息来执行预测。
因此,我将「意识」称作一个「先验」,是因为意识是一个约束条件、一个正则化项、一个假设:我们可以用非常少的变量进行大量的预测。
满足这些条件意味着我们需要好的空间表征。好的表征的一个特性是当把数据映射到该空间时,变量之间的依赖关系只需要用很少的概念表达(例如规则),且涉及很少的维度。
学习好的表征意味着可以将知识用两种方式表达:在编码器中,将原始数据映射到高级空间;通过规则将变量关联起来并执行预测。
因此我们有两种形式的解纠缠。我以前的论文仅考虑了解纠缠变量,现在我们还考虑了解纠缠规则。如果我们将这些变量看成是代表因果变量的因子,这对应着一种因果机制。因果变量是指在因果陈述中使用的变量,例如「下雨导致人们撑伞」。这些变量需要处在一个好的表征空间来作出因果陈述。像素空间并非能够进行因果陈述的合适表征空间:我们无法说某些像素的改变导致了其它像素的改变,而在因果空间中推理是可行的。
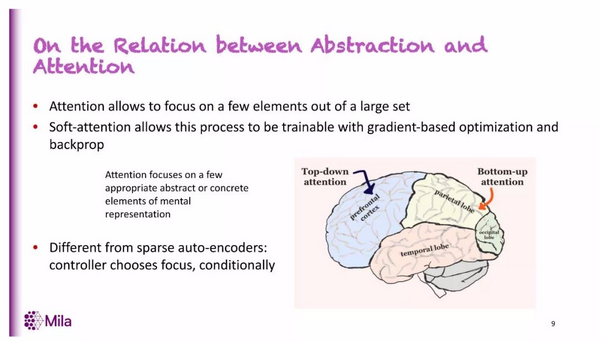
那么要如何实现这种表征呢?对此,注意力机制是一种很重要的工具。注意力机制在过去几年获得了很大的成功,尤其是在机器翻译中,它可以按顺序选取重点关注的信息。
更棒的是你可以使用软注意力来实现整个系统的端到端训练。我们不需要设计一个独立的系统来做这种选择。你可以将注意力机制作为在某些全局目标下端到端训练的更大系统的一部分。而这正是深度学习擅长的地方。
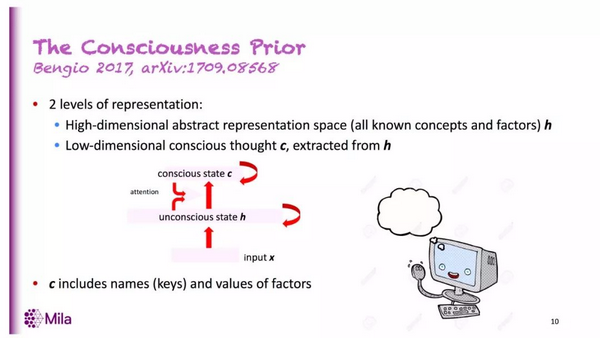
在架构方面,意识先验在「原始输入」和「某些更高级的表征」之外,还引入了第三个层次:这也就是有意识状态(conscious state)。
如上所示无意识状态通常是深度学习所考虑的表征,是模型将数据映射到的一些表示空间。这些隐藏表征通常有非常高的维度与稀疏性,因为任何时候都只有少数变量与输入相关。在此之外,我们还会使用注意力机制选择无意识状态(高维隐藏表征)的几个重要维度,并在有意识状态下表示它们。进入有意识状态的信息就像短期记忆,我们可以使用注意力机制选择一些重要的信息,并通过某种交互表示它们。

这个理论框架还有非常多的细节需要完善,去年我们主要关注其中的一个方面:目标函数。机器学习和深度学习中的标准训练目标函数都基于最大似然估计,而即使与最大似然无关的目标函数,例如 GAN 的一些目标函数,也是在像素级别进行构建的。然而,我们实际上想要在隐藏空间中表现出可预测性。
这很难做到,但我们其实可以训练一些不需要返回到像素空间的机器学习算法,例如主成分分析(PCA)。我们可以像自编码器那样用最小化重构误差训练 PCA:这是在像素空间中构造目标函数,但同时我们也可以在隐藏空间中训练它,例如我们希望降维后的表征每一个都有非常大的方差,从而捕捉到足够多的输入信息。
但我们不止想做 PCA,我们希望有更强大的模型。其中一个很好的扩展概念是互信息(mutual information),它允许我们在编码器输出的隐藏空间中定义目标函数。这个想法很早就已经提出来了,在联接主义的早期,Suzanna Becker 就认为我们应该「寻找数据变换的方法,使空间中的近邻特征拥有比较高的互信息水平」,以此进行无监督图像学习。我认为这是一个被遗忘的重要方向。
注:接下来 Bengio 沿着互信息这个方向介绍了很多研究论文,包括它们的基本过程、核心思想和技术等,这里只给出了研究论文列表,感兴趣的读者可以查看原论文。
Learning Independent Features with Adversarial Nets for Non-linear ICA,ArXiv:1710.05050
MINE: Mutual Information Neural Estimation,ArXiv:1801.04062

意识先验的现实意义:世界模型实现人类水平的语言模型
回到系统 1 和系统 2 认知任务,以及意识先验。这些概念的实际意义是什么?
首先,为了真正理解语言,我们要构建同时具有系统 1 和系统 2 能力的系统。当下的 NLP 算法与 NLP 产品,无论是机器翻译、语音识别、问答系统,还是根本不能理解任何东西的阅读理解,所有这些系统都仅仅是在大型文本语料库和标签上做训练而已。

我认为这样是不够的,你可以从它们犯的错误中发现这一点。举个例子,你可以对系统做个测试,看他们能否消除这些 Winograd 模式歧义句:「The women stopped taking pills because they were pregnant(怀孕).」这里的「they」指什么?是 women 还是 pills?「The women stopped taking pills because they were carcinogenic(致癌)」这句中的「they」又指代什么?事实证明,机器仅仅通过研究样本的使用模式是不足以回答这个问题的,机器需要真正理解「女性」和「药」是什么,因为如果我把「怀孕」换成「致癌」,答案就从「女性」变成了「药」。在人类看来这个问题非常简单,但是现有的机器系统回答起来比随机猜测好不了多少。

当我们想要构建能理解语言的系统时,我们必须问问自己,对于机器而言理解问题或文档意味着什么。如果它们需要相关知识,那么从哪里获取这些知识呢?我们又该如何训练那些具备特定知识的系统?
有一个个思想实验可以帮助我们看清仅在文本上训练模型的局限。想象一下你乘坐宇宙飞船到达另一个星球。外星人说着你听不懂的语言,这时如果你能够捕捉到他们在交流中传达的信息,或许你可以训练语言模型以理解外星语言。而那个星球与地球有一个区别:那里的通信通道不带噪声(地球上的通信通道是有噪声的,因此,人类语音为了在噪声中保持鲁棒性,包含了大量信息冗余。)
由于外星的通信通道没有噪声,因此传输信息的最佳方式是压缩信息。而信息被压缩后,看起来和噪声没什么区别:在你看来,它们交换的都是一些独立同分布的比特信息,语言建模和 NLP 工具也无法帮到你。

这个时候我们该怎么办呢?我们需要做更多工作。仅观察信息本身是不够的,你必须找出它们的意图,理解它们的语境和行为的原因。因此,在语言建模之外,你必须建模环境并理解原因,这意味着大量额外工作。AI 领域研究者「懒惰」又「贪婪」,他们不想进行额外工作,因此他们尝试仅通过观察文本来解决语言理解问题。然而很不幸,这并不会给出有效解决方案。

一种可行方法是先学习一个不错的世界模型,然后基于该模型解决语言问题,就像根据语言模型弄清楚某个单词的意义一样。我认为婴儿在一定程度上就是这么做的,因为婴儿并非一开始就使用语言进行学习,最初它们只是尝试理解环境。但是在某个时间点,将「学习语言模型」和「学习世界模型」两种学习模式结合起来是有益的。

语言可以提供良好表征。因为如果想弄懂这些语义变量,深度学习应该从感知器中提取出语义。比如***妈说「狗」,恰好这时你看到了一只狗,这就很有帮助,因为当你在不同语境中使用这个词时你的感官感知是不同的。这就是监督学习性能好的原因。
事实上,以监督学习方式训练出的深层网络的表征比无监督模型好很多,最起码对于目前的无监督学习来说。我认为应该将二者结合起来,不过你必须理解世界的运行方式。世界运行方式的一个方面是因果关系,机器学习目前对此缺乏关注。

具体而言,我们的学习理论在这方面仍然很匮乏。目前的学习理论假设测试分布与训练分布相同,但是该假设并不成立。你在训练集上构建的系统在现实世界中可能效果并不好,因为测试分布与训练分布不同。
因此我认为我们应该创建新的学习理论,它应该不会基于「测试分布与训练分布相同」这样生硬的假设。我们可以采用物理学家的方式,假设训练分布和测试分布的底层因果机制相同。这样即使动态系统的初始条件不同,底层物理机制仍然不会改变。

那么如何去做呢?事实上,构建好的世界模型令人望而生畏,我没有足够的计算能力对真实世界建模,因此我认为更合理的方法是利用机器学习,机器学习研究不是关于 AI 应该具备哪些知识的研究,而是提出优秀的学习算法的研究。优秀的机器学习算法理应在任何分布中都可以良好运行。
近年来深度学习社区涌现了大量关于搭建虚拟环境的研究,如在深度强化学习体系下,人们构建虚拟环境并在其中测试不同的智能体学习步骤。深度强化学习最酷的一点是便于做科学实验,我们可以借助虚拟环境测试理论,更快速地获取反馈。

在我实验室开始的一个项目,是 1971 年 Winograd 用 SHRDLU 系统进行 blocks world 实验的延伸。他们当初试图建立一个能够用自然语言执行任务的系统,比如「拿起一个红色的木块」,但他们试图用基于规则的经典 AI 来实现目标。这在某种程度上起作用了,但它和大多数规则系统一样非常脆弱。它无法扩展,因为你需要手动设计大量知识,像当前大多数脆弱且无法扩展的对话系统一样。我认为,除非我们真正做更多的基础研究,否则这种情况不会改善。
BabyAI 平台:模拟世界模型

所以我们构建了一个叫做 BabyAI(或 BabyAI game)的平台,其中设置了有一个「学习者」和一个「人类」的游戏或场景。
学习者就是「baby AI」,我们要为学习者设计学习算法,而其中的人类与学习者互动,并使用自然语言帮助它理解周围的环境。人类可以通过课程学习(curriculum learning)、为学习者设计正确的问题以及考虑学习者知道什么和不知道什么等等来帮助它。当然了,课程学习本身就是一个有趣的研究领域,因为如果我们能够构建出计算机与人类互动的更好系统,那也会非常有用。
所以我们在 2D 网格世界中构建了一个非常简单的环境,并能在其中使用类似「把蓝色钥匙放在绿色的球旁边」这种简单的自然语言表述。

在这个阶段,我们有 19 个学习者应该能够学习的难度级别和任务类型。我们还设计和训练了一个知道如何解决任务的启发式专家。当然,这个专家扮演的是人类的角色,因为在这个阶段,我们实际上还不想让人类参与进来。所以我们希望能够模拟人类,然后查看和测试不同的学习者表现如何。
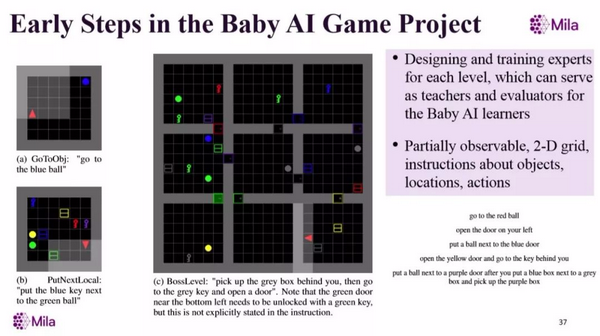
我们有更大的版本,不同级别有不同的房间数量和不同类别的任务。我们定义了一系列的概念,比如房间和迷宫,也定义了一系列动作,如去某个地方、打开、捡、放等等,以及使用这些概念的不同任务。当你进阶学习更加复杂的任务,需要的概念也越来越多。

但是,我们目前尝试过的机器学习方法还做不到这一点。如果我们有真正的人类来教 baby,他们就不需要给 baby 提供成百上千的轨迹示例。
我们尝试了模仿学习和强化学习。在强化学习中,人类会提供奖励。在学习者收敛之前,他需要在数百万轨迹上提供数百万条奖励。但即使是效率更高的模仿学习(类似监督学习),如果要从模仿示例中学习,对于一个人来说,花时间训练这些系统还是远远超出了我们认为的合理范围。
我们还发现当前的系统可以非常快速地学习来做这样的工作,但要达到 99% 的正确回答率还需要大量训练。因此我们认为可以用这些基准来研究简单效率数据、不同学习程序效率。

时间:2018-11-11 23:48 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]2021年进入AI和ML领域之前需要了解的10件事
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
- [机器学习]来自Facebook AI的多任务多模态的统一Transformer:向
- [机器学习]一文详解深度学习最常用的 10 个激活函数
- [机器学习]AAAI21最佳论文Informer:效果远超Transformer的长序列
- [机器学习]深度学习中的3个秘密:集成、知识蒸馏和蒸馏
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]深度学习三大谜团:集成、知识蒸馏和自蒸馏
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]GPT-2大战GPT-3:OpenAI内部的一场终极对决
相关推荐:
网友评论:















