鸡生蛋与蛋生鸡,纵览神经架构的搜索方法
从谷歌渐进式的架构搜索到 CMU 的可微架构搜索,利用神经网络自动搭建不同的神经网络架构已经受到广泛的关注。最近弗莱堡大学的研究者发表了一篇论文纵览不同的神经架构搜索方法,他们从神经网络的搜索空间、搜索策略以及性能评估策略等三个方向探讨了不同的思路与方法。

深度学习在感知任务中取得的成功主要归功于其特征工程过程自动化:分层特征提取器是以端到端的形式从数据中学习,而不是手工设计。然而,伴随这一成功而来的是对架构工程日益增长的需求,越来越多的复杂神经架构是由手工设计的。神经架构搜索(NAS)是一个自动架构工程过程,因此成为自动化机器学习的合理发展方向。NAS 可以看做 AutoML 的子领域,与超参数优化和元学习有诸多交叉之处。我们根据三个维度对 NAS 方法进行分类:搜索空间、搜索策略及性能评估策略:
- 搜索空间。搜索空间定义了原则上可以表征的架构。结合有关任务属性的先验知识,可以减少搜索空间的大小并简化搜索。然而,这样做会引入人类偏见,进而阻碍找到超出人类现有知识的新型架构建筑块。
- 搜索策略。搜索策略详细说明了如何探索搜索空间。它包含了经典的「探索-利用」权衡;一方面,我们需要快速找到性能良好的架构,另一方面,我们应该避免过早收敛到次优架构区域。
- 性能评估策略。NAS 的目标是找到对未知数据实现高预测性能的架构。性能评估指的是评估这类性能的过程:最简单的选项是对数据执行标准架构训练和验证,但是这样做计算成本昂贵,而且限制了可以探索的架构数量。因此,近期的研究多集中于开发降低这些性能评估成本的方法上。
上面三个方向可以参考图 1 进行说明,本文也是根据这三个维度构建的。

图 1:神经架构搜索方法图解。搜索策略从一个预定义的搜索空间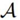 中选择架构 A。该架构被传递到一个性能评估策略,接下来该策略将 A 的评估性能返回给搜索策略。
中选择架构 A。该架构被传递到一个性能评估策略,接下来该策略将 A 的评估性能返回给搜索策略。
论文:Neural Architecture Search: A Survey

论文地址:https://arxiv.org/abs/1808.05377v1
1. 摘要
在过去几年中,深度学习在很多方面都取得了显著进步,比如图像识别、语音识别、机器翻译等。取得这一进展的一个关键因素是新型神经架构。目前使用的架构大部分都是由专家手动开发的,而这个过程非常耗时且易出错。正因如此,人们对于自动神经架构搜索的方法越来越感兴趣。我们对这一研究领域的现有工作进行了概述,并按照搜索空间、搜索策略和性能评估策略三个维度对其进行了分类。
2. 搜索空间
搜索空间定义了 NAS 方法在原则上可能发现的神经架构。我们现在讨论最近的研究成果中常见的搜索空间。
链式结构神经网络空间是一个相对简单的搜索空间,如图 2(左)所示。链式结构神经网络架构 A 可以写成一个 n 层序列,其中第 i 层接收第 i-1 层的输出作为输入,而第 i 层的输出则作为第 i + 1 层的输入,即 A = Ln ◦ . . . L1 ◦L0。然后将搜索空间参数化为:(i)最大层数 n 可能是无界的;(ii)每一层都可以执行的操作类型,如池化层、卷积层,或更高级的层类型,如深度可分离卷积层(Chollet, 2016)或扩张卷积层(Yu and Koltun, 2016);(iii)与操作相关的超参数,如卷积层的滤波器数、核大小和步长,或者全连接网络(Mendoza et al, 2016)的单元数。要注意(iii)中的参数要以 (ii) 为条件,因此搜索空间的参数化长度不是固定的,而是一个条件空间。
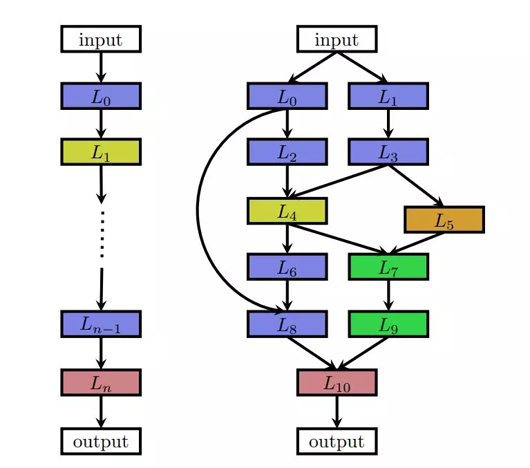
图 2:不同架构空间示意图
图2中每个节点与神经网络中的一个层对应,例如卷积层或池化层。不同类型的层由不同的颜色显示。从 L_i 到 L_j 的边缘表示 L_i 接收 L_j 的输出作为输入。图左:链式结构空间的元素。图右:具有额外的层类型、多个分支和跳跃式连接的复杂搜索空间的元素。
近期关于 NAS 的研究(Brock et al, 2017; Elsken et al, 2017; Zoph et al, 2018; Elsken et al, 2018; Real et al, 2018; Cai et al, 2018b),结合了手工构建架构中已知的现代设计元素,例如跳跃式连接,它允许构建具有多分支的复杂网络,如图 2 所示(右)。
受到手动使用不同基元构建神经网络架构的激励(Szegedy et al, 2016; He et al, 2016; Huang et al, 2017),Zoph 等人(2018)提议搜索这种基元(将其称为单元),而不是整个架构。他们优化了两种不同的单元:一种保留输入维度的常规单元,另一种是缩小空间维度的缩减单元。如图 3 所示,最终的架构是通过以预定义的方式堆叠这些单元来构建的。

图 3:单元搜索空间图解
图 3中左图:两个不同的单元:常规单元(上)和缩减单元(下)(Zoph et al, 2018)。右图:按顺序堆叠单元构建的架构。注意:单元也可以以更复杂的方式组合,例如在多分支空间中,简单地用单元替换层。
与上面讨论的空间相比,这一搜索空间有两大优势:
- 搜索空间大幅减小,因为单元可能相对较小。例如,Zoph 等人(2018)估计,与之前的成果(Zoph and Le, 2017)相比,这一搜索空间的速度提高了 7 倍,而且性能更好。
- 通过调整模型中使用的单元数量,可以更容易地将单元转移到其他数据集。Zoph 等人(2018)将 CIFAR-10 上优化后的单元转移到了 ImageNet 数据集并实现了当前最佳性能。
3. 搜索策略
许多不同的搜索策略可以用来探索神经架构空间,包括随机搜索、贝叶斯优化、进化算法、强化学习(RL)和基于梯度的方法。从历史上看,进化算法在几十年前就已经被许多研究人员用来演化神经结构(以及它们的权重)。
为了将 NAS 构造为强化学习问题(Baker et al, 2017a; Zoph and Le, 2017; Zhong et al, 2018; Zoph et al, 2018),神经架构的生成可以视为智能体选择的动作,动作空间和搜索空间相同。智能体获得的奖励基于已训练架构在不可见数据上的性能评估。不同的 RL 方法在表示智能体的策略和如何优化它们存在差异:Zoph 和 Le(2017)使用循环神经网络(RNN)策略对一个字符串进行序列采样,该字符串反过来对神经架构进行编码。Baker 等人利用 Q-learning 训练策略,该策略依次选择层的类型和对应的超参数。
Cai 等人提出了一个相关方法,将 NAS 构建为序列决策过程:在他们的方法中,状态是当前(部分训练的)架构、奖励是对架构性能的估计,并且该动作对应于遗传算法中应用的 function-preserving 突变,也称为网络态射。
使用 RL 的另一种代替方法是优化神经架构的进化算法。早期的神经进化算法使用遗传算法来优化神经架构及其权重;然而,当扩展到具有数百万个权重的现代神经架构时,它就回天乏术了。
更新的神经进化算法(Real et al, 2017; Suganuma et al, 2017; Liu et al, 2018a; Real et al, 2018; Miikkulainen et al, 2017; Xie and Yuille, 2017; Elsken et al, 2018)使用基于梯度的方法来优化权重,而进化算法仅用于优化神经结构本身。
Real 等人(2018)在一项用例研究中对比了强化学习、进化和随机搜索,得出的结论是:强化学习和进化在最终测试准确度方面表现相当,进化的随时性能更好,并找到了更精简的模型。
贝叶斯优化(BO)是超参数优化中最流行的方法之一,但还没有被许多团体应用到 NAS 中,因为典型的 BO 工具箱基于高斯过程并关注低维连续优化问题。架构搜索空间也以分层的方式被搜索,如与进化一起(Liu et al, 2018a)或通过基于序列模型的优化(Liu et al, 2017)。
与上述无梯度优化方法相比,Liu 等人(2018b)提出用搜索空间的连续松弛方法来实现基于梯度的优化:研究者从一系列运算 {O_1, . . . , O_m} 中计算凸组合,而不是固定要在特定层执行的单个运算 O_i(如卷积或池化)。
4. 性能评估策略
前一章节讨论了搜索策略,即希望机器能自动搜索到一个神经网络架构 A,并能最大化它在某些性能度量上的表现,这些度量可能是在未知数据上的准确率等。为了引导神经架构的搜索过程,这些策略需要评估当前搜索到架构 A 的性能。最简单的方式即在训练集中训练搜索到的架构 A,并在验证数据中评估它的性能。然而,从头训练这样的一个架构经常导致 NAS 算法需要数千 GPU 和数天的时间,这种计算力的需求太大(Zoph and Le, 2017; Real et al, 2017; Zoph et al, 2018; Real et al, 2018)。
为了降低计算力负担,我们完全可以基于完整训练后实际性能的低保真度度量来评估性能,这也可以称为代理度量。这种低保真度包括更短的训练时间((Zoph et al, 2018; Zela et al, 2018)、在子数据集上训练(Klein et al, 2017a)、在低分辨率图像上训练(Chrabaszcz et al, 2017)、或者在每一层使用较少卷积核的网络上训练(Zoph et al, 2018; Real et al, 2018)等。虽然这些低保真度的近似方法降低了计算成本,但它们同样在估计中也引入了偏差,这样性能通常会被低估。不过只要搜索策略仅依赖于排序不同的架构,那么相对排序仍然是稳定的,这也就不是什么问题。然而,最近的研究表明,当简单的近似和完整评估之间的差异太大,相对排序的变化可能会非常大(Zela et al, 2018),我们需要逐渐增加保真度(Li et al, 2017; Falkner et al, 2018)。
5. 未来方向
在这一节,我们将讨论几个 NAS 当前和未来的研究方向。大多数已有的研究聚焦于图像分类的 NAS。因此我们认为扩展到图像分类之外,将 NAS 应用到更少被探索的领域非常重要。值得注意的是,在这一方向走出的第一步是将 NAS 应用到语言建模(Zoph and Le, 2017)、音乐建模(Rawal and Miikkulainen, 2018)和生成模型(Suganuma et al, 2018);强化学习、生成对抗网络或传感融合上的应用可能是未来有潜力的方向。
另一个方向是为多任务问题(Liang et al, 2018; Meyerson and Miikkulainen, 2018)和多目标问题(Elsken et al, 2018; Dong et al, 2018; Zhou et al, 2018)开发 NAS 方法,其中资源有效性的度量与对未见过数据的预测性能一起被用作目标函数。
尽管 NAS 的性能非常惊艳,但它无法解释为什么特定架构表现良好,也无法说明独立运行的架构将会有多么相似。识别常见的特性,更好地理解这些对性能有显著影响的机制,并探索这些特性是否能泛化到不同的问题也是未来重要的研究方向。

时间:2018-09-02 21:59 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















