【一网打尽】机器学习梯度下降优化算法
1. 梯度下降
梯度的方向是上升的方向,所以我们是沿着梯度的反方向,每一次根据学习率来决定走的步长,争取到达谷底。
2. 梯度下降变体
各种各样的变体,主要是为了在参数更新准确度和所需要时间之间做一个trade-off。
2.1 Batch gradient descent
使用所有的数据集来计算更新梯度。
缺点:
- 非常耗时。计算出整个数据集的梯度才能更新一次
- 数据集大到无法放入内存中时就不再适用了
- 不支持在线更新
Batch gradient descent优点:
- 对于凸函数,保证收敛到全局最优解
- 对于非凸函数,保证收敛到局部最优解
2.2 Stochastic gradient descent
每一次更新参数仅仅使用一个样本。
优点:
- 计算非常快
- 适用于在线学习
缺点:
- SGD每次使用一个样本进行梯度计算,方差比较大。导致目标函数波动比较大
2.3 Mini-batch gradient descent
每次选取一个mini batch,通常大小为32,128等。使用一个这样的mini batch来进行一次参数更新。是业内最通用的办法。
既可以保证参数优化方向的稳定性,目标函数不会出现剧烈震荡,同时又能加快收敛速度,减小计算量。
3. 指数加权平均
在讲后面的各个优化算法之前,我们必须先说清楚指数加权平均,因为他是后面Momentum Adam RMSprop的基础。只有理解了指数加权平均是怎么回事,才能更好的理解后面的优化算法
指数加权平均,英文为Exponentially weighted averages,在统计学中也被称为指数加权移动平均Exponentially weighted moving averages。是对加权平均的一种近似算法。
公式如下:
beta一般的取值为0.9。 按照这个公式计算出来的Vt相当于是t时刻结束的一个window内的Vi的加权平均值。window的大小为 1/(1 – beta), 权重对应一个指数函数。如下图:想象V的取值是上面的图像,对应的权重是下面的图像,加权平均就是把window内的两个图像上的值,对应位置相乘,然后求和即可。
windows_size = 1 / (1 - beta) 实际上我们知道Vt不仅仅包含这个window内的值,它包含从t=0开始的所有值的加权平均。但是我们忽略了之前的那些,因为那些值都太小了,临界处的值是 1/e * vt。
Bias correction
可以发现,在最开始的阶段,我们没有足够的数据组成window_size,所以出现的情况是:最开始的平均值求出来都偏小。可以使用Bias correction来解决这个问题。
Vt变为 Vt = Vt / (1 - beta ^ t)。这样最开始t比较小,Vt就会大一些。随着t的增大beta^t逐渐变为0,Vt也就恢复成原来的样子了。
4. 梯度下降优化算法
还有很多变体,这里只列出常用的一些。
4.1 SGD
最原始、最简单的梯度下降计算方法
原理
一个样本就进行一次更新。
公式
缺点
- 当某个维度上梯度比其他维度大很多时,SGD表现为犹豫不决的向前移动
- 一个样本更新一次方差会比较大,导致目标函数波动比较大
优点
- SGD引起的波动也可能会使它跳出局部最小值
- 计算量相对小,收敛更快
-
当学习率足够小的时候,SGD最终也能收敛到和
Batch gradient descent一样的效果
4.2 Momentum
Momentum是SGD的升级版
提出原因
SGD遇到某个维度梯度比较大会被大梯度方向带着一直往那边走,但是这不一定是最快的下降方向。
表现出来就是犹豫不决,来回波动,收敛很慢。
Momentum就是来解决这个问题的。
原理
使用原始的SGD可能会出现问题,当在不同方向上梯度相差非常大,会来回波动。而且你不能用比较大的学习速率,可能会直接超出函数的范围。只能用较小的学习率,导致学习非常慢。如下图:
像上图所示,纵轴上的梯度比较大,横轴上的梯度比较小。我们希望加快收敛速度,可以纵轴少走一点,横轴多走一点。
怎么实现那?用指数加权平均来取平均值!
因为,观察可以发现纵轴分量时而向上,时而向下,取平均值就比较小了。而横轴分量一直是向右的,取平均值不会造成太大影响。这就是Momentum的原理。
使用Momentum之后的效果:收敛更快
公式
其中,beta一般取值0.9,是指数加权平均的参数。alpha是学习速率。
优点
- 相比SGD,获得更快的收敛速度,减小震荡
缺点
- 小球总是跟着斜坡走,没有考虑斜坡之后的变化趋势。到达最优解之后,还在继续大幅度更新,会越过最优解。
4.3 NAG
NAG是Momentum的改进
提出原因
上面Momentum的小球只会沿着斜坡的方向走,即时到达了山底,再往前走又是上山的路了,它还在继续走,因为它不知道后面的情况到底是什么。
NAG就是期望一个更聪明的小球,它可以预知之后关于坡度的一些情况。这样当它发现快到达山底的时候就减速,准备停下来了。
公式
相比于Momentum唯一的变化,就是把在当前位置的求梯度,换成了对近似下一个位置求的梯度:
Momentum:
NAG:
原理
NAG全称是Nesterov accelerated gradient,它赋予Momentum感知接下来斜坡情况的能力。
在Momentum中,在t时刻,我们知道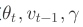 而且我们还可以求出目标函数在θtθt处的导数,然后就可以更新动量然后,就可以更新参数了:
而且我们还可以求出目标函数在θtθt处的导数,然后就可以更新动量然后,就可以更新参数了:
我们先把V_t的计算分成两部分:历史积累动量 + 目标函数在当前位置的梯度。可以看到,既考虑了历史上的动量(更新方向与速度),也考虑了在当前点的更新方向与速度。两者相加之后就得到了新的动量,用来新一轮的更新。可以看到这里起重要作用的是后面一部分:目标函数在当前位置的梯度,它表示当前位置坡度的走向,而这将会被算入总的动量中一点一点的决定我们小球的走向。
为了感知接下来的坡度走向,我们需要知道下一刻的位置从而可以计算出在该位置的梯度。但是,如果不先完成更新现在的位置,就无法得知下一刻的位置;可是我们想根据下一刻的位置来更新当前的位置。。。
怎么办,先有鸡还是先有蛋?
一般遇到这种问题的解决办法就是:近似
我们先近似的模拟向前走一步!怎么走那?原来的走法是历史动量 + 当前位置梯度。近似一下,我们只保留第一部分:历史动量。模拟走出这一步,作为小球的下一个位置。这个位置的梯度近似的包含了后面斜坡的走势信息,我们用这个去更新原来的动量,再去更新参数,就为当前时刻的更新引入了斜坡将来的信息了。
下面我们从图上来感受下:
第一段小蓝线:当前位置的梯度 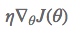
第二段长蓝线:之前积累的动量 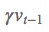
第一段棕线:先近似的滚一下,先把历史动量滚出来!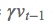
第一段红线:小球近似滚之后,新位置的梯度
第一段绿线:NAG最终的更新动量
总结一下:
- NAG通过引入下一个时刻位置的梯度信息,来感知之后的坡度,从而调整我们的更新步伐。
- 先按照历史累积动量走一次,新的位置近似认为是下一个时刻的位置;然后求出下一个时刻的位置的梯度;
- 也就是把原位置的梯度换成了下一个时刻位置的梯度。下一个时刻位置是通过走历史动量近似得到的。
优点
- 参数的更新,在Momentum的基础上又考虑了斜坡的走向。“提前刹车”
到目前位置,我们利用累积动量加速了SGD,并且根据感知斜坡走向来调整我们的更新。
我们还想做:根据每个参数的重要性,改善不同参数的学习速率,重要的大一些,不重要的小一些。
不同参数赋予不同更新幅度: AdaGrad、Adadelta、RMSprop。
4.4 Adagrad
提出原因
前面的算法在每次更新时,所有的参数学习速率都是相同的。我们希望改善这一情况,达到不同参数的学习速率是不同的。
公式
G是对应的参数i到目前时刻t位置的梯度g的平方的和,epsilon为常数防止除0,一般为1e-7,1e-8。另外,如果不做开方操作,算法的效果会非常差。
原理
Adagrad可以在每一个时刻t针对每一个参数使用不一样的学习速率。对于梯度比较大的地方使用较小的学习速率,对于梯度比较小的地方使用较大的学习速率。因为这个原因,AdaGrad非常适合于处理稀疏数据。
在每一个时刻t针对每一个参数的更新学习速率的调节是利用该参数的历史梯度信息来完成的。
优点
- 最大的优点:省去了人工调整学习速率的烦恼。一般学习速率初始化为0.01就不管了,算法会利用历史的梯度信息去自动调节
缺点
- 最大的缺点:分母上对梯度平方的不断累加。这个累加值会随着训练不断的增加,使得学习速率不断的减小,直到无限小模型学习不到任何东西为止
后面的Adadelta、RMSprop就是来解决这个问题的。
4.5 RMSprop
提出原因
针对Adagrad在后期学习率可能无限小导致找不到有用的解的问题,RMSprop在Adagrad的基础上做了一点小小的改进。
原理
Adagrad是对梯度平方进行了累加。RMSprop改进为使用梯度平方的指数加权平均,这样即使在训练后期,学习速率也不会变得无限小。
RMSprop 在mini batch中计算梯度g,然后对该梯度按照元素进行平方,记为 ,然后其进行指数加权平均,记为s:
,然后其进行指数加权平均,记为s:
然后,和Adagrad一样,将每个参数的学习速率调整一遍,同样是按元素操作:
epsilon为了防止除0,常见值为1e-8。eta为初始学习速率。和Adagrad一样,每个参数都拥有自己的学习速率。
总结:
RMSprop只在Adagrad的基础上修改了变量s的更新方法:对g的平方的累加改为对g的平方的指数加权平均。变量s可以看做是最近1/(1-gamma)个时刻的g平方的加权平均。参数的学习速率不会再一直下降了。
优点
- 参数学习率避免了在训练过程中一直下降的问题。
4.6 Adadelta
提出原因
和RMSprop一样,另外一个解决Adagrad学习率只降不升问题的算法是Adadelta。更有意思的是,Adadelta**没有学习率**这个超参数。
原理
Adadelta和RMSprop一样,累积量s不再使用梯度g平方直接累加。而是使用梯度g平方的指数加权平均来计算s。首先,在mini batch上计算梯度g;然后,使用梯度g的平方来做指数加权平均:
然后,计算当前需要迭代的参数的变换量g’:
上式中的dela_x初始化为0,并用当前迭代变换量g’的平方的指数加权平均来更新:
最后,更新参数:
优点
- 同样解决了Adagrad的学习率不断下降的问题
- 同时没有了超参数学习速率。使用参数改变量的平方的指数加权平均,然后开根号来代替
4.7 Adam
原理
Adam是组合了Momentum 和 RMSprop的优化算法。
Adam算法使用了Momentum动量变量v和RMSprop按梯度平方的指数加权平均变量s,并将它们初始化为0。在每次迭代中,首先计算梯度g,并递增迭代次数:
和Momentum类似,给定超参数 (作者建议0.9),对梯度g进行指数加权平均得到动量变量v:
(作者建议0.9),对梯度g进行指数加权平均得到动量变量v:
和RMSprop一样,给定超参数 (作者建议0.999),对梯度g的平方进行指数加权平均得到s:
(作者建议0.999),对梯度g的平方进行指数加权平均得到s:
v和s可以近似看做最近1/(1-beta1)个时刻梯度g和最近1/(1-beta2)个时刻梯度g的平方的加权平均。假设beta1=0.9, beta2=0.999,v和s都初始化为0,那么在时刻t=1我们得到v=0.1g, s=0.001g。可以看到,在迭代的初期,v和s可能过小而无法准确的估计g和g的平方。为此,Adam使用了Bias Correction:
在迭代初期t比较小,上式分母接近于0,相当于放大了v和s。在迭代后期,分母接近于1,偏差修正几乎不再有影响。
接下来,Adam使用偏差修正后的v和s,重新调整每个参数的学习速率:
最后,更新参数:
Adam算法调参的话,一般没人去管beta,大都是调整初始学习速率eta.
5. 算法选择
- 虽然有各种各样的优化算法改进,但是在论文中使用最多的还是SGD算法。一般来说SGD效果还是最好的
- Adam普适性强,效果好,速度也很快
- SGD在小数据集上效果一般要好一些
- 在稀疏数据集上可以尝试使用Momentum
最重要的一条:要根据实际情况来,多尝试几种优化算法,最重要的还是线上/线下的实验结果。
真state of the art!
6. 总结
上面东西有点多,公式有些乱。没看懂没关系,对照着看看下面主页君的总结。相信你一定能建立一些intuition。
主要从两个出发点来提出优化算法:
- 调整更新的步长。比如SGD是梯度g;Momentum是g的指数加权平均;NAG是改进的Momentum,利用之后的梯度信息,提前刹车;
- 调整学习速率,每个参数都有自己的学习速率。比如Adagrad使用梯度平方的累加和调整;RMSprop使用梯度平方的指数加权平均调整;Adadelta使用梯度平方的指数加权平均,再加上参数改变量平方的指数加权平均来调整;
目标:优化收敛速度
| 优化算法 | 备注 |
|---|---|
| SGD | 最朴素的优化算法,梯度直接作为改变量 |
| Momentum | 改进SGD: 使用梯度进行指数加权平均,作为新的改变量 |
| NAG | 改进Momentum: 先用上一个时刻的改变量近似得到下一时刻的位置,再使用该时刻的梯度进行指数加权平均,作为最终的改变量 |
目标:每个参数都有自己的学习率
| 优化算法 | 备注 |
|---|---|
| Adagrad | 使用梯度平方累加和,再开根号作为分母;初始eta为分子;来调整学习速率 |
| RMSprop | 改进Adagrad: 使用梯度平方的指数加权平均,再开根号作为分母;初始化eta为分子;来调整学习速率 |
| Adadelta | 改进Adagrad: 使用梯度平方的指数加权平均,再开根号作为分母;参数改变量平方的指数加权平均作为分子;来调整学习速率 |
目标:更普适的方法
| 优化算法 | 备注 |
|---|---|
| Adam | 综合Momentum和RMSprop,并使用Bias Correction来修正。Momentum用来确定更新步长,RMSprop用来调节学习速率 |
Reference
- 吴恩达人工智能课程
- 大佬的博客 .
- LUON 动手深度学习

时间:2018-08-20 00:33 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















