《Credit Risk Scorecard》 第六章: Scorecard Development
第六章:Scorecard Development Process, Stage 4: Scorecard Development
开发流程: 对于申请评分卡(A 卡)来说,下面是整个开发流程。对于行为评分卡(B卡)来说,除了没有拒绝推断外,基本是一样的。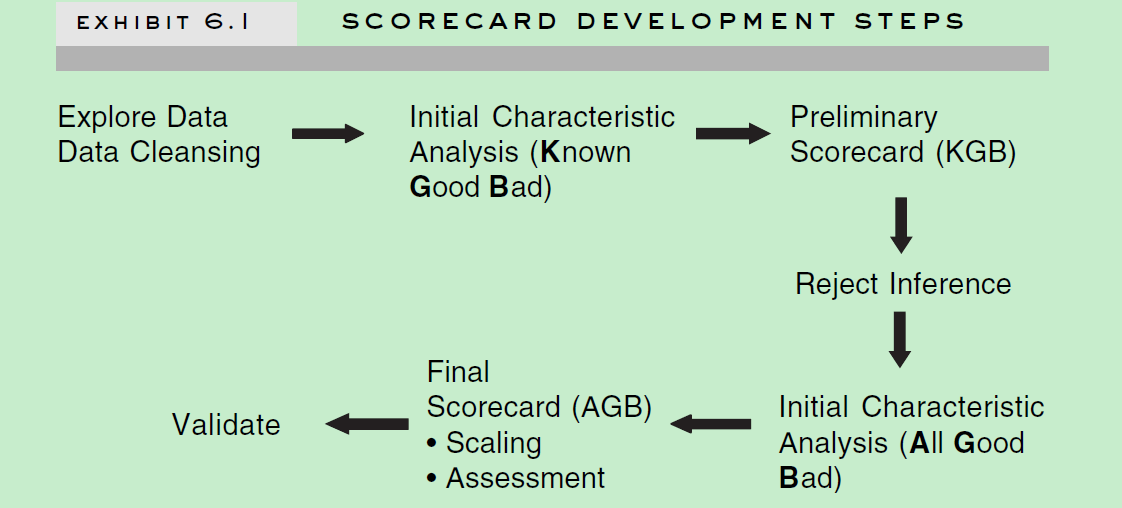
Explore Data : 数据收集和处理相关的。之前章节已经提到过
Missing Values and Outliers: 主要对缺省值和异常值处理,这里涉及方法比较多,0值填充,均值填充,中值填充,按分位点过滤异常值等。
Correlation:变量之间相关性,多重共线性。变量相关性常见的分析方法通过变量聚类(varclus),对变量进行分组,对每个分组的变量选取少数代表性高的变量,可以通过iv值来选或者根据业务逻辑选择等。多重共线性其实不是十分关注,增加样本量就会降低多重共线性可能,或者通过正则化进行处理。
Initial Characteristic Analysis
一般采用woe (weight of evidence), IV (informance value)去进行统计分析。woe去统计特征各个属性预测强度,IV去计算特征的重要性。
woe公式如下:

IV 值如下:
关于age的分组属性的分析如下,包括了woe和iv值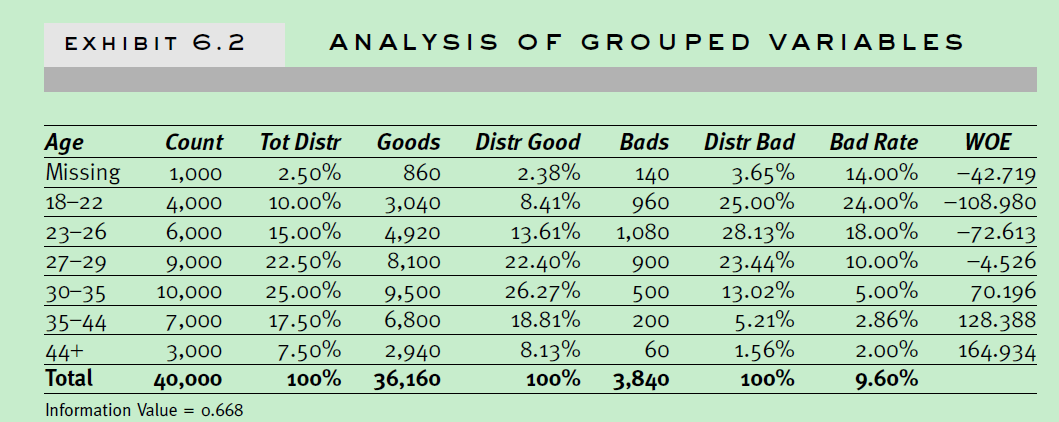
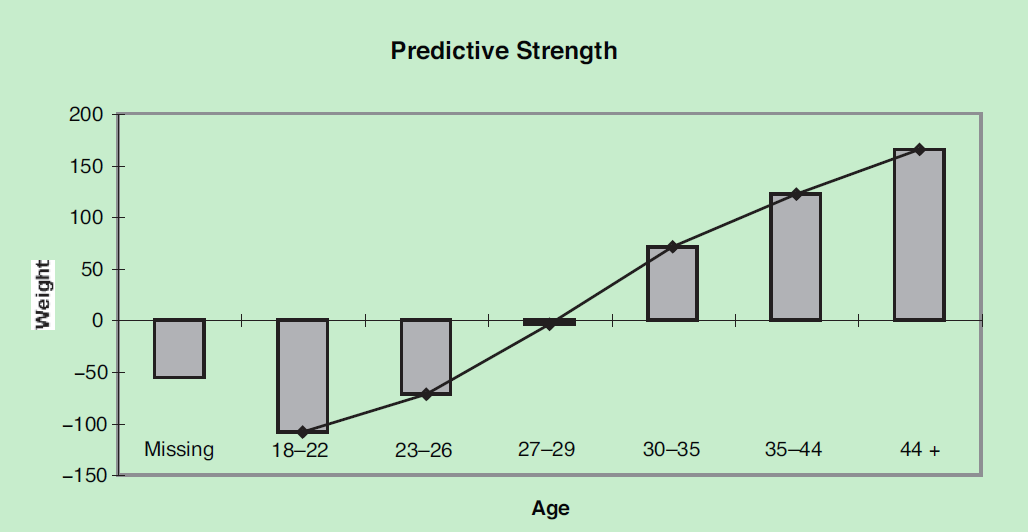
趋势分析 (分组变量各个属性的woe分布曲线):一般要求woe分布呈线性序,如果出现非线性序,需要考虑一些业务因素看是否合理。
Preliminary Scorecard
上面提到了样本处理,特征分析,下面提到模型学习,包括特征选择。
特征选择常用的方法: 前向选择(forward selection),后向消除(backward elimination),前后向算法(stepwise)
Reject Inference

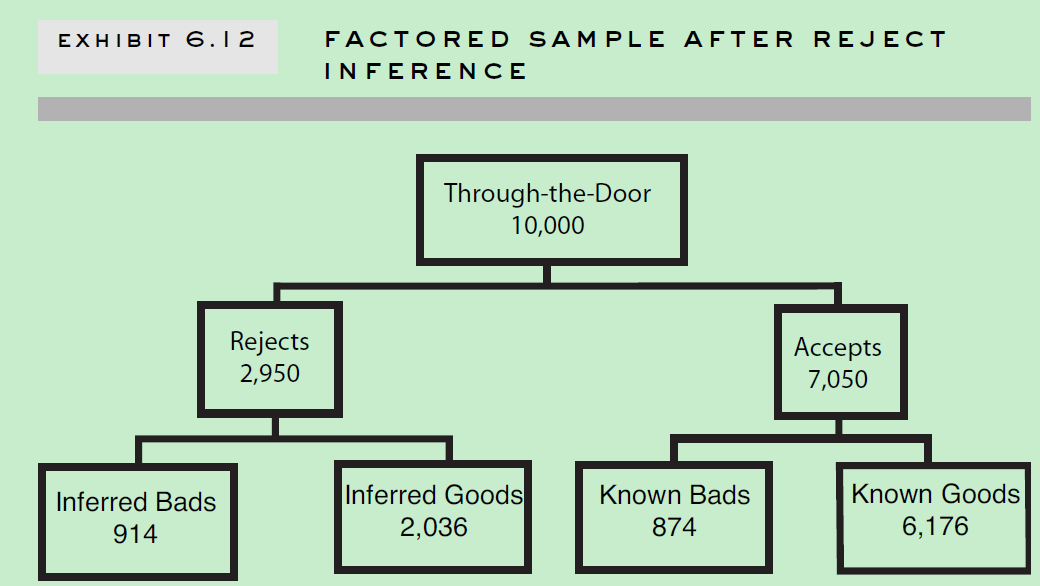 Reasons for Reject Inference
Reasons for Reject Inference
为何要做拒绝推断? 因为那些被拒绝的的账户样本,也有可能有好的样本以及坏的样本。如果我们只拿申请通过的样本做评分卡模型,那将会产生sample bias,不能很好的应用于整个申请人群。同时,拒绝推断也了为了方便评分卡模型覆盖之前决策影响。比如10000个申请样本中,有1000个是有严重不良行为的,如果拒绝了这1000个样本中940个,接受了60个,最后这60个样本最后大多数都是好样本的话。如果我不采用拒绝推断技术,只采用已知的好坏样本建立模型,你就会发现一种现象:有严重不良行为的反而是好的信用评分。拒绝推断技术可以中和这种影响。
一般拒绝部分的不良行为率是用比申请通过后的样本不良率要高的,这也是衡量拒绝推断技术有效性一个重要指标。
