汤晓鸥为CNN搓了一颗大力丸
大把时间、大把GPU喂进去,训练好了。
接下来,你可能会迎来伤心一刻:
同学,测试数据和训练数据,色调、亮度不太一样。
同学,你还要去搞定一个新的数据集。
是重新搭一个模型呢,还是拿来新数据重新调参,在这个已经训练好的模型上搞迁移学习呢?
香港中文大学-商汤联合实验室的潘新钢、罗平、汤晓鸥和商汤的石建萍,给出了一个新选项。
他们设计了一种新的卷积架构,既能让CNN提升它在原本领域的能力,又能帮它更好地泛化到新领域。
这个新架构叫做IBN-Net。
它在伯克利主办的WAD 2018 Challenge中获得了Drivable Area(可行驶区域)赛道的冠军。相关的论文Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net发表在即将召开的计算机视觉顶会ECCV 2018上。

给神经网络加个buff
IBN-Net并不是一个像ResNet那样独立的神经网络架构,它可以和其他模型结合起来使用,提升它们的性能,但不会增加计算成本。经典的DenseNet、ResNet、ResneXt、SENet等等,都能用它来助攻。
这就相当于给深度学习模型加了个buff,或者说,喂下了一颗大力丸。

同时,它还可以算是迁移学习的替代品。
在一个数据集上训练好了模型,如果测试数据和训练集风格、颜色上有点不一样,或者换个数据集来测试,模型的性能就会大打折扣。
这时候,按套路就该迁移学习出场了,用新数据给训练好的模型调参。
数据集这么多,现实世界更是丰富多彩,一个一个地去重新搭模型或者调参数,要多少工程师才够用?
而IBN-Net就不需要新数据来调参,能自动让模型更好地适应新的领域。
不怕加滤镜,跨越次元壁
在图像识别和语义分割任务上,IBN-Net都能帮深度学习模型提分。
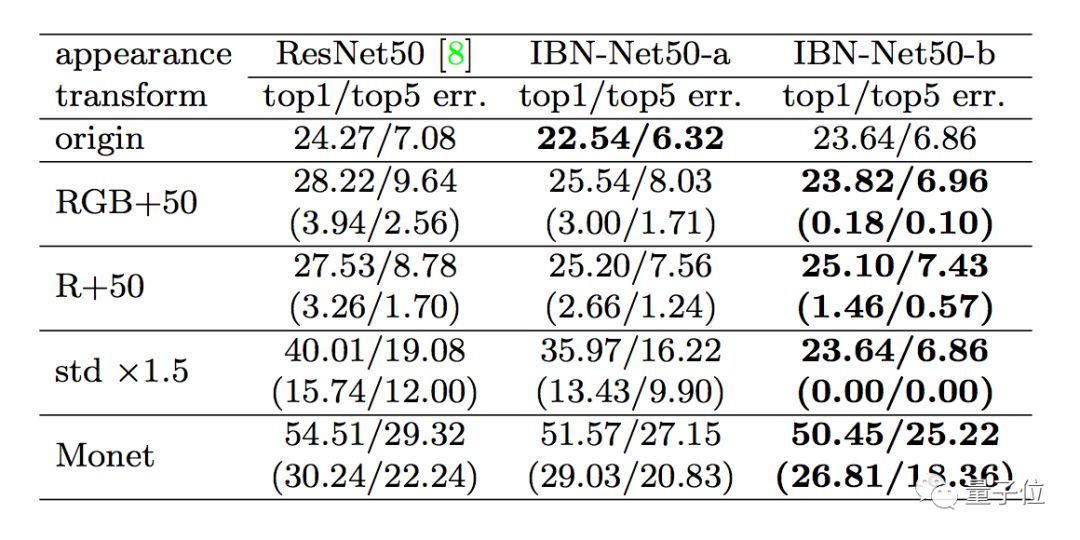
比如在ImageNet上,加了IBN-Net(的各种变体),就能在同样的参数设置,同样的计算成本下,让ResNet50的错误率下降0.5-1.5个百分点。
如果测试数据在原始ImageNet的基础上再做一些变化,调整一下颜色亮度对比度,甚至用Cycle-GAN改改风格,基本款ResNet50错误率就会大幅上升。而加了IBN-Net的版本,错误率就能少上升一些,如上图括号中的数据所示。
语义分割任务上也是一样。
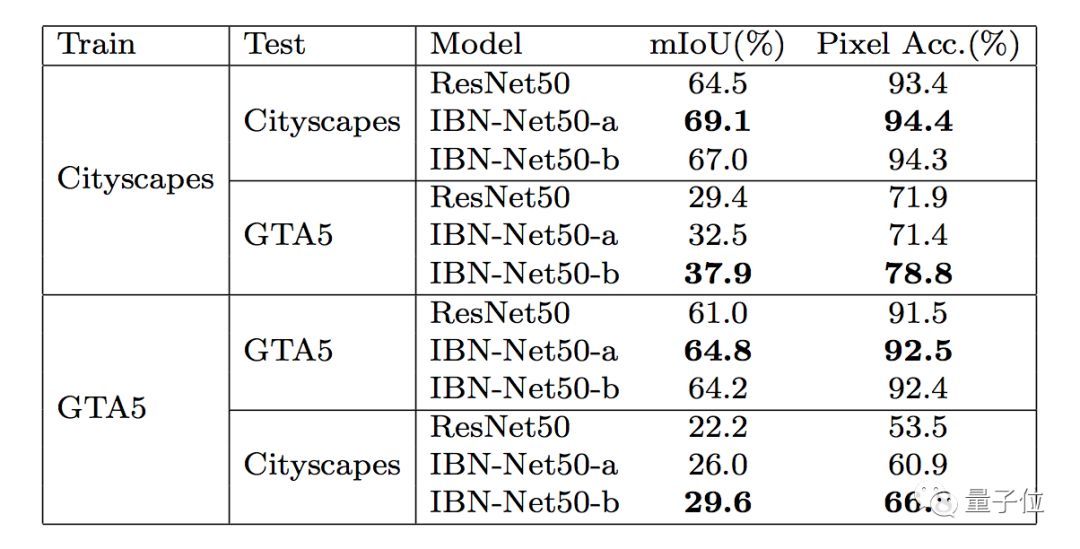
IBN-Net加持的ResNet50,能在现实世界的城市街道图像数据集Cityscapes、虚拟世界的GTA5数据集上都取得比原版更好的成绩。
想让模型跨越虚拟与现实之间的次元壁,既能适应Cityscapes,也能用在GTA5上,IBN-Net也很擅长。
论文中说,将模型从Cityscapes迁移到GTA5,用IBN-Net能让迁移后的性能少下降8.5%;从GTA5迁移到Cityscapes,则能少下降7.5%。
这种跨越次元壁的迁移可大有用处。比如说在自动驾驶领域,用游戏来初步训练无人车是个常见的操作,可是把这样训练出来的搬到现实环境中,显然要经过大量调整。
让模型更快更好地适应不同环境的IBN-Net,简直就是效率提升利器。
“IBN”究竟是什么?
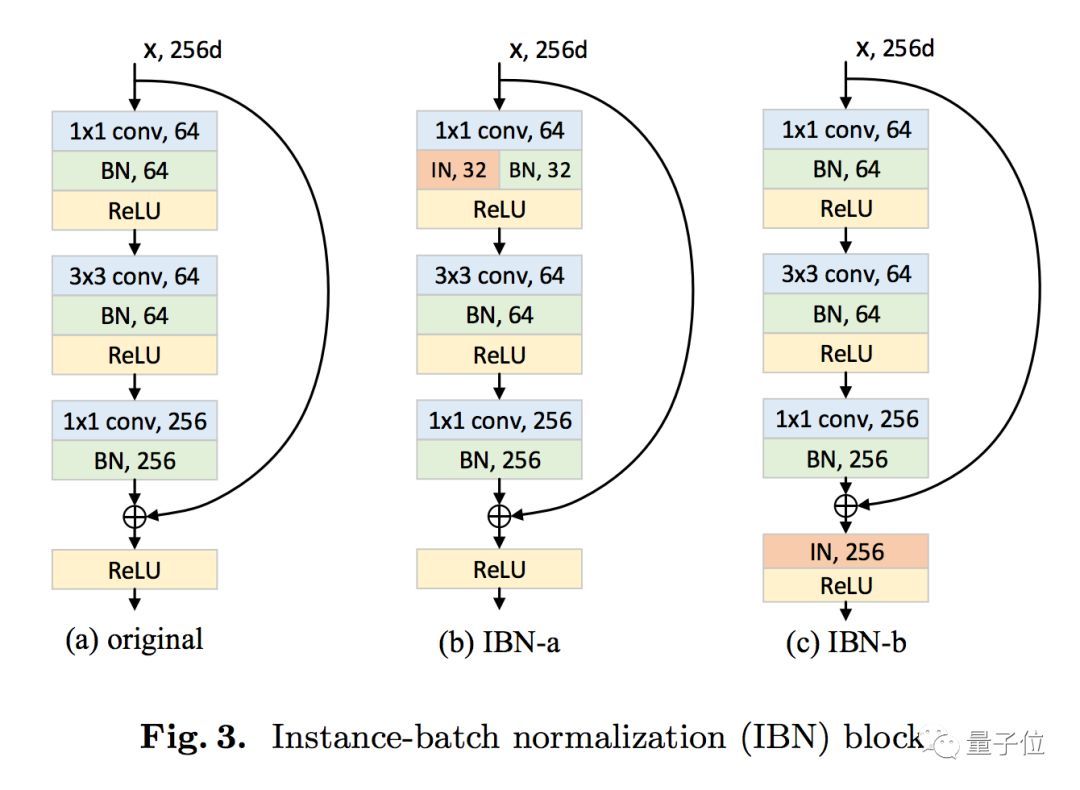
要理解这个IBN-Net的架构,要先从两种标准化方法IN(Instance Normalization,实例标准化)和BN(Batch Normalization,批标准化)。
它们都能让神经网络调参更简单,用上更高的学习速率,收敛更快。如果你搭过图像分类模型,batchnorm(BN)大概很熟悉了,而IN更多出现在风格迁移等任务上。与BN相比,IN有两个主要的特点:第一,它不是用训练批次来将图像特征标准化,而是用单个样本的统计信息;第二,IN能将同样的标准化步骤既用于训练,又用于推断。
潘新钢等发现,IN和BN的核心区别在于,IN学习到的是不随着颜色、风格、虚拟性/现实性等外观变化而改变的特征,而要保留与内容相关的信息,就要用到BN。
二者结合,就成了IBN-Net。
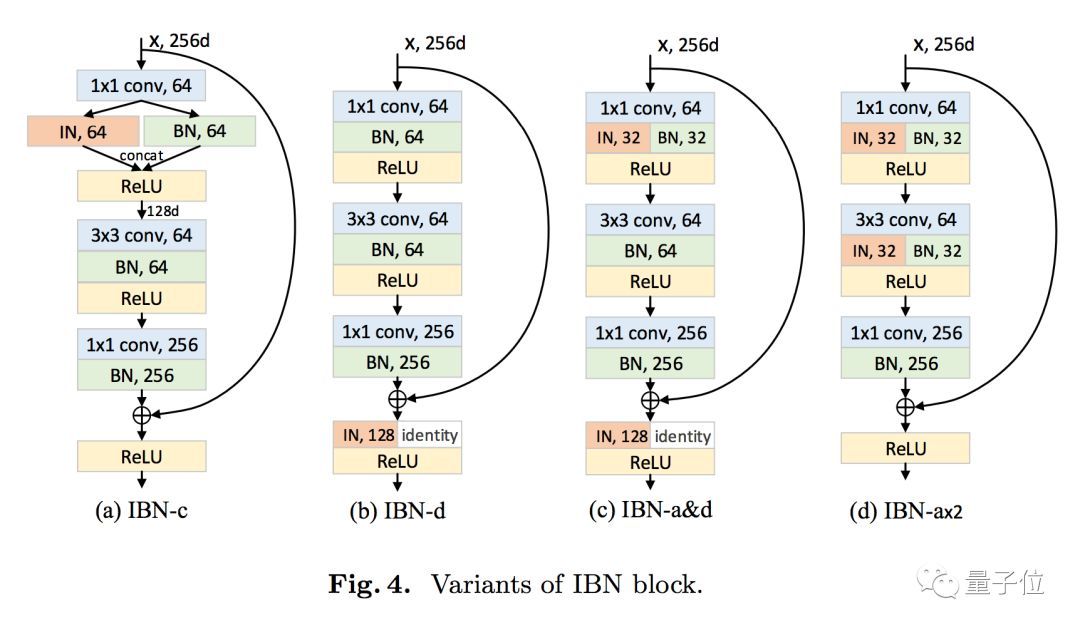
还可以根据需求,来调整IN和BN在模型中的搭配。
各种变体的具体情况,论文中有更清晰的描述。
论文:https://arxiv.org/pdf/1807.09441.pdf
代码:XingangPan/IBN-Net
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!

时间:2018-08-28 01:12 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Transformer为何能闯入CV界秒杀CNN?
- [机器学习]巨头竞逐Chiplet
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]龙泉寺贤超法师:用 AI 为古籍经书识别、断句、
- [机器学习]Transformer为何能闯入CV界秒杀CNN?
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]苹果M1预示着RISC-V的崛起?
- [机器学习]终于讲明白了!国外大神超详细解读:苹果M1为什
- [机器学习]David Patterson:RISC-V将成为世界上最重要的指令集
- [机器学习]为什么说苹果M1芯片是颠覆性的
相关推荐:
网友评论:
最新文章

热门文章














