推荐效果线上评测:AB 测试平台的设计与实现【
第一篇
1、背景
在推荐系统中,评测效果,除了离线的 AUC,更合理的方法是通过线上真实的 AB 测试,来比较策略的效果。
AB 测试来自医学的双盲实验,在双盲测试中:
- 病人随机被分成两组,在不知情的情况下,分别服用安慰剂跟测试用药
- 经过一段时间后,再来比较两组病人的表现是否有显著差异。
从而决定药物是否真的有用。
互联网行业的 AB 测试类似,对于一个策略 /UI,在同一个时间维度,保证其他体验一致的情况下,分析实验组跟对照组的区别,以便做决策判断。
因为经常接触 AB 测试,以及看到了国内一些公司的 AB 平台不同的设计实现方法,整理一下 AB 测试平台相关知识。
2、具体说明
本文从以下方面讨论。
- 2.1 单层实验:方法以及问题
- 2.2 多层重叠实验架构:一切从 google 的论文说起
- 2.3 国内公司的解决方案文章分享
2.1 单层实验
2.1.1 方法
顾名思义,单层实验的模式是:
- 把所有的用户放在一起,有相互独立的用户标识(比如 cid,uid,cookis 等)
- 以某种分流的方法(比如随机),给每个实验组,分配一定的用户。
- 每个实验分到的用户正交
2.1.2 问题
单层实验一定程度说是可行的,但是会遇到一定的问题
- 扩展性差,只能同时支持少量实验。但是以数据驱动的业务,需要极快的创新速度,大量的创新需要被测试,会严重 delay 业务。
- 如果在单层同时进行多个实验,实验之间不是独立事件,并行的时候,同一个策略,只能进行一个实验,如果多个并行支持,无法实现。不同策略之间也有影响。
- 流量饥饿问题:假设我们整体用户要做 5 个实验,如果前 2 个实验占据了大部分的流量,后面的 3 个实验就有很少的流量可以供使用,甚至没有流量可用。
- 流量偏置问题:假设上游的实验把所有的年轻人都获取了,下游的实验,没有年轻人的样本。导致有偏差。
2.2 多层重叠实验架构:一切从 google 的论文说起
Google 在 2010 年的 KDD 上公布了自己的分层实验框架,之后,国内的大部分的 AB 测试平台,都是基于此论文建设。首先分享一下这篇论文的英文版以及中文翻译版
- 中文版:https://www.csdn.net/article/2015-01-09/2823499
- 英文版:https://research.google.com/pubs/pub36500.html
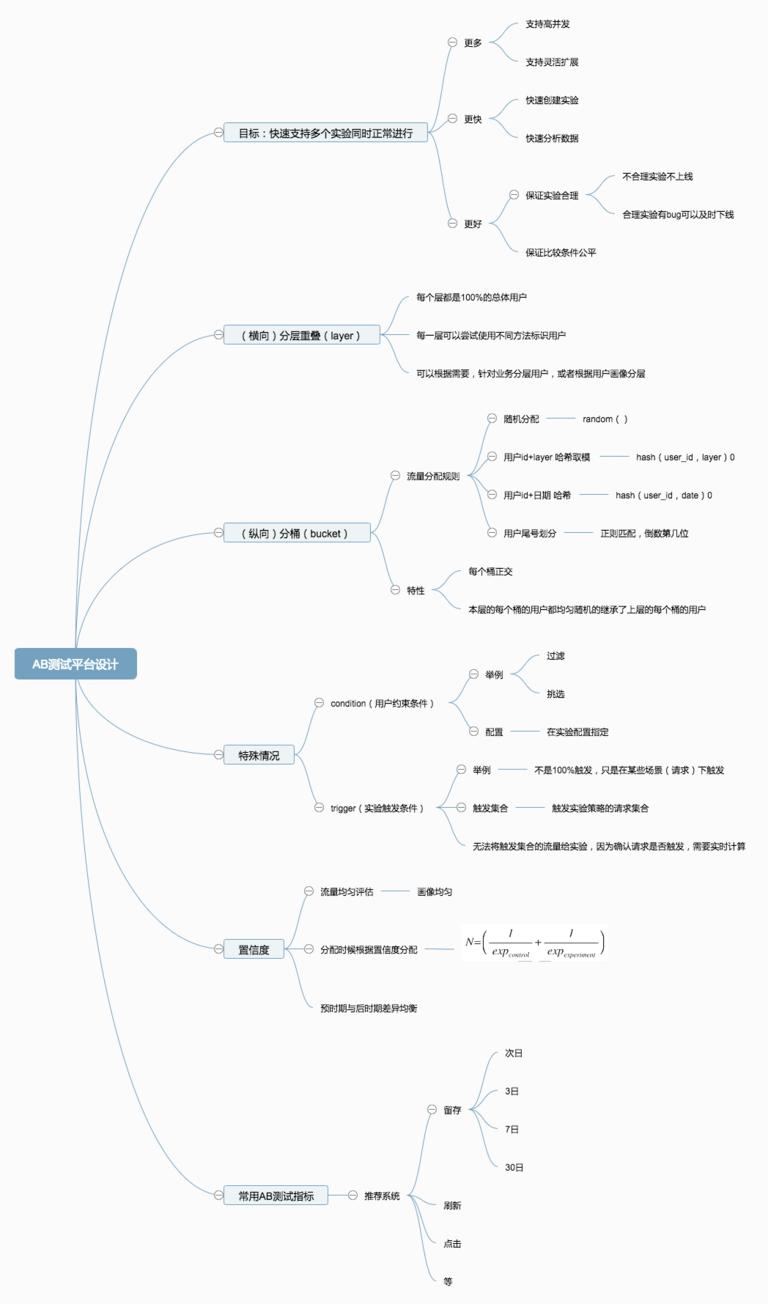
2.2.1 设计实验平台的目标
- 更多:多个实验可以并行扩展,而且能够保证灵活性
- 更好:保证实验合理,不合理实验不能上,合理实验出 bug 能及时止损,保证每个实验有公平合理的比较
- 更快:能够快速创建实验,而且能够快速提供结果分析
2.2.2 手段
思考:保留单层实验框架易用,快速的优点的同时,增加可扩展性,灵活性,健壮性。
核心思路:将参数划分到 N 个子集,每个子集都关联一个实验层,每个请求会被 N 个实验处理(每层一个实验),每个实验都只能修改自己层相关联的参数(在参数子集中的参数),并且同一个参数不能出现在多个层中。
2.2.3 具体设计:分流模型
名词概念解释:
- 域(domain):划分的一部分流量
- 层(layer):系统参数的一个子集
- 实验(exp):在一个域上,对一个或者多个参数修改,改变请求路径的过程
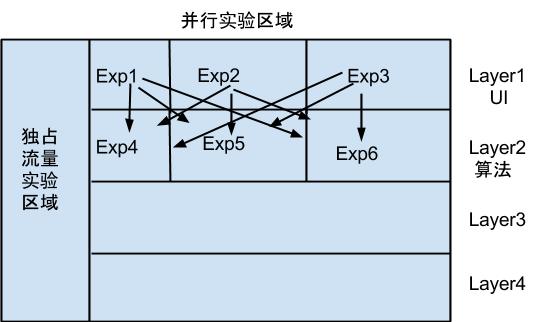
简单的理解,我们把流量在纵向上的划分叫做域(domain),流量请求从纵向判断先开始。然后我们把横向上的划分,称为层(layer),在同一个层,不同策略(exp)是隔离开的,一个策略(exp),可以被多个层控制,每个层都可以有多个实验。流量在每个层都会被重新打散。
流量在每个层被打散的方法,称之为 分配函数,google 在论文里提到了四种(因为是基于 PC 搜索,所以用户标识是 cookie)。支持多种流量分配类型的主要目的一方面是为了保持处理的一致性,另外也希望覆盖到所有的情况。
- user_id mods = f(user_id,layer)%100
- cookies mods= f(cookies,layer)%100
- cookie-day mods= f(cookie-day,layer)%100
- random=f(random)
这其中有两种特殊的情况:
- condition:用户样本有特殊要求,在通过分配函数分配到一部分流量后,部分实验可以通过 分流条件(condition)仅分配特定条件的流量给实验或域,以达到更高效利用流量的目的。典型的条件比如:国家(google 是全球的产品),语言,浏览器等。分配条件一般直接在实验或者域的配置中指定。
- trigger:实验触发条件有特殊要求,仅在某些请求下触发,而这种实时计算类的没有办法事先分配好,只能通过程序自己判断。这种情况下,重要的工作是记录事实(factual,当实验被触发)跟反事实(counter-factual,当实验可以被触发)。反事实在对比实验中记录。
下图是整个 AB 实验用户实验列表 Re 的判断流程
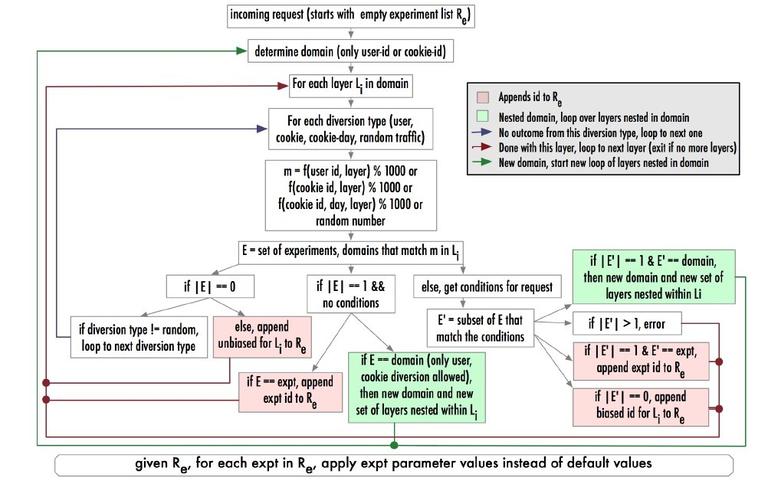
2.2.4 具体设计:具体实验流量分配
有了分流模型,流量分配函数,我们在做实验的时候,还需要注意,AB 平台能够很好的指导业务,准确的进行实验。
准确的进行实验,有几个关键事项:1)实验合理性 2)代码准确性 & 数据准确性 3)实验结果置信保证 4)实时监控。
1)实验合理性
google 的做法是,有一个实验委员会,每次实验的时候,实验者提供一个简单的 checklist,checklist 中需要保护以下的问题答案:
- 基本的实验特性:比如实验测试什么,它们的假设是什么
- 实验创建:要修改哪些参数,每个实验分别要测试什么,在哪一层
- 实验的流量分配跟触发条件:使用什么分配类型,什么分配条件,在多大比例的流量触发实验
- 实验分析:关注哪些指标,实验要检测的指标敏感度是什么
- 实验规模跟时间跨度:保证给定的流量,有足够统计量来保证指标敏感度
- 其他补充:比如是否需要预时期跟后时期来保证(预时期跟后时期的意思就是,在实验前或者后,观察实验组与对照组的天然差异)
2)代码准确性 & 数据准确性
一些基础的检查,比如 是否所有必填字段都填写了,对照组跟实验组是否流量一致大小,是否跟别的实验有冲突等
3)实验结果置信保证
这节很重要,个人感觉是分流模型外,论文里最重要的部分。首先,很多人分配流量都是凭借直觉,或者有多少就用多少。最后的数据结果不置信,反而对产品有负向伤害。简单的说,这种 “抽取样本来估计全局”的实验,需要保证”样本的结果能够代表全局”,即样本量应该让实验有足够的统计意义。
一个实验的有效规模,google 定义为:
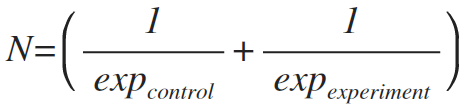
为了求 N,需要有几个先验的参数:
- ①实验所关注的指标是什么
- ②对于每个指标,想改变的敏感度 ,比如:想检测 2% 左右的波动
-
③针对每个指标,一个抽样单元(N=1) 样本标准误差为 s,则实验大小为 N 的标准误差为
如果实验组大小 = 对照组大小,比如实验组 =2N,那么 2N 必须大于等于才能满足最小变化检测需求。其中 16,是根据置信度(通常取 95%,),期望的统计功效(通常为 80%,)决定。
谷歌在每一层共享一个对照组,被多个实验共享。如果对照组比实验组大很多,系数就可以用 10.5,而不是 16.(不用取 2N,取 N)
真实实验中,不同指标,不同分配方法有不同的 s,google 提供了一个工具,可以让实验者权衡流量大小与敏感度。为了保证置信区间的正确性,一直进行一组 同质测试,来检测指标的自然变化。
4)实时监控
google 有实时监控,检测某些指标超出正常值范围的波动。
2.2.5 具体设计:实验数据分析工具
- 正确的计算跟显示置信区间
- 很好的图形化界面
- 很好的理解数据,比如:辛普森悖论的观察跟理解
- 一致性有唯一的实现保证,比如 使用相同的 spam 过滤器
- 讨论会,专门的讨论解读数据
2.2.6 最后
最后总结的时候比较散,写的太长了,不想写了。
有一个比较想说的,就是 google 把历史的 ab 测试总结起来,做了一个知识库,这个挺好,有助于总结学习。
然后即使是 google,也经常有错误,比如日志经常不对。
2.3 国内公司的解决方案文章分享
大部分国内公司的解决方案,都是根据 google 的论文做的,但是在分层上,有根据业务划分的,有根据用户画像划分的(取决于实际的 AB 测试环境要求)。
这篇文章更多偏向 google 的理论解读,下一篇文章将基于国内目前有的公司的架构以及 goole 的理论,详细介绍一下 AB 测试平台的一种工程实现。
收集的一些国内公司的文章介绍如下:
- 大众点评:Gemini
- **微博广告:Faraday **
- 阿里的一个文章
- PPTV
最后,分享一个网站
- http://exp-platform.com/
第 2 篇
背景
本来想着所有的 AB 相关的都写在上一个博文,但是实在太长了那个,最近服务器不稳定,为了隔离开,特此开新的博客文章,专门写一个,如何开发一个 AB 测试平台。
上一篇其实更多的是理论基础,这一篇就偏向具体实战。
具体需求
1、整体框架 (点击看大图)
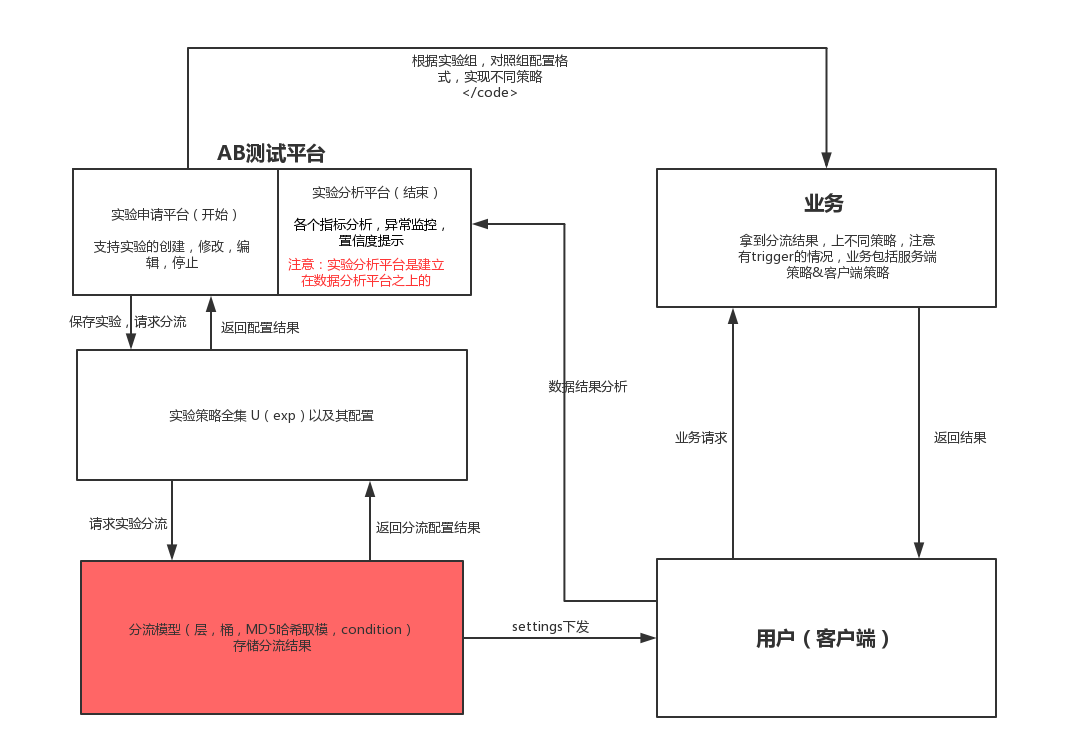
2、具体设计
原型见:**https://oy3z1e.axshare.com **,因为不是专业做这个,只是调研,所以实现都比较简单。
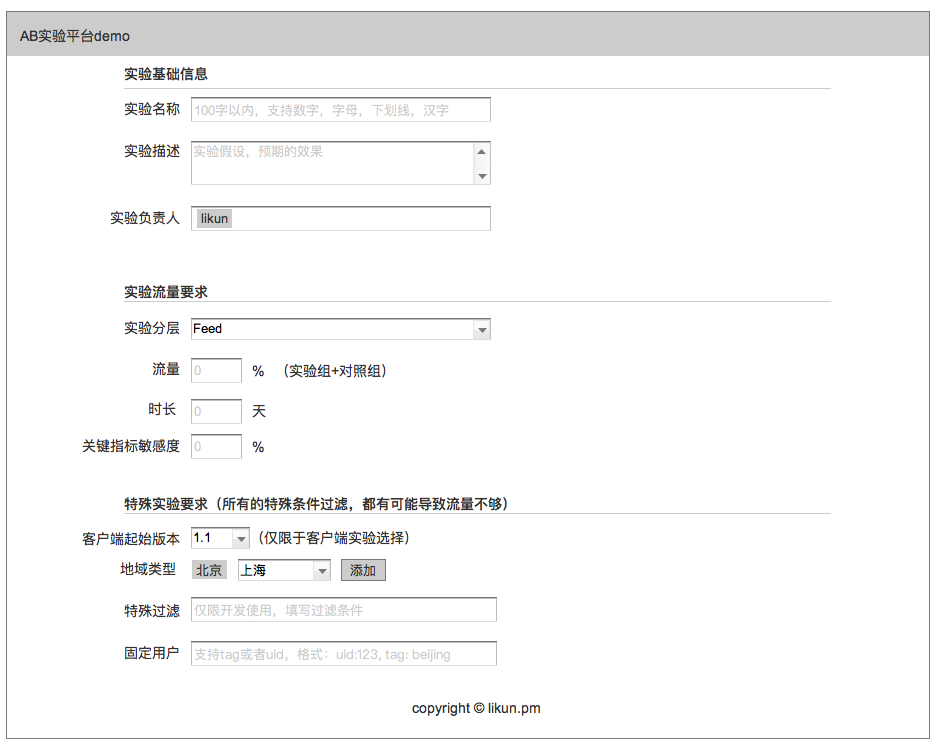
分流模型
剩下的两部分,业务跟用户部分,就不用写了,是业务方相关了。
3、补充说明
这篇文章写完,对 AB 测试的研究部分就算结束了,当然依然存在着一些疑问跟具体实践过程中的问题。有一些问题有了答案,有一些问题还没有。我会继续更新记录到这个文章里面。
一些感想:
目前国内很多的 AB 测试平台,主要有 4 个问题:
- 因为分流模型的原因,只能同时在线少量的实验
- 很多的实验分流有问题,导致数据结果不置信。
- 数据讨论不够,很多实验的增幅因果性不清晰
- 埋点!!!数据埋点大量的不对,这是非常重要的一个原因
头条的 AB 平台叫 libra,做的比较好。而且感觉在某些时候,比 google 的要好,比如:同一层并不使用同一个对照组,这样实验可以反转。头条的实验方法有一些也比较奇怪,比如又有预时期(记得叫空跑),有时候对照组跟实验组都分别开两个实验组。
好了,啰嗦到这里,下面整理问题,随时更新。
-
问题 1:不同的分流函数最后有什么差异
答案:按照谷歌的论文,差异就是测试出来,不同的分流方法,需要的流量大小不一样,才能得到同样的置信度。 -
问题 2:概率论里面的置信度,到底怎么算
答案:科普 https://wenku.baidu.com/view/a5698563783e0912a2162a42.html

时间:2018-09-16 22:42 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
- [机器学习]神经科学如何影响人工智能?看DeepMind在NeurIPS2
- [机器学习]美俄人工智能军事应用
- [机器学习]民调不靠谱?人工智能预测拜登获胜
- [机器学习]人工智能正在误导我们的广告,是时候纠正这些错误了
- [机器学习]美国陆军研究如何组建人-人工智能系统团队
- [机器学习]人工智能的下一个拐点:图神经网络迎来快速爆发期
相关推荐:
网友评论:















