场景分割是语义分割领域中重要且具有挑战的方向,其可以应用于自动驾驶,增强现实,图像编辑等领域。场景分割需要预测出图像中的像素点属于某一目标类或场景类,其图像场景的复杂多样(光照,视角,尺度,遮挡等)对于场景的理解和像素点的判别造成很大困难。当前主流场景分割方法大致可分为以下两种类型:一是通过使用多尺度特征融合的方式增强特别的表达,例如空间金字塔结构 (PSP,ASPP) 或者高层浅层特征融合 (RefineNet)。但是这些方式没有考虑到不同特征之间的关联依赖,而这对于场景的理解确实十分重要。另一是利用 RNN 网络构建特征长范围的特征关联,但这种关联往往受限于 RNN 的 long-term memorization。
本文提出了一种简单有效的双重注意力网络(Dual Attention Network, DANet),通过引入自注意力机制 (self-attention mechanism) 在特征的空间维度和通道维度分别抓取特征之间的全局依赖关系,增强特征的表达能力。该网络在 Cityscapes,PASCAL Context 和 COCO-Stuff 三个公开的场景分割数据集上均取得了当前最好性能,相比 Dilated FCN 性能得到 5 个点以上的显著提升。
论文:Dual Attention Network for Scene Segmentation

-
论文链接:https://arxiv.org/pdf/1809.02983.pdf
-
代码链接:https://github.com/junfu1115/DANet
摘要:在本文中,我们基于自注意力机制捕获丰富的语境关联来解决场景分割问题。与以往通过多尺度特征融合捕获语境的研究不同,我们提出了一种双重注意力网络(DANet)来自适应地将局部特征与其全局依赖关系相结合。具体来说,我们在传统的基于空洞卷积的 FCN 上添加了两种注意力模块,分别对空间维度和通道维度的语义相互关联进行建模。位置注意力模块通过所有位置的特征加权总和选择性地聚集每个位置的特征。无论距离远近,相似的特征都会相互关联。同时,通道注意力模块通过整合所有通道图中的相关特征,有选择地强调相互关联的通道图。我们将两个注意力模块的输出相加,以进一步改进特征表示,这有助于获得更精确的分割结果。我们在三个具有挑战性的场景分割数据集(Cityscapes、PASCAL Context 和 COCO Stuff)上取得了当前最佳分割性能。特别是,在不使用粗略数据的情况下,在 Cityscapes 测试集的平均 IoU 分数达到了 81.5 %。
方法
DANet 在特征的空间维度和通道维度分别引入自注意力机制,即位置注意力模块和通道注意力模块,有效抓取特征的全局依赖关系。系统框架图和两个模块的具体结构如下:
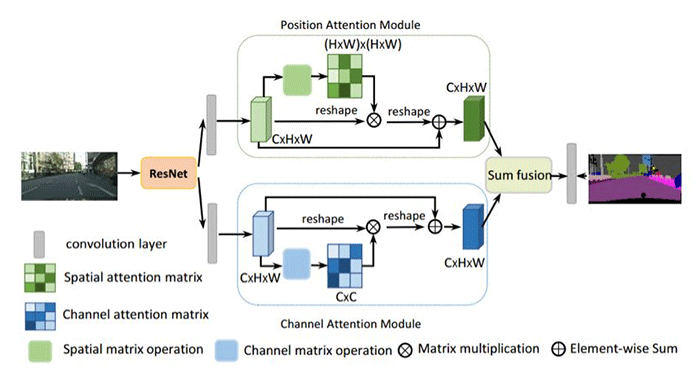
图 1. DANet 的网络框架图
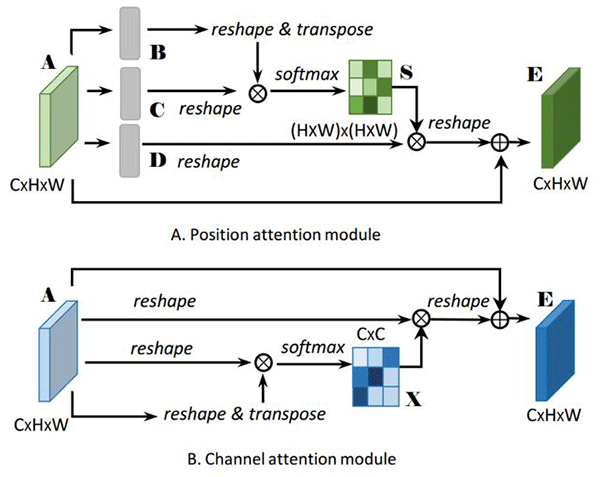
图 2. A 为位置注意力结构图, B 为通道注意力结构图
位置注意力模块旨在利用任意两点特征之间的关联,来相互增强各自特征的表达。具体来说,首先计算出任意两点特征之间关联强度矩阵,即原始特征 A 经过卷积降维获得特征 B 和特征 C,然后改变特征维度 B 为 ((HxW)xC') 和 C 为 (C'x(HxW)) 然后矩阵乘积获得任意两点特征之间的关联强度矩 ((HxW)x(HxW))。然后经过 softmax 操作归一化获得每个位置对其他位置的 attention 图 S, 其中越相似的两点特征之间,其响应值越大。接着将 attention 图中响应值作为加权对特征 D 进行加权融合,这样对于各个位置的点,其通过 attention 图在全局空间中的融合相似特征。
通道注意力模块旨在通过建模通道之间的关联,增强通道下特定语义响应能力。具体过程与位置注意力模块相似,不同的是在获得特征注意力图 X 时,是将任意两个通道特征进行维度变换和矩阵乘积,获得任意两个通道的关联强度,然后同样经过 softmax 操作获得的通道间的 attention 图。最后通过通道之间的 attention 图加权进行融合,使得各个通道之间能产生全局的关联,获得更强的语义响应的特征。
为了进一步获得全局依赖关系的特征,将两个模块的输出结果进行相加融合,获得最终的特征用于像素点的分类。
实验
为了评估提出的此方法,我们在 Cityscapes 数据集、PASCAL Context 数据集、COCO Stuff 数据集上做了综合实验。实验结果表示,DANet 在这些数据集上取得了顶级结果。
在 Cityscaps 数据集上的结果
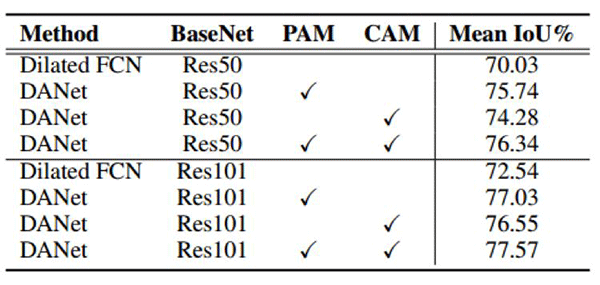
表 1:在 Cityscapes 验证集上的对比实验。PAM 表示位置注意力模块,CAM 表示通道注意力模块。

图 3:在 Cityscapes 验证集上仅使用和不使用位置注意力模块效果对比图。

图 4:在 Cityscapes 验证集上仅使用和不使用通道注意力模块的效果对比图。
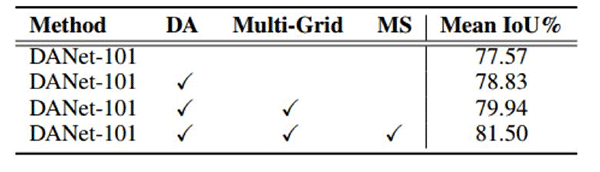
表 2:在 Cityscape 验证集上,不同策略之间的表现对比。DANet-101 表示 DANet 使用 BaseNet ResNet-101,DA 表示训练数据采用多尺度增强,Multi-Grid 表示使用多重网络方法,MS 表示测试时多尺度融合

图 5:注意力模块在 Cityscapes 验证集上的可视化结果。每一行包括一张输入图像,两个与输入图像中标记的点对应的子注意力图(H × W)。同时,我们也给出了来自通道注意力模块输出的两张通道图,分别来自第 4 和第 11 通道。最后,也给出了对应的结果和真实值。
可以看出位置注意力模块中,全局区域下相似语义特征之间响应较大,而通道注意力模块中,通道对某些语义区域有很强的响应。
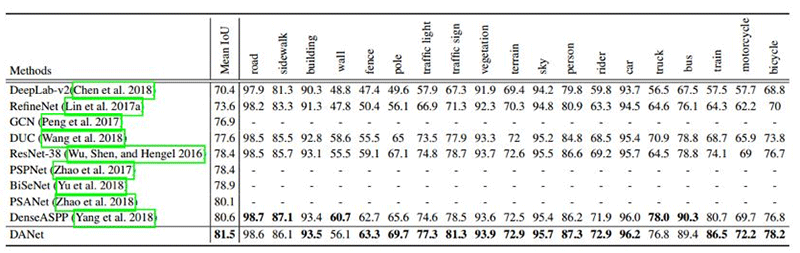
表 3:在 Cityscapes 测试集上每个类别的结果。DANet 超越了已有方法,平均 IoU 达到 81.5%。
本文与当前 state-of-the-art 进行了对比,在仅使用精细数据集(fine data)作为训练数据,resnet-101 作为基模型下,取得当前最好的分割性能。值得一提的是,目前并没有采用在线困难样本挖掘(OHEM, Focal Loss),更高分辨率的测试方法,更强大的基模型等策略,进一步的效果提升值得期待!
在 PASCAL Context 数据集上的结果
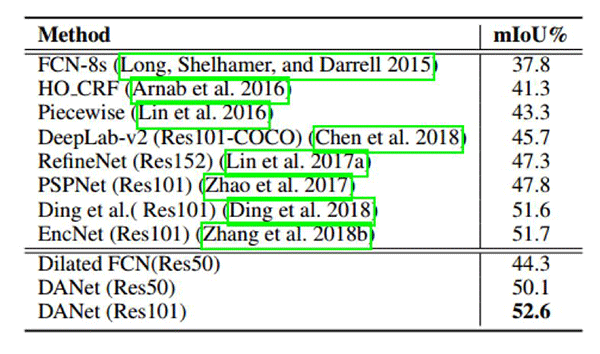
表 4:在 PASCAL Context 测试集上的分割结果
在 COCO Stuff 数据集上的结果
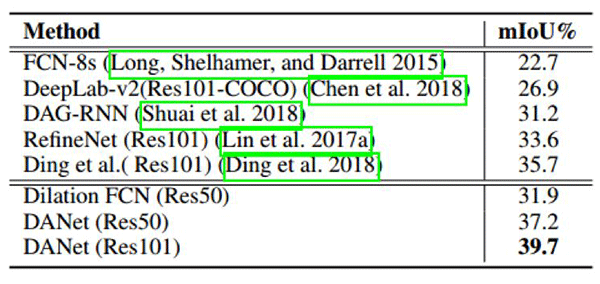
表 5:在 COCO Stuff 测试集上的分割结果
中科院自动化所图像与视频分析团队(IVA),隶属于模式识别国家重点实验室,有着深厚的学术底蕴和强大的人才支持,在 PAMI,TNNLS,TIP 等重要国际期刊和 CVPR,ICCV,ECCV 等国际会议上发表论文数百余篇,论文具有国际影响力,其中有多篇论文被 ESI 国际性基本科学指标数据库列为高被引论文。在 ICCV 2017 COCO-Places 场景解析竞赛、京东 AI 时尚挑战赛和阿里巴巴大规模图像搜索大赛踢馆赛等多次拔得头筹。
















