哪个才是解决回归问题的最佳算法?线性回归、

现在,不管想解决什么类型的(ML)问题,都会有各种不同的算法可以供你选择。尽管在一定程度上,一种算法并不能总是优于另外一种算法,但是可以将每种算法的一些特性作为快速选择最佳算法和调整超参数的准则。
本文,我们将展示几个著名的用于解决回归问题的机器学习算法,并根据它们的优缺点设定何时使用这一准则。尤其在为回归问题选择最佳机器学习算法上,本文将会为你提供一个重要的引导!
▌线性回归和多项式回归

线性回归
从简单的情况开始,单变量线性回归使用线性模型为单个输入自变量(特征变量)和输出因变量创建关系模型。更为一般的情况是多变量线性回归,它为多个独立的输入自变量(特征变量)与输出因变量之间创建关系模型,该模型始终为线性,这是因为输出变量是输入变量的线性组合。
第三种最常见的情况是多项式回归,该模型是特征变量的非线性组合,例如:指数变量,正弦和余弦等。然而,这需要了解数据是如何与输出相关的。我们可以使用随机梯度下降(SGD)对回归模型进行训练。
优点
-
可以快速建模,特别适用于所要建模的关系不是特别复杂并且数据量不大。
-
线性回归简单且易于理解,有利于商业决策。
缺点
-
对于非线性数据进行多项式回归设计可能比较困难,因为必须具有特征变量之间关系和数据结构的一些信息。
-
由于上述原因,当涉及到数据复杂度较高时,这些模型的性能不如其他模型。
▌神经网络
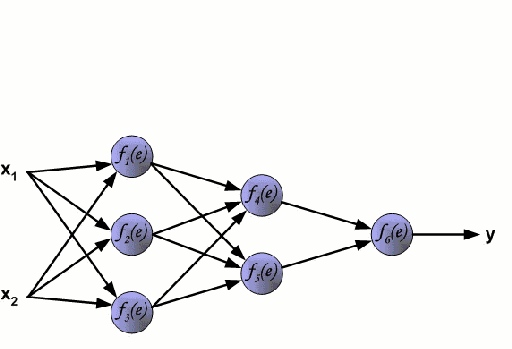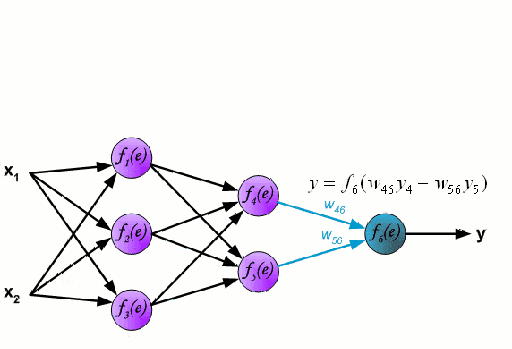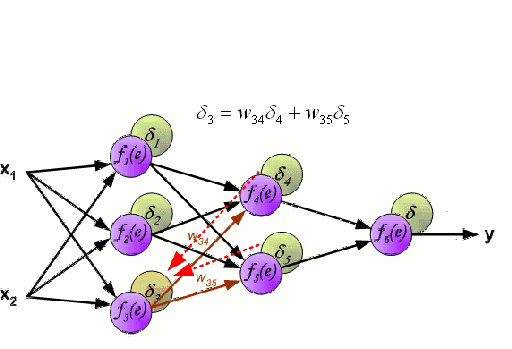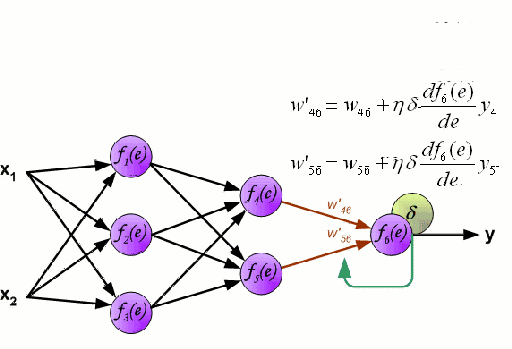
神经网络
神经网络是由一组相互连接的节点组成,这些节点被称为神经元。数据中的输入特征变量作为多变量线性组合被传递给这些神经元,其中乘以每个特征变量的值被称为权重。然后将非线性应用于该线性组合,从而为神经网络对复杂的非线性关系进行建模。神经网络可以有多个层,其中每一层的输出传递给下一层的方式都是相同的。输出端通常不会使用非线性。我们可以使用随机梯度下降(SGD)和反向传播算法对神经网络进行训练,这两种算法均显示在上面的动态GIF图中。
优点
-
由于神经网络可以有多个非线性的层(和参数),因此对非常适合对比较复杂的非线性关系建模。
-
神经网络中的数据结构基本上对学习任何类型的特征变量关系都非常灵活。
-
研究表明,为网络提供更多的训练数据(不管是增加全新的数据集还是对原始数据集进行扩张)可以提高网络性能。
-
设置也有利于提高网络性能。
缺点
-
这些模型较复杂,因此不太容易被理解。
-
网络的训练可能非常具有挑战性和计算密集性,需要对超参数进行微调并设置学习率表。
-
网络的高性能需要大量的数据来实现,在“少量数据”情况下通常不如其他机器学习算法的性能。
▌回归树和随机森林
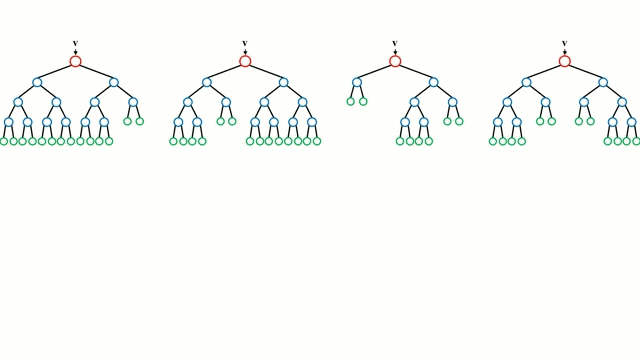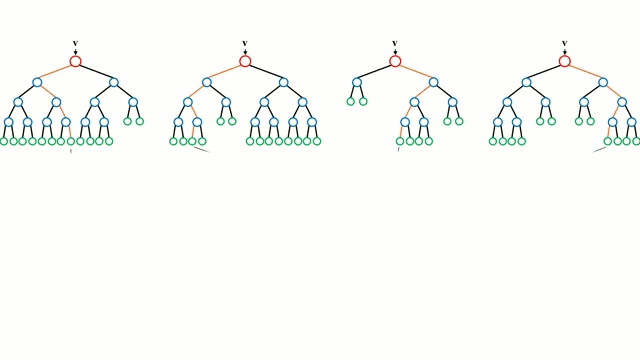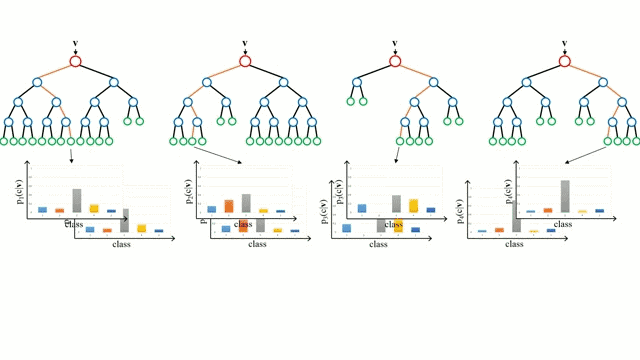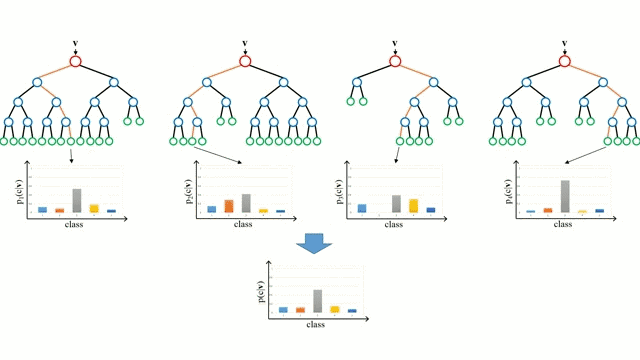
随机森林
决策树是一种直观的模型,它通过遍历树的分支并根据节点的决策选择下一个分支进行遍历。决策树归纳法(Decision Tree Induction)将一组训练实例作为输入,确定哪些属性最适合分割,并对数据集进行分割,在分割后的数据集上进行循环,直到对所有训练实例都被分类为止,任务结束。
构建决策树旨在分割可能创建纯度子节点的属性,这将会尽可能的减少对数据集中的所有实例进行分类所需要的分割次数。纯度是通过信息增益来衡量的,这涉及到为了进行正确的分类而需要知道有多少以前没有的实例。在实际应用中,这通过比较熵或者将当前数据集分区的单个实例分类所需的信息的量来衡量,即若当前的数据集分区在给定的属性上被进一步划分的话,就可以对单个实例进行分类。
随机森林是一个简单的决策树的集合,输入向量在多个决策树上运行。对于回归问题,所有决策树的输出值都是平均的;对于分类问题,使用一个投票方案来确定最终的类别。
优点:
-
善于学习复杂且高度非线性的关系,通常可以具有很高的性能,其性能优于多项式回归,并且通常与神经网络的性能相当。
-
非常便于理解,虽然最终的训练模型可以学习较为复杂的关系,但是在训练过程中建立的决策边界很容易理解。
缺点:
-
由于训练决策树的性质,可能很容易出现重大的过度配合。完整的决策树模型可能过于复杂并且包含不必要的结构。有时可以通过适当的树木修剪和较大的随机森林合奏来缓解这种情况。
-
使用较大的随机森林合奏来获得更高的性能,会使速度变慢,并且需要更多的内存。
▌结语
机器学习中有一种定理叫做“没有免费的午餐”:并不存在一个能够解决所有问题的机器学习算法。机器学习算法的性能在很大程度上依赖于数据大小和数据结构。因此,我们可以通过简单的实验和判断来测试所选择是否为最佳算法。

时间:2018-08-25 02:22 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