Reject Inference Techniques
1. Assign All Rejects to Bads: 所有拒绝的的都划归到坏的类别。这种方法一般是不满足需要的,因为拒绝部分有相当一定比率是好的。不过,如果申请通过率很高情况,该方法也可以。
2. Assign Rejects in the Same Proportion of Goods to Bads as Reflected in the Acceptees:根据已知申请通过后的样本好坏比率确定拒绝样本好坏比率(保持好一致)。这种方法,以为到目前为止,决策系统都是随机的。所以,这种方法有一定问题。
3. Ignore the Rejects Altogether: 忽略拒绝部分,这种一般也有问题。
4. Approve All Applications: 所有申请的都通过。这种是最真实的样本分布,不过这种方法也是高代价的,俗称“花钱买数据”。实际上也很难操作。
5. Similar In-House or Bureau Data Based Method: 借鉴外部数据或其他其他产品数据来推断。比如,一个卡商拒绝一个人申请,但是这个人在其他卡商通过了,那这样的数据是可以借鉴的。缺点:数据获得难度大,还有时间节点相似保证。
6.Simple Augmentation:
(1) 根据通过后的已有好坏样本(known good/bad)建立模型;
(2) 根据(1)模型对拒绝样本进行打分,计算p(bad) ;
(3) 设定期望坏样本率阈值,高于这个阈值的账户设为坏样本,低于的则设为好样本。
