不堆砌公式,用最直观的方式带你入门深度学习
因为近期要做一个关于深度学习入门的技术分享,不想堆砌公式,让大家听得一头雾水不知不觉摸裤兜掏手机刷知乎。所以花了大量时间查资料看论文,有的博客或者论文写得非常赞,比如三巨头 LeCun,Bengio 和 Hinton 2015 年在 Nature 上发表综述论文的“Deep Learning”,言简意赅地引用了上百篇论文,但适合阅读,不适合 presentation 式的分享;再如 Michael Nielsen 写的电子书《神经网络与深度学习》(中文版,英文版)通俗易懂,用大量的例子解释了深度学习中的相关概念和基本原理,但适合于抽两三天的功夫来细品慢嚼,方能体会到作者的良苦用心;还有 Colah 写的博客,每一篇详细阐明了一个主题,如果已经入门,这些博客将带你进阶,非常有趣。
还翻了很多知乎问答,非常赞。但发现很多”千赞侯”走的是汇总论文视频教程以及罗列代码路线,本来想两小时入门却一脚踏进了汪洋大海;私以为,这种适合于有一定实践积累后按需查阅。还有很多”百赞户”会拿鸡蛋啊猫啊狗啊的例子来解释深度学习的相关概念,生动形象,但我又觉得有避重就轻之嫌。我想,既然要入门深度学习,得有微积分的基础,会求导数偏导数,知道链式法则,最好还学过线性代数;否则,真的,不建议入门深度学习。
最后,实在没找到我想要的表达方式。我想以图的方式概要而又系统性的呈现深度学习所涉及到的基本模型和相关概念。论文“A Critical Review of Recurrent Neural Networks for Sequence Learning”中的示意图画得简单而又形象,足以说明问题,但这篇文章仅就 RNN 而展开论述,并未涉及 CNN,RBM 等其它经典模型;Deeplearning4j上的教程貌似缺少关于编码器相关内容的介绍,而UFLDL 教程只是详细介绍了编码器的方方面面。但是如果照抄以上三篇的图例,又涉及到图例中的模块和符号不统一的问题。所以,索性自己画了部分模型图;至于直接引用的图,文中已经给了链接或出处。如有不妥之处,望指正。以下,以飨来访。
1. 从经典的二分类开始说起,为此构建二分类的神经网络单元,并以 Sigmoid 函数和平方差损失(比较常用的还有交叉熵损失函数)函数来举例说明梯度下降法以及基于链式法则的反向传播(BP),所有涉及到的公式都在这里:
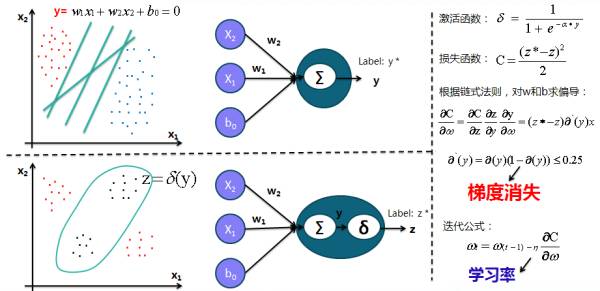
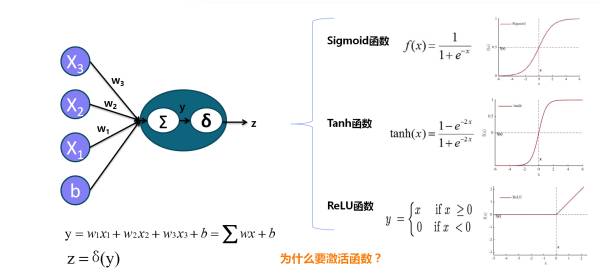
2. 神经元中的非线性变换激活函数(深度学习中的激活函数导引)及其作用(参考颜沁睿的回答),激活函数是神经网络强大的基础,好的激活函数(根据任务来选择)还可以加速训练:
3. 前馈性神经网络和自动编码器的区别在于输出层,从而引出无监督学习的概念;而降噪编码器和自动编码器的区别又在输入层,即对输入进行部分遮挡或加入噪声;稀疏编码器(引出正则项的概念)和自动编码器的区别在隐藏层,即隐藏层的节点数大于输入层节点数;而编码器都属于无监督学习的范畴。浅层网络的不断栈式叠加构成相应的深度网络。
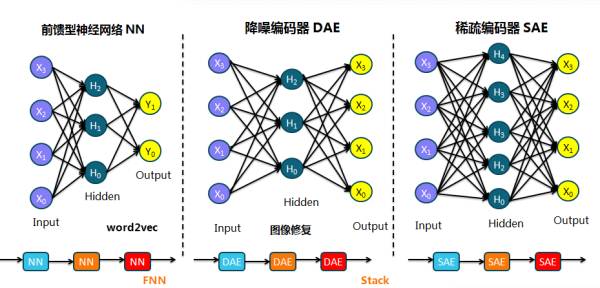
值得一提的是,三层前馈型神经网络(只包含一个隐藏层)的 word2vec(数学原理详解)是迈向 NLP 的大门,包括 CBOW 和 skip-gram 两种模型,另外在输出层还分别做了基于 Huffman 树的 Hierarchical Softmax 以及 negative sampling(就是选择性地更新连接负样本的权重参数)的加速。
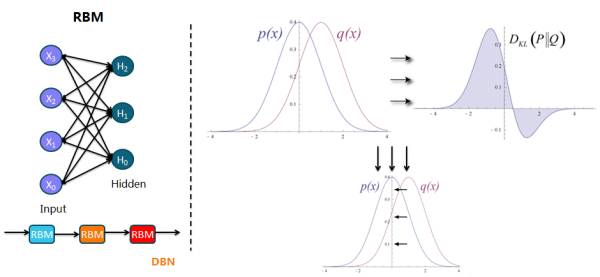
4. 受限波兹曼机 RBM 属于无监督学习中的生成学习,输入层和隐藏层的传播是双向的,分正向过程和反向过程,学习的是数据分布,因此又引出马尔可夫过程和 Gibbs 采样的概念,以及 KL 散度的度量概念:
与生成学习对应的是判别学习也就是大多数的分类器,生成对抗网络 GAN 融合两者;对抗是指生成模型与判别模型的零和博弈,近两年最激动人心的应用是从文本生成图像(Evolving AI Lab – University of Wyoming):

5. 深度网络的实现基于逐层贪心训练算法,而随着模型的深度逐渐增加,会产生梯度消失或梯度爆炸的问题,梯度爆炸一般采用阈值截断的方法解决,而梯度消失不易解决;网络越深,这些问题越严重,这也是深度学习的核心问题,出现一系列技术及衍生模型。
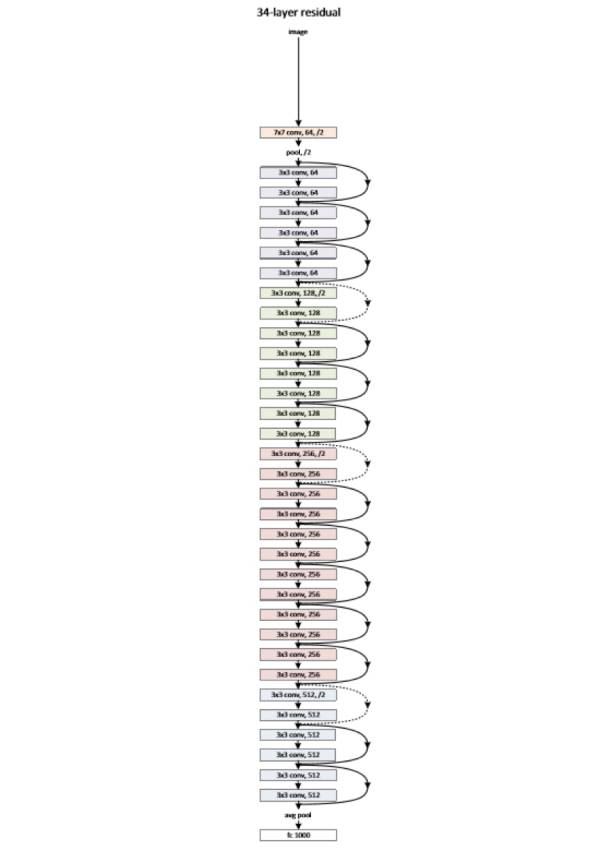
深度制胜,网络越深越好,因此有了深度残差网络将深度扩展到 152 层,并在 ImageNe 多项竞赛任务中独孤求败:
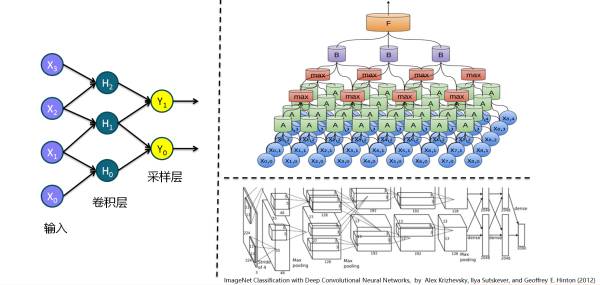
6. 卷积神经网络在层与层之间采取局部链接的方式,即卷积层和采样层,在计算机视觉的相关任务上有突出表现,关于卷积神经网络的更多介绍请参考我的另一篇文章(戳戳戳):
而在 NIPS 2016 上来自康奈尔大学计算机系的副教授 Killan Weinberger 探讨了深度极深的卷积网络,在数据集 CIFAR-10 上训练一个 1202 层深的网络。
7. 循环神经网络在隐藏层之间建立了链接,以利用时间维度上的历史信息和未来信息,与此同时在时间轴上也会产生梯度消失和梯度爆炸现象,而 LSTM 和 GRU 则在一定程度上解决了这个问题,两者与经典 RNN 的区别在隐藏层的神经元内部结构,在语音识别,NLP(比如 RNNLM)和机器翻译上有突出表现(推荐阅读):
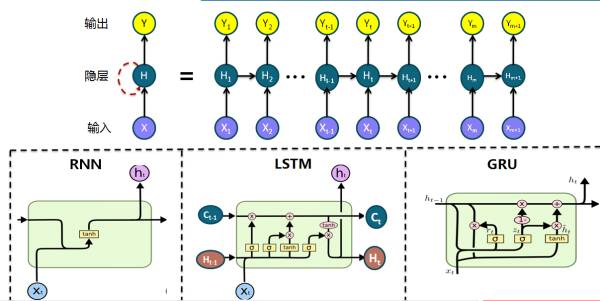
除了 RNNLM 采用最简单最经典的 RNN 模型,其他任务隐层神经元往往采用 LSTM 或者 GRU 形式,关于 LSTM 的进化历史,一图胜千言,更多内容可以参阅LSTM: A Search Space Odyssey:
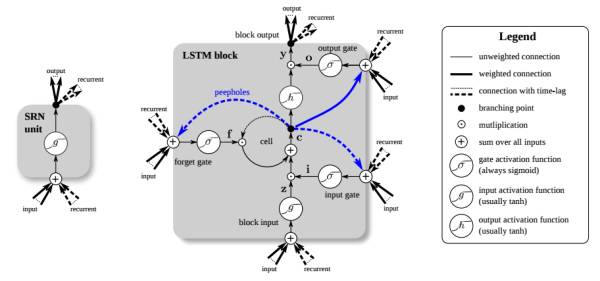
RNN 模型在一定程度上也算是分类器,在图像描述(Deep Visual-Semantic Alignments for Generating Image Descriptions)的任务中已经取得了不起的成果(第四节 GAN 用文本生成图像是逆过程,注意区别):

另外,关于 RNN 的最新研究是基于 attention 机制来建立模型(推荐阅读文章),即能够在时间轴上选择有效信息加以利用,比如百度 App 中的”为你写诗“的功能核心模型就是 attention-based RNN encoder-decoder:
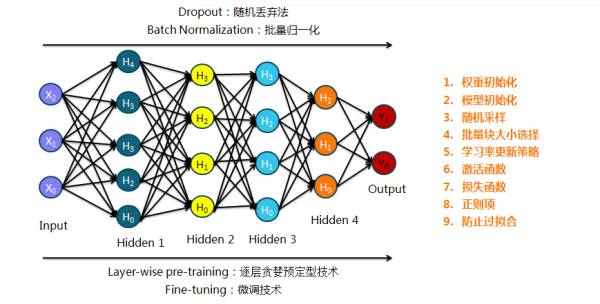
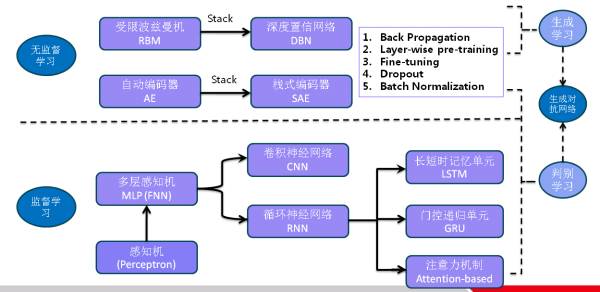
8. 总结了深度学习中的基本模型并再次解释部分相关的技术概念:
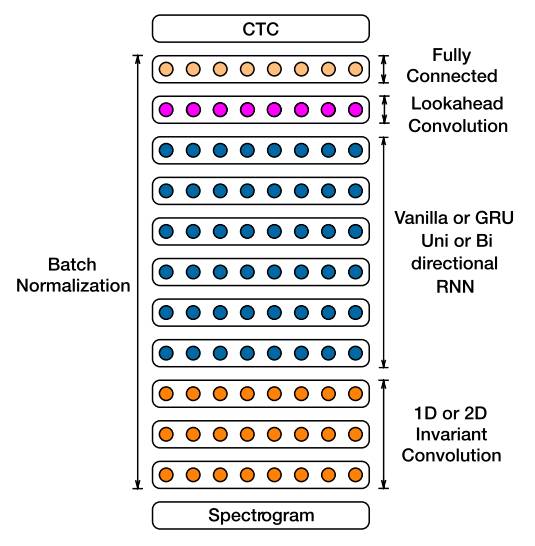
最后,现在深度学习在工业中的应用往往是整合多个模型到产品中去,比如在语音识别的端到端系统中,利用无监督模型或者 CNN 作为前期处理提取特征,然后用 RNN 模型进行逻辑推理和判断,从而达到可媲美人类交流的水平,如百度的DeepSpeech2:
画图是个细活慢活,周末加班很辛苦,觉得好就动动手指给个赞吧。
不喜请喷,转载请注明出处,谢谢。

时间:2018-10-16 18:08 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















