迷人又诡异的辛普森悖论:同一个数据集是如何
想象一下下面这个场景。
你和你的小伙伴准备找个地方搓一顿,但在两家餐厅的选择上争执不休。
于是乎,秉持“数据驱动人生”的你俩搬出了小众点评网的评分数据。
你发现,你想去的这家餐厅的评分果然比另一家高。
正当你得意不已的时候,你的小伙伴宣布了TA的发现:另一家餐厅的评分更高。
这是咋回事呢?莫非评论网站的数据还出错了不成?
事实上,你和你的小伙伴都是对的,你们只是在不知不觉中掉进了辛普森悖论的诡计。
在辛普森悖论中,餐馆可以同时比竞争对手更好或更差,锻炼可以降低和增加疾病的风险,同样的数据集能够用于证明两个完全相反的论点。
相比于晚上出去大餐,你和小伙伴也许更值得讨论这个吸引人的统计现象。
辛普森悖论指的是,数据集分组呈现的趋势与数据集聚合呈现的趋势相反的现象。
在上面餐厅推荐的例子中,你可以通过看男性和女性各组的评分,也可以看整体的评分。如下图所示。
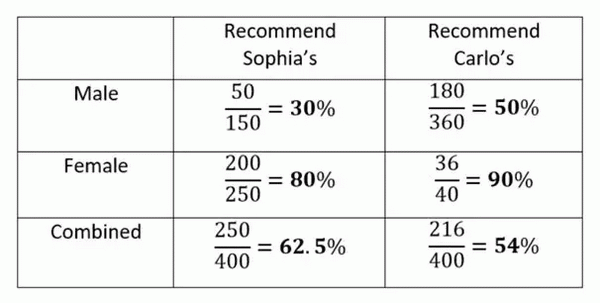
这怎么可能呢?这里的问题在于,只查看单独各组数据的百分比会忽略掉样本的大小,也就是评论者的人数。每个百分比都由推荐用户数与相对应的评论人数计算得到。Carlo’s 有更多的男性评论者,而Sophia’s 有更多的女性评论者,因此导致了矛盾的结果。
要想回答该去哪家餐厅的问题,我们需要考虑数据是否可以合并,或者是否应该单独考虑。我们是否应该合并数据取决于数据的生成过程——即数据的因果模型。在下一个例子中,我们将介绍这一具体含义以及如何解决辛普森悖论。
相关性反转
辛普森悖论的另一个有趣的现象表现在,分层组数据表现的相关性方向与整体数据表现的相关性方向截然相反。我们来看一个简化后的例子。假设我们有每周运动小时数与两组患者(分别为50岁以下和50岁以上的患者)患病风险的对比数据。以下是各组运动数据与患病可能性的散点图。
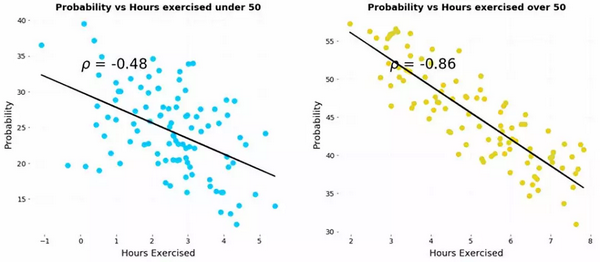
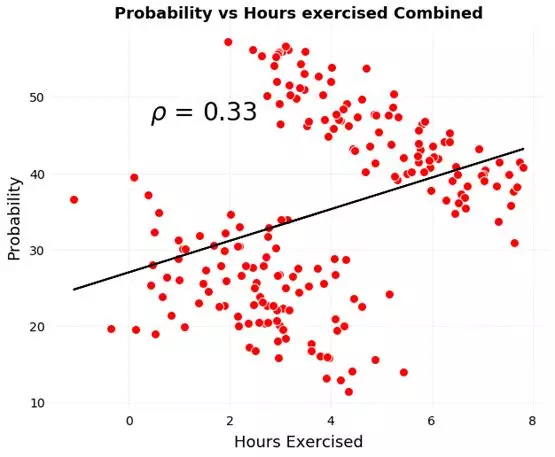
运动如何既减少又增加疾病风险呢?其实并不然,要想弄清如何解决这个悖论,我们需要从数据的生成过程来考虑展示的数据和原因——是什么产生了这些结果。
解决悖论
为了避免辛普森悖论导致得出两个相反的结论,我们需要选择将数据分组还是合并。这听起来似乎很简单,但到底应该如何抉择?答案就是因果性思考:数据是如何产生的?并且在此基础上,哪些我们没看到的因素在影响结果?