(4) 在已有好坏样本基础上增加推断的好坏样本,重新训练模型;
缺点: (1) 拒绝样本分类成好坏类别相对随机;(2) 拒绝样本加入已知类别的接受样本,是按照1:1 比率,不合理。
7.Augmentation 2:
(1) 根据接受/拒绝 样本建立接受/拒绝模型,每个样本会有个概率p(approval);
(2) 根据已有的好坏样本建立模型,但是样本权重需要调整,样本权重weight=1/p(approval);
下面是一个决策时模型示意图:
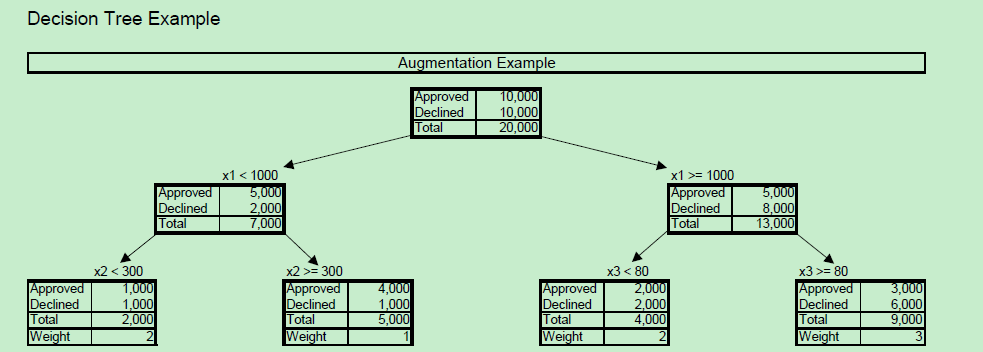
缺点(1)“cherry picked”问题 ;(2)由于建的接受/拒绝模型本身,因为我们一般追求模型准确率越高越好,但是这样会引发一个问题。就那决策树模型情况来说,极端情况下会出现叶子节点通过样本比率100%或者0%,对于0% 这种情况,就会有weight=1/0 情况。这时候应用其实做些平滑,如拉普拉斯平滑等。
8. Parceling:
(1) 根据已知好坏样本,建立模型;
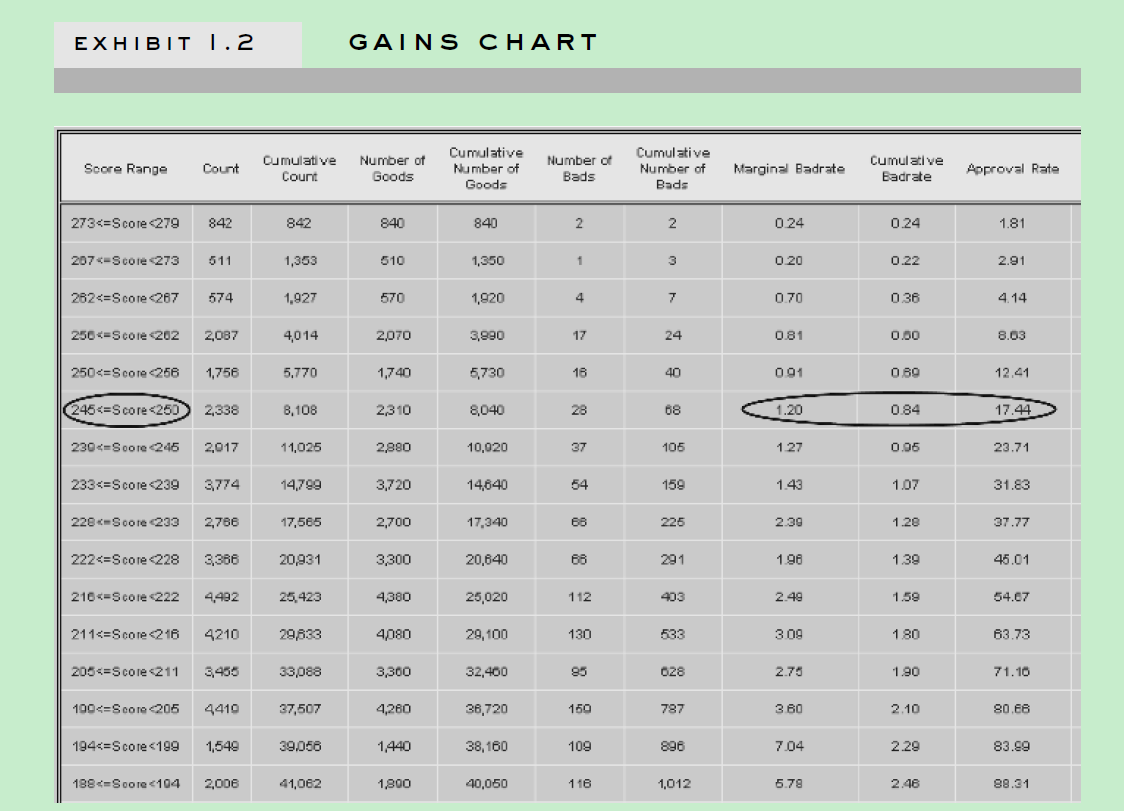
(2) 对所有样本进行打分,建立如下表。下面第2,3,4,5列是已知好坏样本以及分布。把所有拒绝样本划分到各个分数段上,根据这个分数段已知好坏样本比率,随机把拒绝样本划分类别。
比如0-169这个分数段,坏样本比率是23%,那就这个分数段的拒绝样本随机23%样本划分为“bad”,剩下为“good”。
缺点: 这个方法有个假设条件与真实情况是不符的。一般拒绝样本坏样本率是高于接收样本的。所以真实应用该方法时候,可以进行调整,比如设置拒绝样本坏样本率是同分数段接受样本的2-4倍等。

9. Fuzzy Augmentation:
(1)根据已知好坏样本,建立模型;
(2) 对每个拒绝样本进行打分;
(3)对每个拒绝样本计算p(bad), p(good)。 其实就是把每条拒绝样本变成两条,不同类别,不同权重。一条好的类别,权重为p(good), 一条为坏的类别,权重为p(bad)。
(4)组合(3) 变换后的拒绝样本和之前已知好坏样本(已知好坏样本,类别不变,权重设为1),建立模型。这里其实还应该继续调整下,如样本权重再需要经过申请通过率p(approval)来调整。这里对拒绝样本不仅仅考虑他的坏样本率还同时考虑他第一步申请通过率。
10. Iterative Reclassification:
(1)根据已知好坏样本,建立模型;
(2) 根据(1)模型,对拒绝样本进行打分,根据p(bad) 设定拒绝样本label;
(3) 结合拒绝样本label和已知样本label,重新训练模型。再根据模型对拒绝样本进行分类。
(4)迭代训练,直到模型参数收敛。可以看log(odds)曲线分布如下,每次迭代线都应该在KGB 线下面,这样意味着组合后的样本坏样本率有提高。

11. Nearest Neighbor (Clustering): 聚类的方法,已知的好坏样本各位一个类,对拒绝样本进行近邻查找,归到最近的类。根据近邻查找得到类别拒绝样本和已知类别的样本进行训练模型。
Verification
一旦拒绝推断技术被应用了,我们如何去检验效果? (1)比较拒绝推断样本坏样本率和已知样本坏样本率,一般拒绝推断样本坏样本率是已知样本2-4倍; (2)观看分组特征在推断前和推断后样本中woe和坏样本率分布差异。看哪个更和业务经验相符; (3) 构造假的拒绝样本。把已知好坏样本按照一定比率随机划分为接受/拒绝样本。用这份样本进行拒绝推断。因为这个时候拒绝样本类别是已知的,这样可以一些评估指标如误分类等来评估。
Final Scorecard Production
常见的评分卡格式如下, 如何把之前建立的二类分模型转换成评分卡格式?
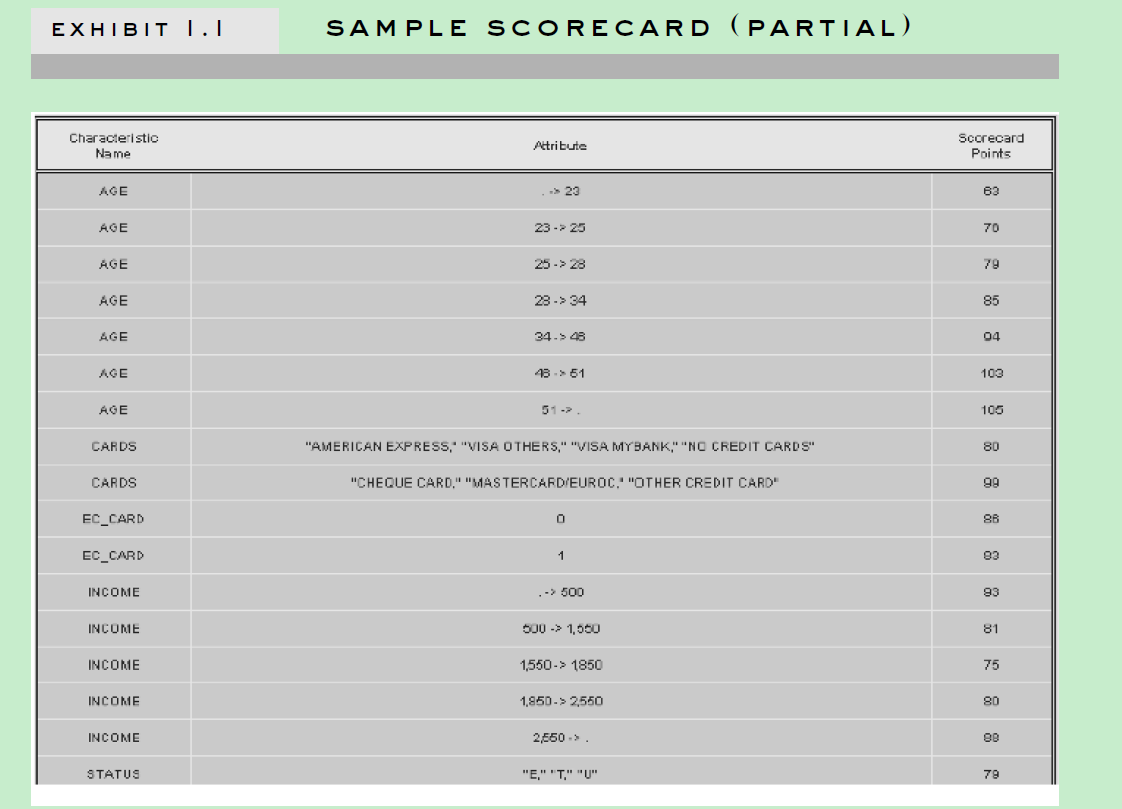
Scaling Calculation
进行二分类模型和评分卡的转换。假设ln(odds) 和评分呈现线性关系,如下图。
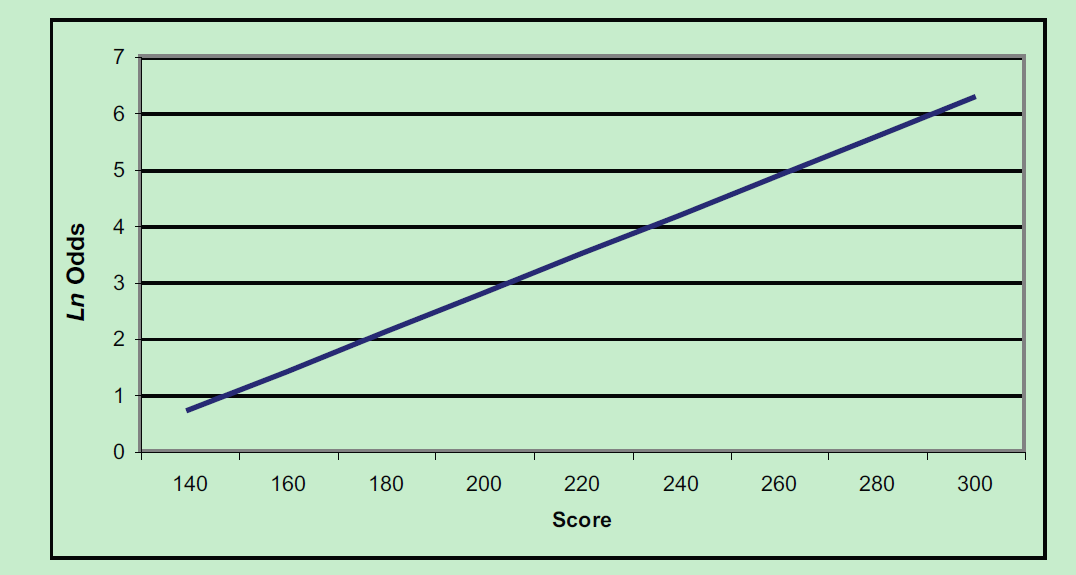
建立下面评分和ln(odds) 对应线性公式如下:
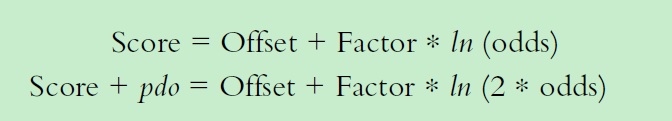
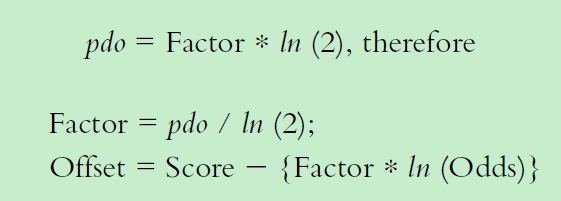 假设odds=50 时候,对应评分是600分,odds翻倍时候,评分增加20分,则:
假设odds=50 时候,对应评分是600分,odds翻倍时候,评分增加20分,则:
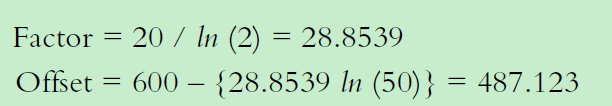

下面可以把最终评分分解到各个特征属性上(建立模型时候,用特征各个属性woe值去替换原始特征作为输入)。最后其实算一个人最终评分,就是他各个特征属性评分的加和。


Adverse Codes(逆转码)
当一个人申请被拒时候,需要告知他为什么被拒绝,也就是通常所说的模型解释。
首先提一下中立分概念, 中立分公式如下:

当一个人特征属性得分低于这个中立分,则会增加他被拒绝的可能性。
至于一个人的特征属性得分计算如下: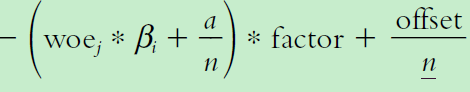
下图是一个人拒绝的原因展示,他有4项特征低于31分。

Points Allocation
一旦评分卡已经建立了,那么每个特征的每个属性的评分分配,以及评分卡的预测能力就需要进行观察验证下。下图是“Age” 各个属性woe值,评分卡1,评分卡2分值分布。
总的来说,特征各个属性个评分点应该是有序的。下图中评分卡1表现较好,遵守有序分布,年龄越大,评分越高;而评分卡2却出现了反转。
造成评分卡2 这种情况,原因是:特征间相关性,数据有历史变更, 或者分组之间预测差异性不显著。
如果特征各个属性woe值呈现有序分布,那建立模型时候,用特征各个属性woe值去替换原始特征,那最终特征各个属性评分分配分布则不会出现评分卡2那样的反转情况。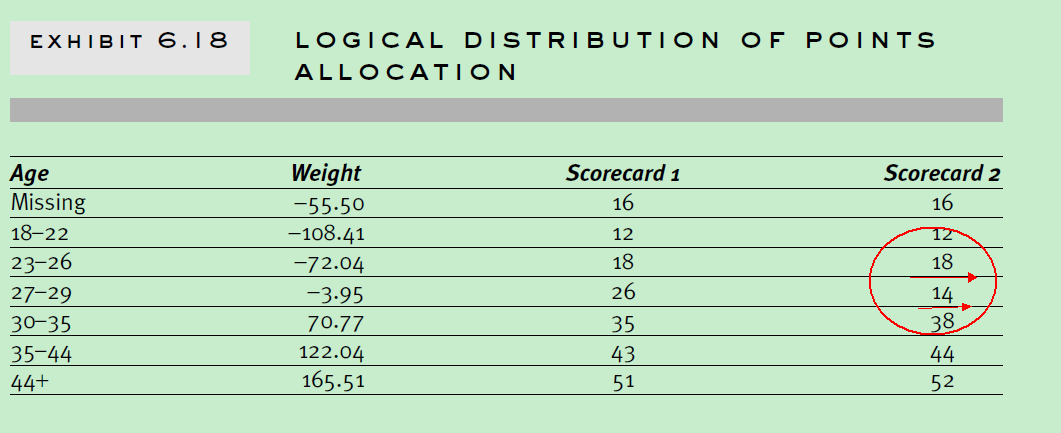 Choosing a Scorecard
Choosing a Scorecard
上面基本介绍了评分卡建立的流程和细节,那最好如何选择一个评分卡模型? 多个评分卡模型谁优谁劣?
Misclassification(误分类): 最直接和常见的方法,就是看预测分类准确与否,可以统计预测准确率。各个label的preision和recall,混淆矩阵等。
 混淆矩阵:
混淆矩阵: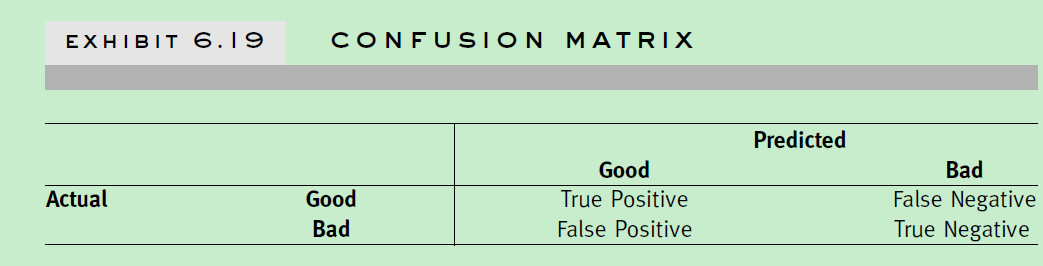
 Scorecard Strength
Scorecard Strength
统计模型预测有效性统计指标,常见的有统计模型复杂性的AIC, BIC(越小越好)指标,还有KS值(好坏累计分布曲线最大间隔值),ROC 曲线(AUC值),Lift值等。
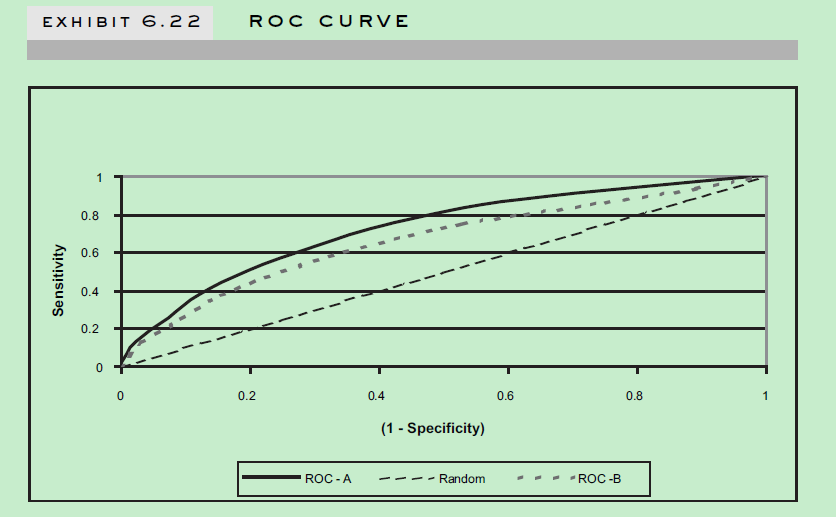
validation
之前提到我们做交叉验证,跨时间检验来验证模型预测有效性。这里面就需要统计训练集和测试集分布一致性问题。如何衡量一致性?
常见的指标如下:
(1) 直接看训练集,测试集,好坏样本分布曲线是否一致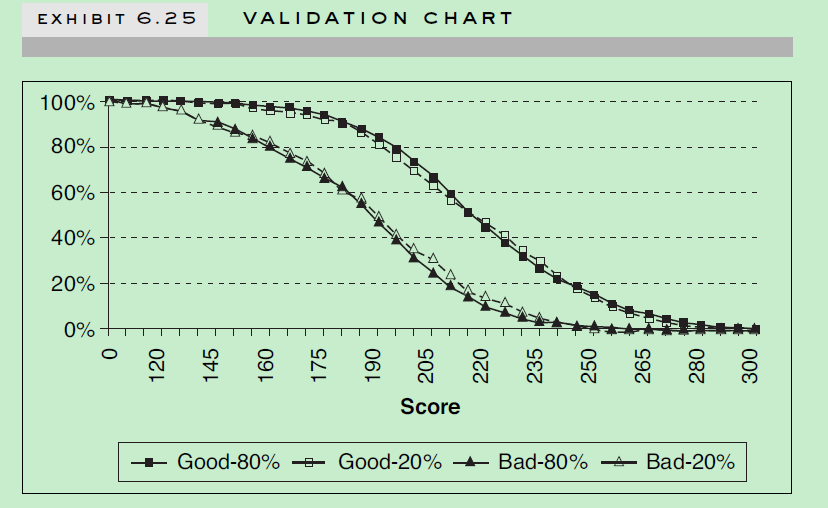 (2) 直接比较训练集合测试集Divergence值差异,Divergence定义如下,其中涉及好坏样本分布均值和方差。
(2) 直接比较训练集合测试集Divergence值差异,Divergence定义如下,其中涉及好坏样本分布均值和方差。 (3) 直接比较训练集和测试集各个统计指标值差异
(3) 直接比较训练集和测试集各个统计指标值差异
(2) 直接比较训练集合测试集Divergence值差异,Divergence定义如下,其中涉及好坏样本分布均值和方差。(3) 直接比较训练集和测试集各个统计指标值差异
时间:2018-09-21 13:06 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
最新文章

热门文章














