在许多机器学习应用(如机器人学、自动驾驶及广告排名)中,深度神经网络受到延迟、能耗及模型大小等因素的限制。人们提出了很多模型压缩方法来提高神经网络的硬件效率 [26 ,19 ,22]。模型压缩技术的核心是决定每一层的压缩策略,因为各层的冗余情况不同,通常需要手工设计的启发方法和领域专业技术来探索模型尺寸、速度及准确率之间的大型设计空间权衡。设计空间如此之大,以至于手工设计的方法通常不是最优解,手动模型压缩也非常耗时。为了解决这一问题,本文旨在为任意网络自动寻找压缩策略,以达到优于基于规则的手工模型压缩方法的性能。
当前已有许多基于规则的模型压缩启发方法 [20,16]。例如,在抽取低级特征且参数最少的第一层中剪掉更少的参数;在 FC 层中剪掉更多的参数,因为 FC 层参数最多;在对剪枝敏感的层中减掉更少的参数等。然而,由于深度神经网络中的层不是孤立的,这些基于规则的剪枝策略并不是最优的,也不能从一个模型迁移到另一个模型。神经网络架构发展迅速,因此需要一种自动方法对其进行压缩,以提高工程效率。随着神经网络逐渐加深,设计空间的复杂度可达指数级,因此利用贪婪、基于规则的方法解决这一问题并不可行。所以,本文提出了针对模型压缩的 AutoML(AutoML for Model Compression,AMC),该方法利用强化学习自动采样设计空间并提高模型压缩的质量。图 1 展示了 AMC 引擎。压缩网络时,AMC 引擎通过基于学习的策略将此过程自动化,而不是依赖基于规则的策略和经验丰富的工程师。
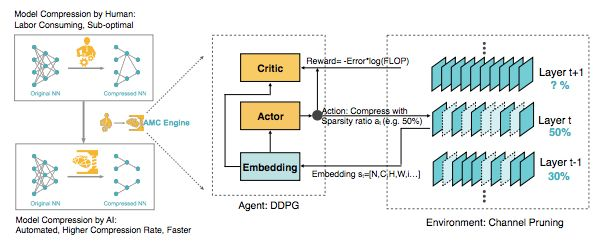
图 1:AMC 引擎图示。左:AMC 取代人类,使模型压缩完全自动化,而且表现优于人类。右:将 AMC 构造成强化学习问题。作者逐层处理了一个预训练网络(即 MobileNet)。强化学习智能体(DDPG)从 t 层接收嵌入 s_t,输出稀疏比率 a_t。用 a_t 对层进行压缩后,智能体移动到下一层 L_t+1。评估所有层都被压缩的修剪后模型的准确率。最后,奖励 R 作为准确率和 FLOP 的函数被返回到强化学习智能体。
在本文中,压缩模型的准确率对每一层的稀疏性非常敏感,需要细粒度的动作空间。因此,作者没有在离散空间中搜索,而是提出了一种带有 DDPG[32] 智能体的连续压缩比控制策略,通过试验和误差来学习:在鼓励模型收缩和加速的同时惩罚准确率损失。行为-评判结构也有助于减少差异,促进更稳定的训练。具体来说,该 DDPG 智能体逐层处理网络。对于每层 L_t,智能体接收一层嵌入 s_t,s_t 编码该层的有用特性,然后输出精确的压缩比 a_t。用 a_t 压缩 L_t 层后,智能体移动到下一层 L_t+1。所有压缩层修剪模型的验证准确率是在没有微调的情况下进行评估的,该准确率可有效代表微调准确率。这种简单的近似可以减少搜索时间,而不必重新训练模型,并提供高质量的搜索结果。策略搜索完成后,对最佳探索模型进行微调,以获得最佳性能。
本文针对不同的场景提出了两种压缩策略搜索协议。针对受延迟影响较大的人工智能应用(如移动 APP、自动驾驶汽车和广告排名),本文提出了资源受限的压缩,以便在给定最大量硬件资源(如 FLOP、延迟和模型大小)的情况下实现最佳准确率;对于质量至上的人工智能应用(如 Google Photos),本文提出了保证准确率的压缩,以便在不损失准确率的情况下得到最小的模型。