在运动与疾病的例子中,我们直观地知道运动不是影响发病率的唯一因素。这里还有其他因素,如饮食、环境、遗传因素等。但是,在上图中,我们只看到了发病率与运动时间的关系。在这个假设的例子中,我们假设疾病是由运动和年龄引起的。用下面的疾病概率的因果模型来表示他们的关系。
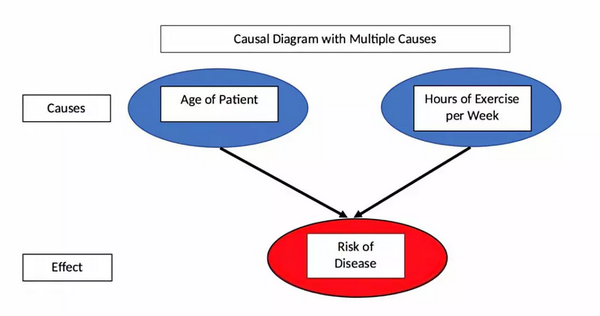
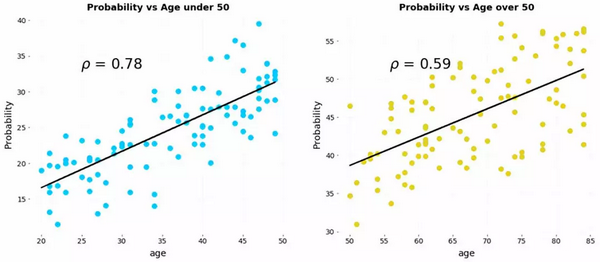
一种实现的方式是将数据分成几组,通过这种方式,我们可以看到,对于给定年龄组,运动可以降低患病风险。也就是说,在控制年龄因素的情况下,运动与低患病率相关。根据数据生成过程和应用因果模型,我们可以通过数据分层来控制附加因素解决辛普森悖论。
思考需要回答的问题也可以帮助我们解决悖论。在餐厅的例子中,我们想知道哪家餐厅最有可能让我和小伙伴都满意。虽然除了餐厅本身质量,还可能存在其他因素影响评论,但在没有这些潜在数据的情况下,我们希望将所有评论结合在一起来看看整体平均结果。在这种情况下,分析合并后的数据更有意义。
在运动与疾病案例中需要提出的相关问题是,我们自己是否应该增加运动来减少个体患病风险?由于我们的年龄或者处于小于50/大于50两个区间内(这里不考虑年龄正好为50岁的情况),我们需要根据具体年龄观察对应的数据组,而且无论我们属于哪组,结论都显示确实应该多锻炼。
想想数据生成过程,要回答我们的问题所需要的不仅仅是观察数据本身。这几乎揭示了辛普森悖论中最关键的一点:数据本身是不够的。数据从来都不是完全客观的,特别是当我们只看最后展示的图表时,我们需要考虑是否看到了全貌。
我们可以尝试观察得更全面,通过思考什么生成了数据,又有哪些未展示因素对数据产生了影响。这些问题的回答常常揭示着我们实际应该得出完全相反的结论!
