用自己的数据构建一个简单的卷积神经网络
在本文中,我们将构建一个卷积神经网络,将对7种类型的数千个图像进行训练,即:鲜花,汽车,猫,马,人,自行车,狗,然后能够预测是否给定的图像是猫,狗或人。

该CNN实现使用自己的图像数据集涵盖以下主题
- 加载和预处理自己的数据集
- 在Keras设计和训练CNN模型
- 绘制损失和准确度曲线
- 评估模型和预测测试图像的输出类
- 可视化CNN的中间层输出
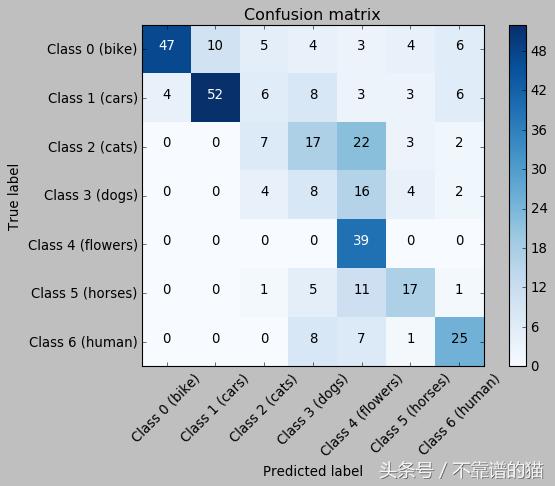
- 绘制结果的混淆矩阵
加载和预处理自己的数据集:
我们将使用的数据集包括从互联网收集并标记的7个类。Python代码如下;
- PATH = os.getcwd()
- #Define data path
- data_path = PATH + '/data'
- data_dir_list = os.listdir(data_path)
- data_dir_list
输出:
- ['bike', 'cars', 'cats', 'dogs', 'flowers', 'horses', 'human']
可视化一些图像,我们可以看到图像是128x128像素,Python代码如下:
- #Visualize some images
- image = X_train[1441,:].reshape((128,128))
- plt.imshow(image)
- plt.show()
用自己的数据构建一个简单的卷积神经网络
接下来,我们开始在Keras中设计和编译CNN模型,Python实现如下:
- #Initializing the input shape
- input_shape = img_data[0].shape
- #Design CNN sequential model
- model = Sequential ([
- Convolution2D(32,3,3, border_mode = 'same', activation = 'relu', input_shape = input_shape),
- Convolution2D(32,3,3, activation = 'relu'),
- MaxPooling2D(pool_size = (2,2)),
- Dropout(0.5),
- Convolution2D(64,3,3, activation = 'relu'),
- MaxPooling2D(pool_size = (2,2)),
- Dropout(0.5),
- Flatten(),
- Dense(64, activation = 'relu'),
- Dropout(0.5),
- Dense(num_classes, activation = 'softmax')
- ])
- #Compiling the model
- model.compile(
- loss = 'categorical_crossentropy',
- optimizer = 'adadelta',
- metrics = ['accuracy'])
在拟合模型之后,我们可以在整个迭代过程中可视化训练和验证。
- ist = model.fit (X_train, y_train,
- batch_size = 16,
- nb_epoch = num_epoch,
- verbose=1,
- validation_data = (X_test, y_test)
- )
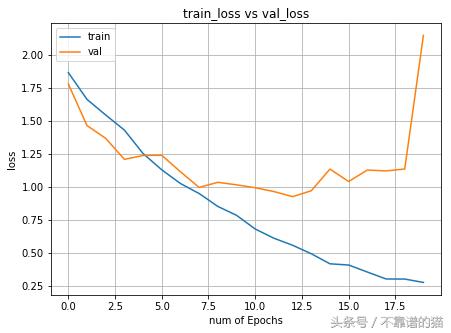
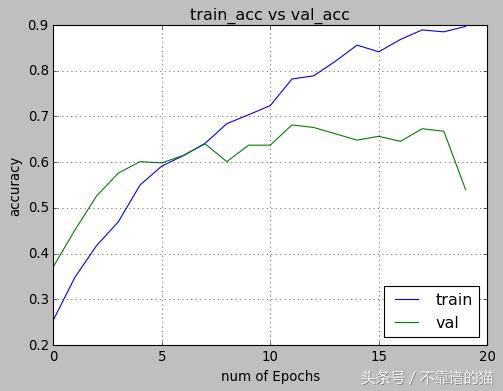
我们现在可以使用我们的模型使用以下代码预测新图像的新类:
- # Predicting the test image
- print((model.predict(test_image)))
- print('Image class:', model.predict_classes(test_image))
正如我们在下面看到的,我们的模型正确地将图像分类为class [0] - bike。
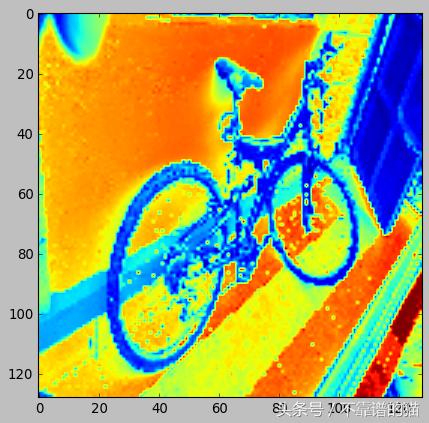
- [[3.6560327e-01 2.7960737e-06 1.2630007e-03 2.9311934e-01 1.6894026e-02
- 3.0998811e-01 1.3129448e-02]]
- Image class: [0]
这是一个混淆矩阵,没有归一化
我们现在可以保存模型和权重,以便在实际应用程序中实现。

时间:2018-09-19 00:06 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
最新文章

热门文章