作者通过限制搜索空间来实现资源受限的压缩,在搜索空间中,动作空间(剪枝率)受到限制,使得被智能体压缩的模型总是低于资源预算。对于保证准确率的压缩,作者定义了一个奖励,它是准确率和硬件资源的函数。有了这个奖励函数,作者能够在不损害模型准确率的前提下探索压缩的极限。
为了证明其广泛的适用性,作者在多个神经网络上评估了该 AMC 引擎,包括 VGG [45], ResNet [21], and MobileNet [23],并测试了压缩模型从分类到目标检测的泛化能力。大量实验表明,AMC 提供了比手工设计的启发式策略更好的性能。对于 ResNet-50,作者把专家调优的压缩比 [16] 从 3.4 倍提高到了 5 倍而不损失准确率。此外,该研究将 MobileNet 的 FLOP 减少了 2 倍,使最高准确率达到了 70.2%,这一数字的曲线比 0.75 MobileNet 的帕累托曲线(Pareto curve)更好。在 Titan XP 和安卓手机上,分别实现了 1.53 倍和 1.95 倍的加速。
论文:AMC: AutoML for Model Compression and Acceleration on Mobile Devices

论文链接:https://arxiv.org/pdf/1802.03494.pdf
摘要:移动设备的计算资源和能耗预算都很有限,因此模型压缩对于在移动设备上部署神经网络模型至关重要。传统的模型压缩技术依赖手工设计的启发式和基于规则的策略,需要领域专家探索较大的设计空间,在模型大小、速度和准确率之间作出权衡,而这通常是次优且耗时的。本论文提出了适用于模型压缩的 AutoML(AMC),利用强化学习提供模型压缩策略。这一基于学习的压缩策略优化传统的基于规则的压缩策略,因其具备更高的压缩率,能够更好地维持准确率,免除人类的手工劳动。在 4 倍每秒浮点运算次数缩减的情况下,在 ImageNet 上对 VGG-16 进行压缩时,使用我们的压缩方法达到的准确率比使用手工设计的模型压缩策略的准确率高 2.7%。我们将该自动、一键式压缩流程应用到 MobileNet,在安卓手机上得到了 1.81 倍的推断延迟速度提升,在 Titan XP GPU 上实现了 1.43 倍的速度提升,而 ImageNet Top-1 准确率仅损失了 0.1%。

表 1:模型搜索强化学习方法对比(NAS:神经架构搜索 [57]、NT:网络变换(Network Transformation)[6]、N2N:Network to Network [2] 和 AMC:AutoML for Model Compression。AMC 与其他方法的区别在于它无需微调和连续搜索空间控制即可获取奖励,且能够生成兼具准确率和适应有限硬件资源的模型。
3.3 搜索协议
资源受限的压缩。通过限制动作空间(每一层的稀疏率(sparsity ratio)),我们能够准确达到目标压缩率。我们使用下列奖励函数:

通过调整奖励函数获得保证准确率的压缩,我们可以准确找到压缩的极限而不损失准确率。我们凭经验观察到误差与 log(FLOP s) 或 log(#Param) [7] 成反比。受此启发,我们设计了以下奖励函数:


4 实验
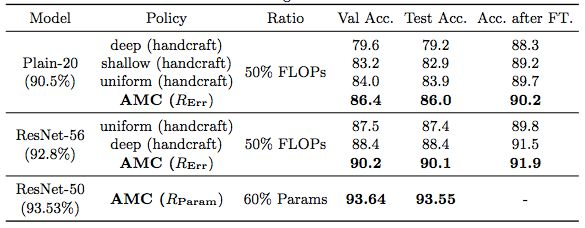
表 2:Plain-20、ResNet [21] 在 CIFAR-10 [28] 上的剪枝策略对比。R_Err 指使用通道剪枝的限制 FLOP 压缩,R_Param 指使用微调剪枝的保证准确率压缩。对于浅层网络 Plain-20 和较深层的网络 ResNet,AMC 显著优于手动设计的策略。这说明无需微调也能实现高效压缩。尽管 AMC 在模型架构上做了很多尝试,但本文使用的是单独的验证集和测试集。实验中未观察到过拟合现象。
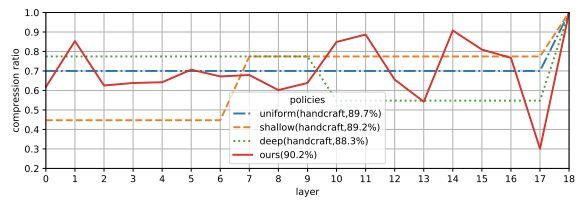
图 2:在 2 倍每秒浮点运算次数的情况下,Plain-20 的剪枝策略对比。统一策略为每个层统一设置相同的压缩率。浅层和深层策略分别大幅修剪较浅和较深的层。AMC 给出的策略看起来像锯齿,类似于瓶颈结构 [21]。AMC 给出的准确率优于手工策略。
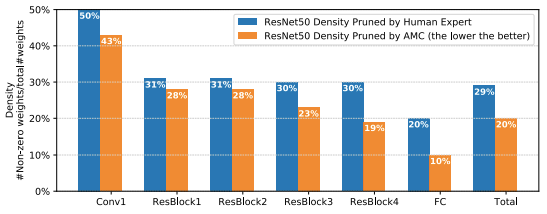
图 4:本文中的强化学习智能体(AMC)可以在不损失准确率的前提下将模型修剪为与人类专家相比密度较低的模型(人类专家:在 ResNet50 上压缩 3.4 倍。AMC:在 ResNet50 上压缩 5 倍)。
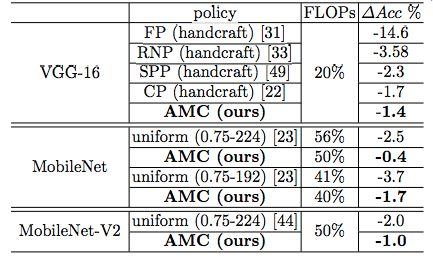
表 3:基于学习的模型压缩(AMC)优于基于规则的模型压缩。基于规则的启发方法不是最优方法。(参考信息:VGG-16 的基线 top-1 准确率是 70.5%,MobileNet 是 70.6%,MobileNet-V2 是 71.8%)。
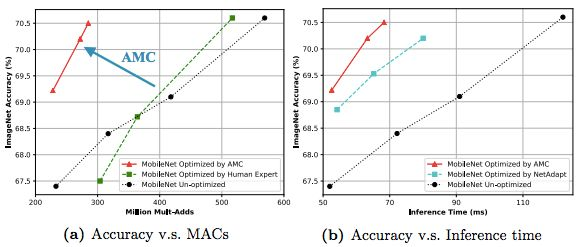
图 5:(a)比较 AMC、人类专家、未修剪的 MobileNet 之间的准确率和 MAC 权衡。在帕累托最优曲线中,AMC 遥遥领先人类专家。(b)比较 AMC、NetAdapt、未修剪 MobileNet 之间的准确率和延迟权衡。AMC 大幅改善了 MobileNet 的帕累托曲线。基于 AMC 的强化学习在帕累托曲线上超越了基于启发方法的 NetAdapt(推断时间都是在谷歌 Pixel 1 上测量的)。
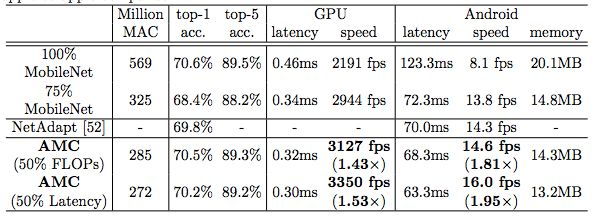
表 4:AMC 加速 MobileNet。之前利用基于规则的策略修剪 MobileNet 导致准确率大幅下降 [31],但 AMC 利用基于学习的修剪就能保持较高的准确率。在谷歌 Pixel-1 CPU 上,AMC 实现了 1.95 倍的加速,批大小为 1,同时节省了 34 % 的内存。在英伟达 Titan XP GPU 上,AMC 实现了 1.53 倍的加速,批大小为 50。所有实验中的输入图像大小为 224×224,苹果与苹果的比较不采用量化。
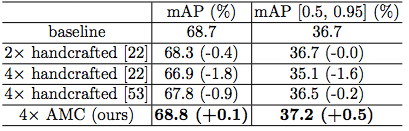
表 5:在 PASCAL VOC 2007 上用 VGG16 压缩 Faster R-CNN。与分类任务一致,AMC 在相同压缩比的情况下,在目标检测任务上也能获得更好的性能。
