现实生活中的辛普森悖论
辛普森悖论与其它一些统计概念不同,它并非是人为发明的纯理论概念,在现实生活中会实实在在地发生。
事实上,已经有很多著名的辛普森悖论案例了。
其中一个案例是关于两种肾结石治疗效果的数据。单独看治疗效果方面的数据,A疗法对治疗两种大小的肾结石的效果都更好,但是将数据合并后发现,B疗法针对所有情况的疗效更优。下表展示了康复率:
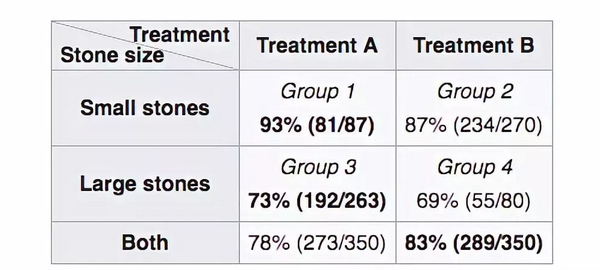
在这则现实例子中,肾结石的大小,或者说病症的严重性,被称为混淆因子;它对自变量(治疗方法)和因变量(康复率)都有影响。我们在数据表里是看不到混淆因子的,但它们可以体现在因果关系图中:

或者还可以这样看待这个问题:对小结石而言,A疗法更优;严重一些的大结石,依然是A疗法更优。因此,不论结石的大小程度,A疗法总是最优——悖论解决。
合并数据有时很有用,但有些情况下却对真实情况产生了干扰。
证明一个论点,又能证明其相反的观点
辛普森悖论也是政客们的常用伎俩。

下面这个例证展示了,辛普森悖论是如何证明两个相反的政治观点的。
下表表明,在福特总统的1974~1978年的任期中,他对每个收入人群都进行了减税,但此期间全国性的税收额有明显上涨。数据展示如下:
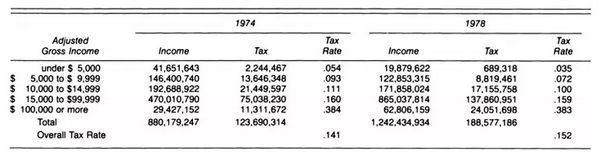
是否要合并数据,取决于在数据生成过程之外,还包括我们想了解什么问题,又或者是我们的政治观点究竟是什么。从个人角度来说,我们只是一个个体,关心的是在个人的税收区间内的税率。要搞清楚从1974年到1978年间,个人所得税到底有没有增长,必须要弄清楚我们税收区间的税率是否发生了变化,以及我们的税收区间是否到了一个新的区间中。个人所得税受两个因素影响,但这张表格的数据只展示了其中一个。
辛普森悖论有何意义
辛普森悖论的重要性在于它揭示了我们看到的数据并非全貌。我们不能满足于展示的数字或图表,我们需要考虑整个数据生成过程,考虑因果模型。一旦我们理解了数据产生的机制,我们就能从图表之外的角度来考虑问题,找到其它影响因素。大部分数据科学家并没有学习因果思考的模式,而这种思考模式对我们而言至关重要,因为它能防范我们从数据中得出错误结论。除了使用数据,我们需要运用经验和业务知识,或者向专家学习,来更好地进行决策。
此外,虽然我们的直觉常常很准,但在现有信息不全的情况下直觉还是会不准。我们倾向于对只关注眼前的东西(所见即所得)而不是用我们理性而迟缓的思考去挖掘更深层的东西。我们需要对数字本身持怀疑态度,尤其是当别人想向我们营销产品或项目计划时。
数据是一个有力的武器,它既能被用来澄清现实,也能被用来混淆是非。
相关报道:https://towardsdatascience.com/simpsons-paradox-how-to-prove-two-opposite-arguments-using-one-dataset-1c9c917f5ff9

时间:2018-10-27 14:05 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]阿里开源3D-FUTURE数据集 建模时间可从3小时降至10秒
- [机器学习]MIT研究人员发现 ImageNet 数据集存在系统性缺陷
- [机器学习]NVIDIA针对数据不充分数据集进行生成改进,大幅
- [机器学习]数据集永久下架,微软不是第一个,MIT 也不是最
- [机器学习]NVIDIA针对数据不充分数据集进行生成改进,大幅
- [机器学习]微软新作,ImageBERT虽好,千万级数据集才是亮点
- [机器学习]谷歌刚刚发布了2500万个免费数据集,了解一下
- [机器学习]19个数据科学项目的免费公共数据集
- [机器学习]亚马逊研究人员使用NLP数据集来改善Alexa的答案
- [机器学习]如何为数据集选择正确的聚类算法
相关推荐:
网友评论:















