Facebook人工智能实验室提出「全景分割」,实现实

现如今,我们提出并研究了一种新的“全景分割”(Panoramic segmentation,PS)任务。可以这样说,全景分割将传统意义上相互独立的实例分割(检测和分割每个目标实例)和语义分割(为每个像素分配一个类标签)任务统一起来了。这种统一是自然的,并在一种孤立的研究状态中呈现出一种既不存在于实例中,也不存在于语义分割中的全新的挑战。为了衡量任务执行的性能表现,我们引入了一种全景质量(panoptic quality ,PQ)度量标准,并表明它非常简单且具有可解释性。在使用PQ的情况下,我们在三个现有数据集上研究了人类性能表现,其中,这些数据集要有必要的PS注释,这将有助于我们对任务和度量标准进行更好的理解。我们还提出了一种基本的算法方法,将实例和语义分割的输出结合到全景输出中,并将其与人类的性能表现进行比较。可以这样说,在分割和视觉识别方面,PS可以作为其未来挑战的基础。我们的目标是通过邀请社区探索所提出的全景分割任务从而推动在全新方向的研究。
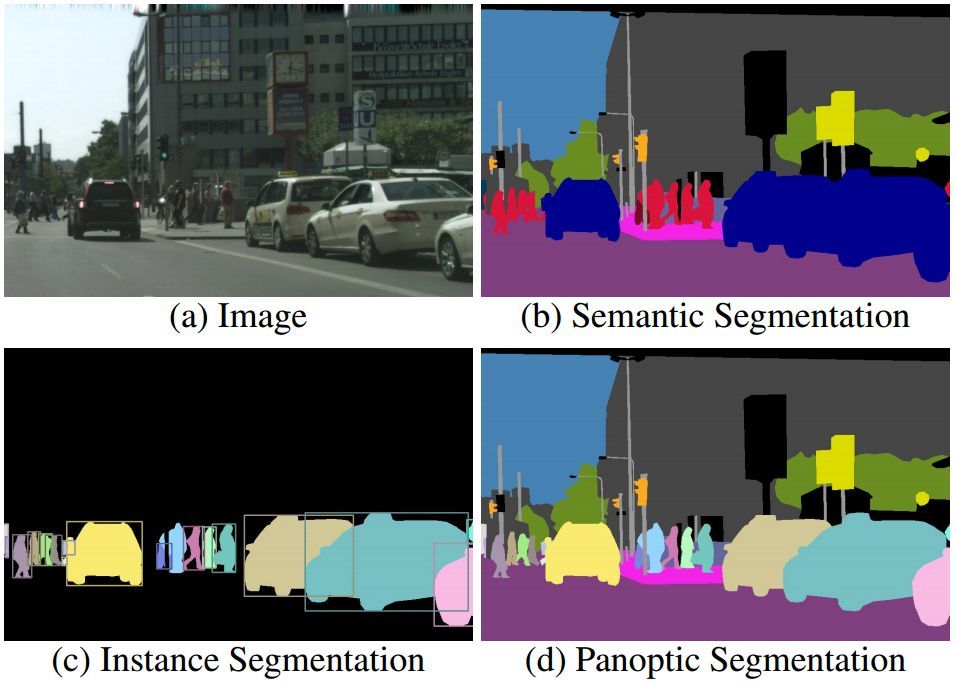
对于给定的(a)图像,我们展示了以下任务的参照标准:(b)语义分割(每个像素具有类标签),(c)实例分割(每个目标具有掩码和类标签),以及(d)提出的全景分割(PS)任务(每个像素具有类+实例标签)。全景分割泛化了语义和实例分割,并要求识别和描绘图像中的每个可见的目标和区域。我们希望这个统一的分割任务能够提出新的挑战,并创造新的方法。
在计算机视觉发展的早期,things(事物)——诸如人、动物、工具等可以计数的物体,得到了占据主导地位的关注。在质疑这种趋势是否存在智慧性时,Adelson提高了研究系统的重要性,而这种系统能够识别出stuff(材料)——诸如草、天空、道路等类似质地或原料的非晶区域。事物和材料之间的这种二分法一直沿用至今,既反映在视觉识别任务的划分上,也体现在针对事物和材料任务开发的专用算法中。
学习材料的任务通常被看作是一项称之为语义分割的任务,见图1b。由于材料是无定形的、不可数的,这个任务被定义为简单地为图像中的每个像素分配一个类别标签(注意,语义分割将事物类别视为材料)。相比之下,研究事物的任务通常被表述为目标检测或实例分割任务,其目的是检测出每个目标,并用边界框或分割掩码对其进行描述,参见图1c。虽然这两个视觉识别任务看似相关,但是在数据集、细节和度量标准上有很大的不同。

分割瑕疵。图像被缩放和裁剪。顶部行(Vistas图像):两个注释器都将目标识别为一辆汽车,然而,人将一辆汽车分成了两辆车。底行(Cityscapes图像):分割是非常模糊的。
语义和实例分割之间的分裂导致了这些任务方法中出现了平行分裂。材料分类器通常建立在具有扩张的完全卷积网络上,而目标检测器通常使用的是目标提案(object proposals),且是基于区域的。在过去的十年中,这些任务的总体算法进展是不可思议的,然而,如果将这些任务孤立起来看,就可能会忽略一些重要的内容。
在这项研究中,我们会问:things和stuff之间是否可以和解?是否存在这样一个简单的问题表述,能够优雅地将这两个任务涵盖在内?一个统一的视觉识别系统会是什么样子的呢?

分类瑕疵。图像被缩放和裁剪。顶部行(ADE20k图片):简单的错误分类。底行(Cityscapes图像):现场是非常困难进行分类的的,有轨电车是正确的分类。其中许多错误难以解决。
考虑到这些问题,我们提出一个既包含things又包含stuff的新任务。我们将所得到的任务称为全景分割(PS)。全景的定义是“一个视图中可见的一切”,在我们的上下文中,全景视图指的是分割的统一的全局视图。PS的任务表达看似简单:图像的每个像素都必须分配一个语义标签和一个实例ID。具有相同标签和ID的像素属于同一个目标,而对于材料标签而言,实例ID被忽略。参照标准和机器预测都必须有这种形式。见图1d的可视化。
全景分割是语义分割和实例分割的泛化,但引入了新的算法挑战。与语义分割不同,全景分割需要区分单个目标实例; 这对完全卷积网络提出了挑战。与实例分割不同的是,在全景分割中目标分割中必须是非重叠的,这对独立于操作每个目标的基于区域的方法提出了挑战。 而且,这项任务需要同时识别出things和stuff。为全景分割设计一个干净的、端到端的系统是一个开放的问题,需要探索创新的算法思想。

Cityscapes(左二)和ADE20k(右三)的全景分割结果。预测是基于最先进的实例和语义分割算法的合并输出进行的。匹配部分的颜色(IoU> 0.5)(交叉阴影图案表示不匹配的区域,黑色表示未标记的区域)。最呈现的是最好的颜色和变焦。
我们新的全景分割任务需要一个新的度量标准。我们努力使我们的度量标准完整、可解释、简单。或许,令人惊讶的是,对于我们这看起来复杂的任务,存在一个满足这些性质的自然度量标准。我们定义了全景质量(PQ)度量标准,并且表明了它可以被分解为两个可解释的术语:分割质量(SQ)和检测质量(DQ),而且还可以进一步细分精度。
由于全景分割的参照标准(ground truth)和算法输出都必须采用相同的形式,因此我们可以在全景分割上对人类性能(human performance)进行详细的研究。这使我们能够更详细的了解全景质量度量标准,包括检测与分割的详细分析,以及材料与事物(stuff 和things)的性能对比。并且,测量人体PQ有助于我们理解机器的性能。这点非常重要,因为它可以让我们监测全景分割中各种数据集上的性能饱和度。
最后,我们对全景分割的机器性能进行初步研究。为此,我们确定了一个简单但可能不是最优的启发式算法,该算法通过一系列后处理步骤(post-processing steps)(实际上是一种非最大抑制的复杂形式)将两个独立系统的输出结合起来进行语义和实例分割。我们的启发式算法为全景分割建立了一个基线,并为我们提供了有关它所呈现出的主要算法挑战(main algorithmic challenges)的见解。
我们在三个通用分割数据集上研究了人和机器的性能,这三个数据集都包含材料与事物(stuff 和 things)注释。这些数据集分别是Cityscapes、ADE20k和Mapillary Vistas。对于每个数据集,我们都直接从挑战组织者那里获得了最先进方法的结果。在未来,我们将把分析工作扩展到COCO(在COCO中材料(stuff)被注释)上。我们将这些数据集合在一起,为研究人类和机器在全景分割上的表现奠定了坚实的基础。
我们的目标是通过邀请社区以探索新的全景分割任务从而推动新方向的研究。我们认为,拟定的任务会导致预期之内和预期之外的创新。最后,我们来探讨一下这些可能性以及我们未来的计划。
出于简单化的目的,本文中提出的PS“算法”是基于最优执行实例和语义分割系统中输出的启发式组合。这个方法是基本性的第一步,但我们希望引入更多有趣的算法。具体而言,我们希望看到全景分割至少在两个方面的创新:(1)深度集成的端到端模型可同时解决全景分割的双重性质。许多实例分割方法都被设计为用于产生不重叠的实例预测,并可以作为此系统的基础。(2)由于全景分割不能有重叠的部分,因此某种形式的高层次“推理”可能是有益的,例如,将基于可学习的NMS扩展到全景分割中。我们希望全景分割任务能够推动这些领域的研究,进而带来令人眼前一亮的新突破。

时间:2018-09-17 15:36 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
- [机器学习]来自Facebook AI的多任务多模态的统一Transformer:向
- [机器学习]更深、更轻量级的Transformer!Facebook提出:DeLigh
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
- [机器学习]来自Facebook AI的多任务多模态的统一Transformer:向
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]更深、更轻量级的Transformer!Facebook提出:DeLigh
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
相关推荐:
网友评论:















