有赞搜索系统的技术内幕
上文说到有赞搜索系统的架构演进,为了支撑不断演进的技术架构,除了 Elasticsearch 的维护优化之外,我们也开发了上层的中间件来应对不断提高的稳定性和性能要求。
Elasticsearch 的检索执行效率可以表示为:
_O(num_of_files _logN)*
其中 num_of_files 表示索引文件段的个数,N 表示需要遍历的数据量,从这里我们可以总结出提升查询性能可以考虑的两点:
- 减少遍历的索引文件数量
- 减少遍历的索引文档总数
从 Elasticsearch 自身来说,减少索引文件数量方面可以参考几点:
- 通过 optimize 接口强制合并段
- 增大 index buffer/refresh_interval,减少小段生成,控制相同数量的文档生成的新段个数
不论是强制合并或者 index buffer/refresh_interval,都有其应用场景的限制,比如调整 index buffer / refresh_interval 会相应的延长数据可见时间;optimize 对冷数据集比较适用,如果数据在不断变化过程中,除了新段的生成,老数据可能因为旧段过大而得不到物理删除,反而造成较大的负担。
而减少文档总数方面,也可以做相应的优化:
- 减少文档更新
- 指定 _routing 来路由查询到指定的 shard
- 通过 rollover 接口进行冷热隔离
这里尤其需要注意的是减少文档更新,由于 LSM 追加写的数据组织方式,更新数据其实是新增数据 + 标记老数据为删除状态的组合,真实参与计算的数据量是有效数据和标记删除的数据量之和,减少文档更新次数除了减少标记删除数据之外,还可以降低段 merge 以及索引刷新的消耗。
考虑到实际的业务场景,如果将海量数据存储于单个索引,由于 shard 个数不可变,一方面会使得索引分配大量的 shard,数据量持续增长会逐渐拖慢索引访问性能,另一方面想要通过扩展 shard 提高读写性能需要重建海量数据,成本相当高昂。
索引拆分
为了增强索引的横向扩容能力,我们在中间件层面进行了索引拆分,参考实际的业务场景将大索引拆分为若干个小索引。
在索引拆分前,首先需要检查索引对应业务是否满足拆分的三个必要条件:
- 读写操作必定会带入固定条件
- 读写操作维度唯一
- 用户不关心全局的搜索结果
比较典型的比如店铺内商品搜索,不论买卖家都只关心固定店铺内的商品检索结果,没有跨店铺检索需求,后台店铺与商品也有固定的映射关系,这样就可以在中间件层面对读写请求进行解析,并路由到对应的子索引中,减少遍历的文档总量,可以在性能上获得明显的提升。
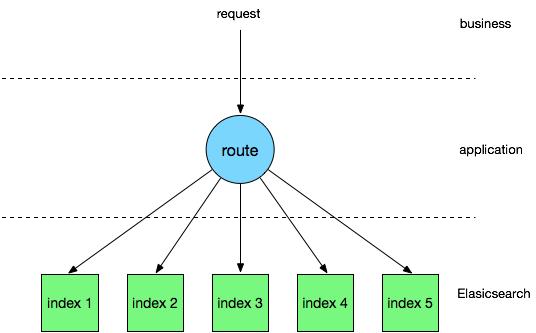
相对 Elasticsearch 自带的 _routing,这个方案具备更加灵活的控制粒度,比如可以配置白名单,将部分店铺数据路由到其他不同 SLA 级别的索引或集群,当然可以配合 _routing 以获得更好的表现。
索引拆分首先会带来全局索引文件数据上升的问题,不过因为没有全局搜索需求,所以不会带来实质的影响;其次比较需要注意的是数据倾斜问题,在拆分前需要先通过离线计算模拟索引拆分效果,如果发现数据倾斜严重,就可以考虑将子索引数据进行重平衡。
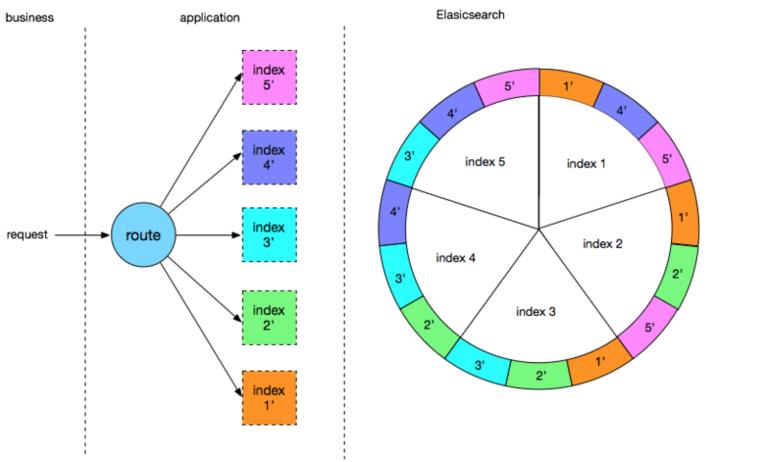
如图所示,数据重平衡在原有的拆分基础上加入一个逻辑拆分步骤:
- 数据首先拆分为 5 个逻辑索引
- 设定重平衡因子,假设为 N
- 根据重平衡因子将逻辑索引数据顺序哈希到 N 个连续的物理索引中
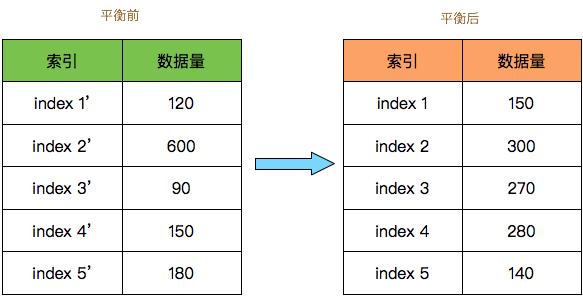
如图,按平衡因子 3 重平衡之后文档数据量的最大差值从 510 降为了 160,单索引占全局数据量比例从之前的 53% 降低为 26%,能够起到不错的数据平衡效果。
冷热隔离
在查询维度不唯一的场景下,索引拆分就不适用了,为了解决此类场景下的性能问题,可以考虑对索引进行冷热隔离。
比如日志 / 订单类型的数据,具备比较明显的时间特征,大量的操作都集中在近期的一段时间内,这时就可以考虑依据时间字段对其拆分为冷热索引。
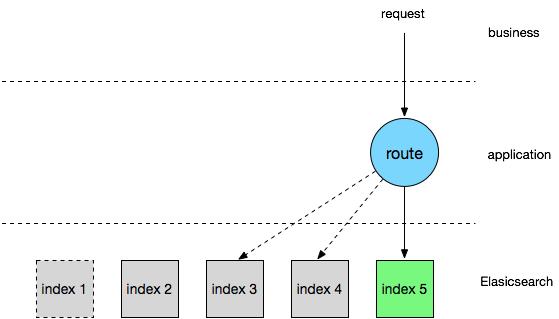
Elasticsearch 自带有 rollover 接口供索引进行自动轮转,通过索引存活时间和保存的文档数量作为轮转条件,满足其中之一即可创建一个新索引并将其作为当前的活跃索引。
在实际应用过程中,rollover 接口需要用户感知活跃索引的变更,且自行计算查询需要访问的索引范围,为了对用户屏蔽底层这些复杂操作的细节,我们在中间件封装了索引的冷热隔离特性,从用户视角只须访问固定索引并带入固定字段即可。
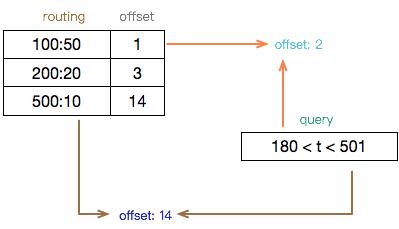
首先配置路由表,根据不同的时间跨度划定不同的路由规则,比如业务初期数据增量并不大,可以用 50 的时间跨度创建子索引,后期业务增量变大后逐渐缩短时间跨度至 10 来创建子索引。
通过查询条件的起止时间点分别从路由表中计算对应的子索引偏移量,得到起止范围,以上图为例,连续的子索引范围为 index2~index14,也就是该条件将命中此区间内的全部子索引,写操作也类似,区别在于写数据只会落到一个子索引,一般是当前的活跃索引。
这样冷热隔离的方式拆分可以兼容多维度的查询需求,比如订单的买卖家查询维度,而且拆分规则比较灵活,可以动态调整,另外删除数据只需要删除整个过期索引,而不必通过 delete_by_query 的方式缓慢删除索引数据。
除此之外,为了更好的配合用户使用,我们还对此开发了索引的自动轮转 / 定时清理等辅助功能。
HA
随着搜索系统的广泛使用,用户对系统的稳定性也提出了更高的要求,比如在机房发生断电等故障情况下,依然能够保证服务可用,这就需要我们能够将数据进行跨机房复制同步。
首先考虑的方案是跨机房组建 Elasticsearch 集群,这样实现非常简单,但是问题是机房的网络交互是走专线的,在集群宕机恢复数据过程中会有很大的带宽消耗,可能引起机房间的网络拥堵,因此这个方案并不可行。
Elasticsearch 本身也在开发 Changes API 特性,可以用于跨集群的数据同步,但可惜的是该特性仍然在开发中,在参考了主流的数据同步方法后,我们在中间件层开发了一套异步数据复制系统。
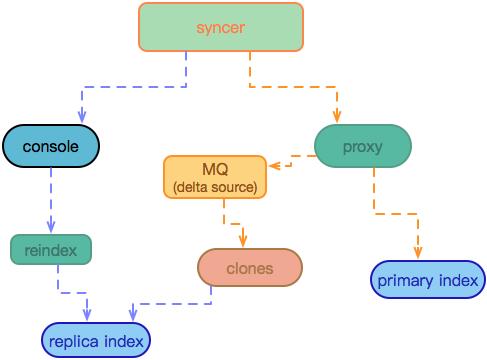
在确认索引开启多机房复制后,首先在 proxy 侧启动增量同步,发送同步消息给 mq 作为同步程序 clones 的增量数据源,然后通过 reindex 功能从主索引全量复制数据到从索引。
在跨机房同步过程中,数据容易因为 MQ、proxy 异步发送等影响而乱序,Elasticsearch 可以通过乐观锁来保证数据变更的一致性,避免乱序的影响,前提是 version 能够一直保持在索引中。
但是在物理删除模式下,由于数据被物理清理,无法继续保持版本号的延续,这就有可能导致跨机房数据同步的脏写。
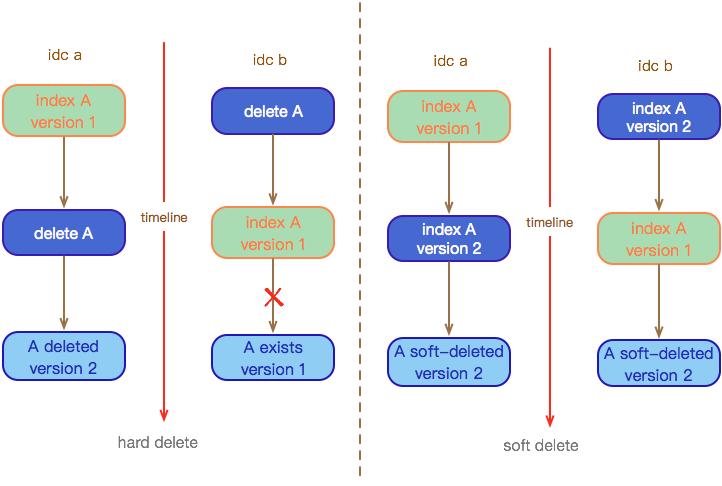
为了避免乐观锁失效,我们的解决方法是软删除的方式:
- delete 操作在中间件转换为 index 操作,文档内容仅包含一个特殊字段,不会命中正常的搜索条件,也就是正常情况下无法搜索得到该文档,达到实际的删除效果
- 在中间件将 create/get/update/delete 等操作转换为 script 请求,保持原有语义不变
- 通过软删除文档中特殊字段记录的时间戳定时清理数据(可选)
为了能够感知到主从索引间的数据一致性和同步延迟,还有一套辅助的数据对账系统实时运行,可以用于主从索引数据的校验、修复并通过 MQ 消费延时计算主从数据的延迟。
小结
到这里有赞搜索系统的大致框架已经介绍完毕,因为篇幅的原因还有很多细节的功能设计并没有完整表述,也欢迎有兴趣的同学联系我们一起探讨,有表述错误的地方也欢迎大家联系我们纠正。
关于 Elasticsearch 方面本次的两篇文章都没有太多涉及,后续待我们整理完善之后会作为一个扩展阅读奉送给大家。

时间:2018-10-16 18:12 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Attention!当推荐系统遇见注意力机制
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]万物皆可Graph | 当推荐系统遇上图神经网络
- [机器学习]ResNet、Faster RCNN、Mask RCNN是专利算法吗?盘点何恺
- [机器学习]YOLO算法最全综述:从YOLOv1到YOLOv5
- [机器学习]推荐系统架构与算法流程详解
- [机器学习]YOLO算法最全综述:从YOLOv1到YOLOv5
- [机器学习]贝尔实验室和周公“掰手腕”:AI算法解梦成为现
- [机器学习]性能超越GPU、FPGA,华人学者提出软件算法架构加
- [机器学习]GPT-3的威力,算法平台的阴谋
相关推荐:
网友评论:















