微软和谷歌分别开源分布式深度学习框架,各自

微软和谷歌一直在积极研究用于训练深度神经网络的新框架,并且在最近将各自的成果开源——微软的PipeDream和谷歌的GPipe。
原则上看,他们都遵循了类似的原则来训练深度学习模型。这两个项目已在各自的研究论文(PipeDream,GPipe)中进行了详细介绍,这篇文章将对此进行总结。
先放上GitHub开源地址
微软:
https://github.com/msr-fiddle/pipedream
谷歌:
https://github.com/tensorflow/lingvo/blob/master/lingvo/core/gpipe.py
众所周知,在实验过程中,虽然训练基本模型比较琐碎,但复杂度却随模型的质量和大小线性增加。例如,2014年ImageNet视觉识别挑战赛的冠军是GoogleNet,它通过400万个参数获得了74.8%的top1准确性,而仅仅三年之后,2017年ImageNet挑战赛的冠军就使用1.458亿个参数(多了36倍)的最新神经网络实现了top1准确率——82.7%。但是,在同一时期,GPU内存仅增加了约3倍。
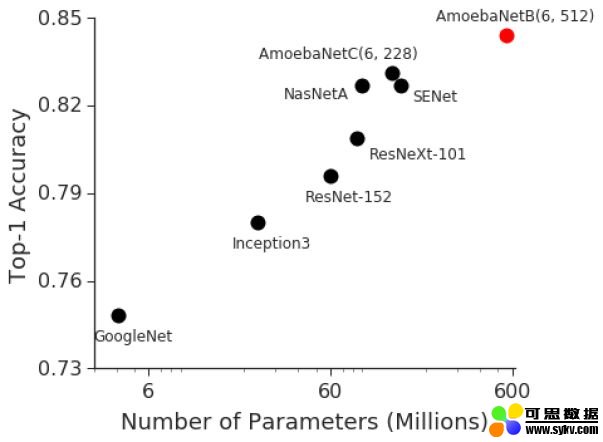
随着模型缩放以达到更高的准确性,对这些模型的训练变得越来越具有挑战性。前面的样本也显示了,依靠GPU基础结构的改进来实现更好的训练是不可持续的。我们需要分布式计算方法,这些方法可以并行化跨不同节点的训练工作量,以扩展训练规模。分布式训练的概念听起来很琐碎,但实际上却极其复杂。
谷歌的GPipe
GPipe专注于扩展深度学习计划的训练工作量。从基础架构的角度来看,训练过程的复杂性是深度学习模型经常被忽视的一个方面。训练数据集越来越大,越来越复杂。例如,在医疗保健领域,需要使用数百万个高分辨率图像进行训练的模型并不罕见。结果,训练过程通常要花费很长时间才能完成,并且内存和CPU消耗非常大。
思考深度学习模型的分布式的有效方法是将其划分为数据分布式和模型分布式。数据分布式方法采用大型机器集群,将输入数据拆分到它们之间。模型分布式尝试将模型移至具有特定硬件的加速器,例如GPU或TPU,以加速模型训练。
概念上看,几乎所有训练数据集都可以按照一定的逻辑进行分布式训练,但是关于模型的说法却不尽相同。例如,一些深度学习模型由可以独立训练的并行分支组成。在那种情况下,经典策略是将计算划分为多个分区,并将不同的分区分配给不同的分支。但是,这种策略在按顺序堆叠各层的深度学习模型中是不足的,
GPipe通过利用一种称为流水线的技术将数据和模型分布式结合在一起。从概念上讲,GPipe是一个分布式机器学习库,它使用同步随机梯度下降和流水线分布式进行训练,适用于由多个连续层组成的任何DNN。
GPipe在不同的加速器之间划分模型,并自动将一小批训练样本拆分为较小的微批。该模型允许GPipe的加速器并行运行,从而最大限度地提高了训练过程的可扩展性。
下图说明了具有连续层的神经网络的GPipe模型在四个加速器之间分配。Fk是第k个分区的复合正向计算函数。Bk是相应的反向传播函数。Bk取决于上层的Bk + 1和Fk的中间激活。在顶级模型中,我们可以看到网络的顺序性质如何导致资源利用不足。下图显示了GPipe方法,其中将输入的迷你批处理分为较小的宏批处理,这些宏批处理可由加速器同时处理。
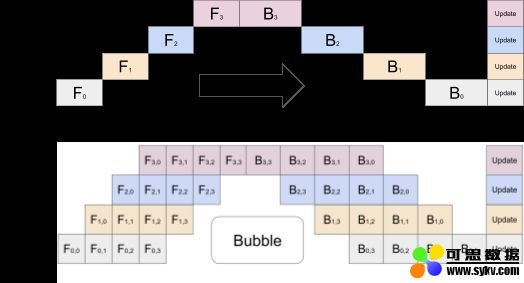
图片来源:
https://arxiv.org/pdf/1811.06965.pdf
微软的PipeDream
几个月前,微软研究院宣布创建Project Fiddle,这是一系列旨在简化分布式深度学习的研究项目。PipeDreams是Fiddle项目首次发布的版本之一,专注于深度学习模型训练的并行化。
PipeDream采用与其他方法不同的方法来利用称为管道分布式的技术来扩展深度学习模型的训练。这种方法试图解决数据和模型并行技术的一些挑战,例如GPipe中使用的技术。
通常,在云基础架构上进行训练时,数据并行方法在规模上会承受较高的通信成本,并且随着时间的推移会提高GPU计算速度。类似地,模型分布式技术通常在利用硬件资源上更加效率低下,程序员需要决定如何在给定硬件部署的情况下拆分其特定模型,给他们带来了不必要的负担。

图片来源:
http://www.microsoft.com/zh-cn/research/uploads/prod/2019/08/fiddle_pipedream_sosp19.pdf
PipeDream尝试通过使用称为管道分布式的技术来克服数据模型分布式方法的一些挑战。
从概念上讲,管道分布计算涉及将DNN模型的各层划分为多个阶段,其中每个阶段均由模型中的一组连续层组成。每个阶段都映射到一个单独的GPU,该GPU对该阶段中的所有层执行正向传递(和反向传递)。
给定一个特定的深度神经网络,PipeDream会基于在单个GPU上执行的简短概要分析,自动确定如何对DNN的运算符进行分区,在不同阶段之间平衡计算负载,同时最大程度地减少与目标平台的通信。即使存在模型多样性(计算和通信)和平台多样性(互连拓扑和分层带宽),PipeDream也会有效地实现负载平衡。PipeDream训练分布式的方法的原理比数据模型分布式方法具有多个优点。
对于初学者而言,PipeDream需要在工作程序节点之间进行较少的通信,因为管道执行中的每个工作程序仅需要将渐变的子集和输出激活信息传达给单个其他工作程序。
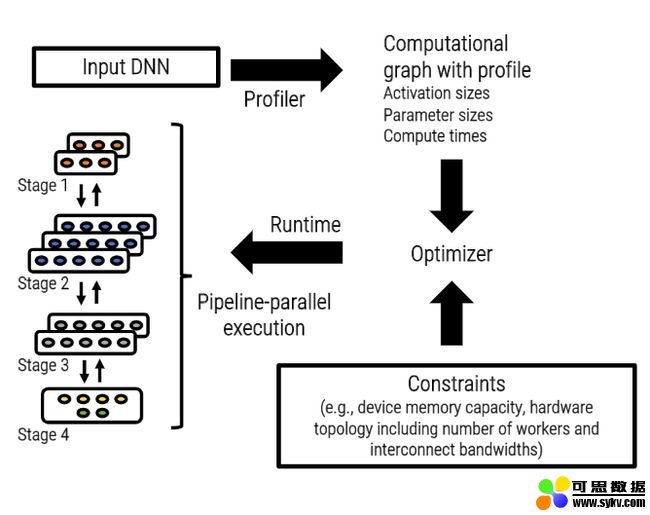
图片来源:
https ://www.microsoft.com/zh-cn/research/uploads/prod/2019/08/fiddle_pipedream_sosp19.pdf
训练分布式是构建更大、更准确的深度学习模型的关键挑战之一。分布式训练方法是深度学习社区中一个活跃的研究领域,需要将有效的并发编程技术与深度学习模型的本质相结合。尽管仍处于早期阶段,但Google的GPipe和Microsoft的PipeDream本身已经是很优秀的产品,它是深度学习开发人员可用的两种最具创造性的分布式训练方法。
素材来源:
https://medium.com/dataseries/microsoft-and-google-open-sourced-these-frameworks-based-on-their-work-scaling-deep-learning-c0510e907038
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn

时间:2020-12-13 19:14 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]AI已能求解微分方程,数学是这样一步步“沦陷”
- [机器学习]1.6万亿参数,秒杀GPT-3!谷歌推出超级语言模型
- [机器学习]MIT韩松团队开发全新微型深度学习技术MCUNet-符印
- [机器学习]谷歌最新模型pQRNN:效果接近BERT,参数量缩小3
- [机器学习]微软与OpenAI达成合作,获得GPT-3独家使用授权
- [机器学习]Dynamic ReLU:微软推出提点神器,可能是最好的R
- [机器学习]Dynamic ReLU:微软推出提点神器,可能是最好的R
- [机器学习]GPT-1 & 2: 预训练+微调带来的奇迹
- [机器学习]硬刚无限宽神经网络后,谷歌大脑有了12个新发现
- [机器学习]硬刚无限宽神经网络后,谷歌大脑有了12个新发现
相关推荐:
网友评论:















