谁说RL智能体只能在线训练?谷歌发布离线强化学习新范式
为了避免 distribution mismatch,强化学习的训练一定要在线与环境进行交互吗?谷歌的这项最新研究从优化角度,为我们提供了离线强化学习研究新思路,即鲁棒的 RL 算法在足够大且多样化的离线数据集中训练可产生高质量的行为。该论文的训练数据集与代码均已开源。机器之心友情提示,训练数据集共包含 60 个雅达利游戏环境,谷歌宣称其大小约为 ImageNet 的 60 x 3.5 倍。

「异策略学习的潜力依然很诱人,但实现它的最佳方式依然是个谜。」—Sutton & Barto(两人为《强化学习导论》一书的作者)
多数强化学习算法都假设一个智能体主动与在线环境交互,从它自己搜集的经验中学习。这些算法在现实问题中的应用困难重重,因为从现实世界中进一步搜集的数据可能样本效率极低,还会带来意想不到的行为。而那些在仿真环境中运行的算法需要高保真模拟器,因此构建起来非常困难。然而,对于许多现实世界中的强化学习应用来说,之前已经搜集了很多交互数据,可以用于训练在上述现实问题中可行的强化学习智能体,同时通过结合之前的丰富经验来提高泛化性能。
现有的交互数据可以实现离线强化学习的有效训练,后者是完全的异策略(off-policy)强化学习设置,智能体从一个固定的数据集中学习,不与环境进行交互。
离线强化学习有助于:
1)使用现有数据预训练一个强化学习智能体;
2)基于强化学习算法利用固定交互数据集的能力对他们进行实验评估;
3)对现实世界的问题产生影响。然而,由于在线交互与固定数据集中的交互数据分布不匹配,离线强化学习面临很大的挑战。即,如果一个经过训练的智能体采取了与数据收集智能体不同的行动,我们不知道提供什么样的奖励。
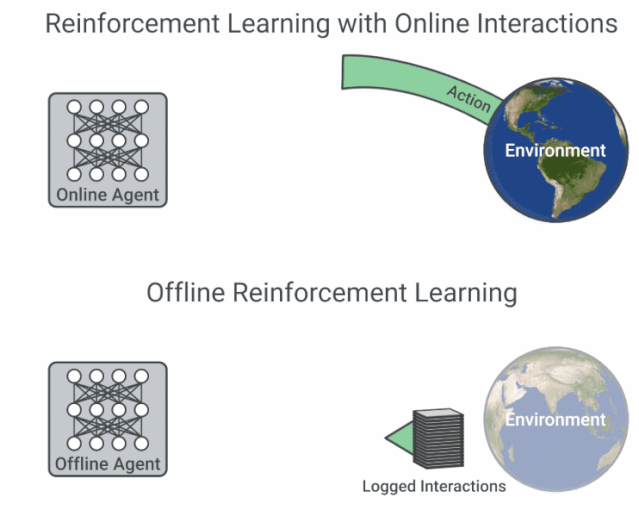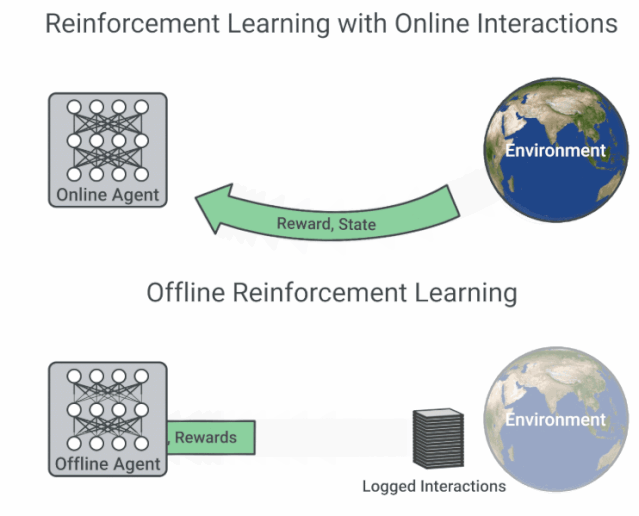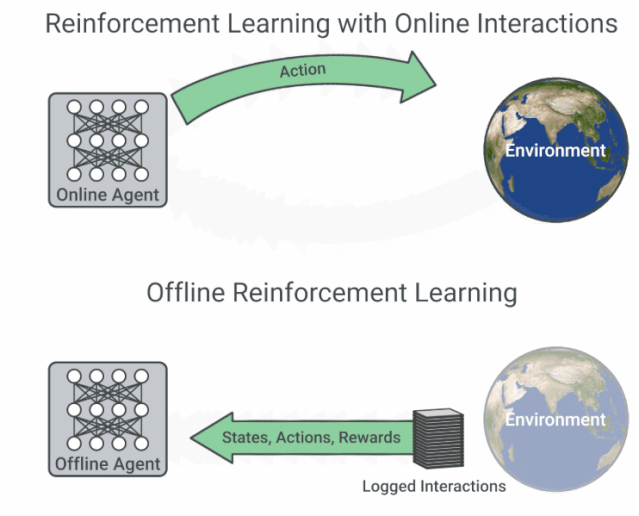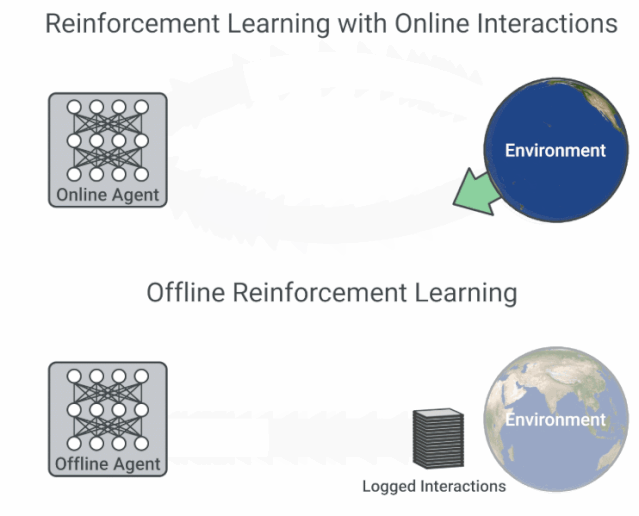
具有在线交互的 RL 与离线 RL 的流程图比较。
在这篇名为「An Optimistic Perspective on Offline Reinforcement Learning」的论文中,根据 DQN 智能体记录下的经验,谷歌大脑团队的研究者提出了一种在 Atari 2600 游戏中进行离线强化学习的简单实验设置。他们展示了不通过对任何错配分布的显式修正,仍然可能训练出性能超越使用标准异策略 RL 算法收集数据的智能体。同时,研究者还提出了一种鲁棒的 RL 算法,在离线 RL 中表现出可观的结果,称作随机混合集成(random ensemble mixture,REM)。
总的来说,研究者提出一种全新的优化角度,即鲁棒的 RL 算法在足够大且多样化的离线数据集中训练可产生高质量的行为,巩固了新兴的数据驱动 RL 范式。为促进离线 RL 方法的开发与评估,研究者公开了他们的 DQN 回溯数据集并开源了论文的代码。
- 论文链接:https://arxiv.org/pdf/1907.04543.pdf
- 项目地址:https://github.com/google-research/batch_rl
异策略与离线强化学习基础
不同 RL 算法汇总如下:

在线的异策略 RL 智能体(如 DQN),仅通过接收来自游戏屏幕的图像信息,不需要其他任何关于此游戏的知识,在 Atari 2600 游戏中取得了与人类玩家同等的表现。在一个给定的环境状态下,DQN 根据如何最大化未来奖励(如 Q-values),对动作的有效性进行估计。
此外,当前使用价值函数分布的 RL 算法(如 QR-DQN)对所有可能的未来奖励的分布进行估计,而不是为每个状态-动作对估计单一的期望价值。DQN 与 QR-DQN 这样的智能体被看作是「在线」的算法,这是因为它们在优化策略与使用优化后的策略去收集更多数据之间不断交替迭代。
理论上异策略的 RL 智能体可以从任意策略收集的数据中进行学习,而不仅限于被优化的那个策略。然而,最近的研究工作显示,标准的异策略智能体在离线 RL 设定下将会发散或性能表现较差。为解决以上问题,之前的研究提出了一种正则化学习到的策略的方法,来使其策略更新在离线交互数据集附近。
为离线 RL 设计的 DQN 回溯数据集
研究者首先建立了 DQN 回溯数据集来重新审视离线 RL。该数据集使用 DQN 智能体在 60 个 Atari 2600 游戏中各训练两亿步得到,并使用了粘滞动作(sticky action)来使问题更具挑战性,即有 25% 的概率执行智能体之前的动作,而不是当前的动作。
在这 60 个游戏中,对于每一个游戏,研究者训练 5 个具有不同初始化参数的 DQN 智能体,并将训练中产生的所有 (state, action, reward, next state) 元组储存在 5 个回溯数据集中,总共产生 300 个数据集。
这个 DQN 回溯数据集之后被用于训练离线 RL 智能体,训练过程中并不需要任何与环境的交互。每一个游戏回溯数据集大约是 ImageNet 的 3.5 倍,包含在优化在线 DQN 时中间策略产生的所有样本。

在 Atari 游戏中使用 DQN 回溯数据集的离线 RL。
在 DQN 回溯数据集上训练离线智能体
研究者在 DQN 回溯数据集上对 DQN 和值函数分布 QR-DQN 的变体进行训练。尽管离线数据集包含了 DQN 智能体经历过的数据,并且这些数据会随着训练进程的推移而相应地改善,研究者对离线智能体和训练后得到的 best-performing 在线 DQN 智能体(即完全训练好的 DQN)的性能进行了比较。对于每一次游戏,他们使用在线 returns 对训练的 5 个离线智能体展开了评估,并得出了最佳的平均性能。
除了在少数游戏中相同数据量下得分高于完全训练(fully-trained)的在线 DQN 之外,离线 DQN 的表现均弱于后者。另一方面,离线 QR-DQN 在大多数 game 中的表现优于离线 DQN 和完全训练的 DQN。这些结果表明,利用标准深度 RL 算法来优化强大的离线智能体是可能实现的。并且,离线 QR-DQN 和 DQN 的表现差距表明它们利用离线数据的能力也存在着差异。
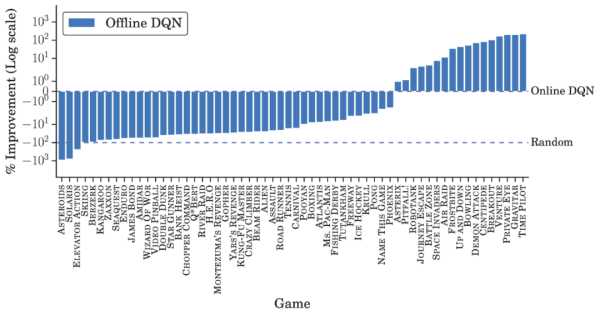
离线 DQN 结果。
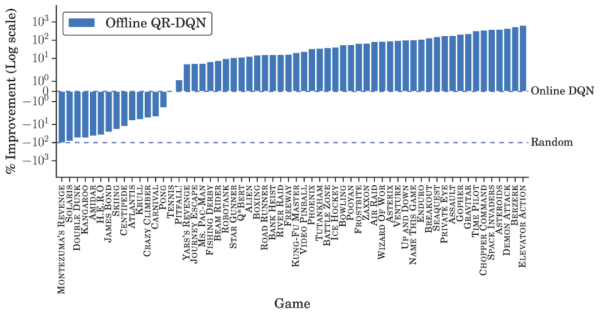
离线 QR-DQN 结果。
两种鲁棒的离线 RL 智能体
在在线 RL 中,一个智能体选择它认为会带来高奖励(high reward)的动作,然后会接收纠错性反馈(corrective feedback)。此外,由于在离线 RL 中无法收集额外数据(additional data),所以有必要使用一个固定的数据集来推理出泛化能力。借助于使用模型集成来提升泛化能力的监督学习方法,研究者提出了以下两个新的离线 RL 智能体:
- 集成 DQN 是 DQN 的一个简单扩展,它训练多个 Q 值估计并取平均值来进行评估;
- 随机集成混合(Random Ensemble Mixture,REM)是一个易于实现的 DQN 扩展,它受到了 Dropout 的启发。REM 的核心理念是,如果可以得到 Q 值的多个估计,则 Q 值估计的加权组合(weighted combination)也成为 Q 值的一个估计。因此,REM 在每次迭代中随机组合多个 Q 值估计,并将这种随机组合用于鲁棒训练。
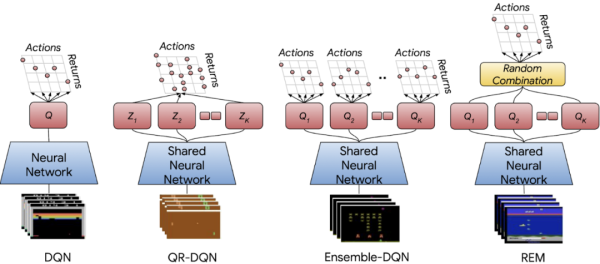
DQN、值函数分布 QR-DQN、具有相同多头机制 QR-DQN 架构的期望 RL 变体、集成 DQN 和 REM 的神经网络架构。
为了更高效地利用 DQN 回溯数据集,研究者在训练离线智能体时将训练迭代次数设置为在线 DQN 训练的 5 倍,性能表现如下图所示。离线 REM 要优于离线 DQN 和离线 QR-DQN。并且,与一个强大的值函数分布智能体,即完全训练的在线 C51 的性能比较表明,从离线 REM 获得的增益要高于 C51。
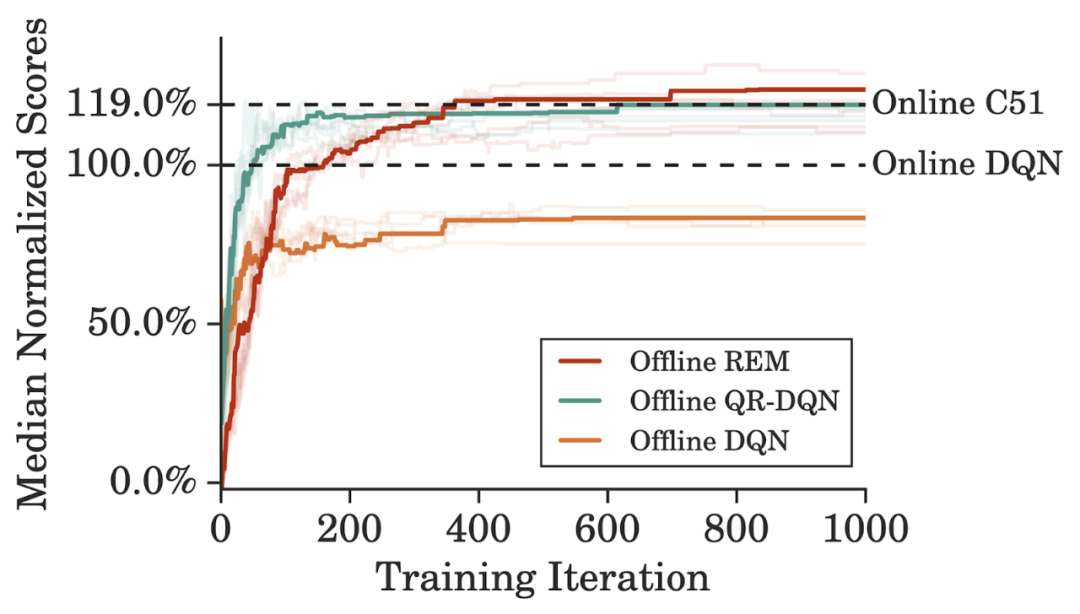
离线 REM 与基线方法的性能比较。
在 Atari 游戏中使用标准训练方案时,在线 REM 在标准在线 RL 设置下的性能能够与 QR-DQN 媲美。这表明我们可以利用从 DQN 回溯数据集和离线 RL 设置中获得的 insight 来构建有效的在线 RL 方法。
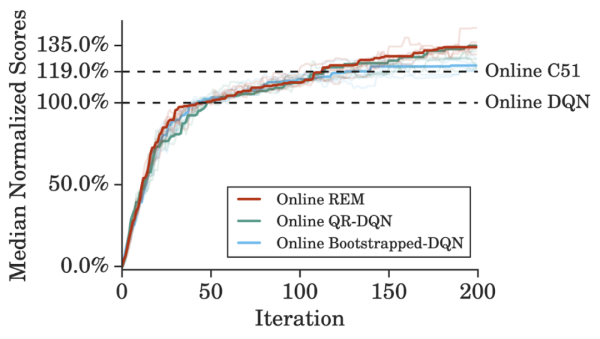
在线 REM 与基线方法的性能比较。
结果对比:离线强化学习中的重要因素
为什么之前的标准强化学习智能体在离线设置下屡屡失败?谷歌研究者总结了他们的研究与之前研究的几个重要差异:
- 离线数据集大小。谷歌训练离线 QR-DQN 和 REM 所用的数据集是通过随机下采样整个 DQN 回溯数据集得到的简化数据,同时保持了相同的数据分布。与监督学习类似,模型性能随着数据集大小的增加而提升。REM 和 QR-DQN 只用整个数据集的 10% 就达到了与完全的 DQN 接近的性能;
- 离线数据集的组成。研究者在 DQN 回溯数据集每个游戏的前 2000 万帧上训练了离线强化学习智能体。离线 REM 和 QR-DQN 在这个低质量数据集上的表现优于最佳策略(best policy),这表明如果数据集足够多样,标准强化学习智能体也能在离线设置下表现良好;
- 离线算法的选择。有人认为,在离线状态下训练时,标准异策略智能体在连续控制任务中会表现不佳。然而,谷歌研究者发现,最近的连续控制智能体(如 TD3)在大型、多样化离线数据集上训练时,其性能与复杂离线智能体相当。
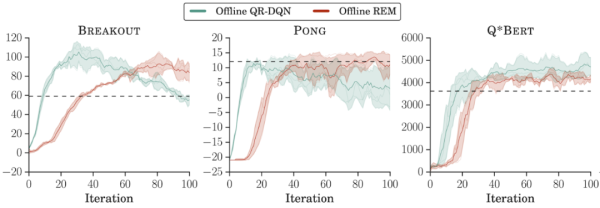
用较低质量数据集在离线设置下训练强化学习智能体。
展望
谷歌的这项研究表明,在从大量不同策略的离线数据中学习时,需要对神经网络泛化的作用进行严格描述。另一个重要的方向是通过对 DQN 回溯数据集进行下采样,利用各种数据收集策略对离线 RL 进行基准测试。
谷歌研究者目前采用的是在线策略评估,然而「真正的」离线 RL 需要离线策略评估来进行超参数调优和早停。最后,基于模型的 RL 和自监督学习方法也有望用于离线 RL。

时间:2020-04-16 22:36 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]世界最大、最复杂的GPU!这颗集成1000亿个晶体管
- [机器学习]“狂欢”的半导体设备
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]全球半导体设备“大乱斗”
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
- [机器学习]红杉树智能英语在线教育培养孩子学习兴趣,提
- [机器学习]私塾家亮相GET2020教育科技大会,以AI智能重构智慧
- [机器学习]神经科学如何影响人工智能?看DeepMind在NeurIPS2
相关推荐:
网友评论:















