华为开源只用加法的神经网络:实习生领衔打造,效果不输传统CNN
没有乘法的神经网络,你敢想象吗?无论是单个神经元的运算还是卷积运算,都不可避免地要使用乘法。
然而乘法对硬件资源的消耗远大于加法。如果不用乘法,全部改用加法应该可以让运算速度大大提升。
去年年底,来自北京大学、华为诺亚方舟实验室、鹏城实验室的研究人员将这一想法付诸实践,他们提出了一种只用加法的神经网络AdderNet(加法器网络)。一作是华为诺亚方舟实习生,正在北大读博三。

如今,这篇文章已经被CVPR 2020收录(Oral),官方也在GitHub上开放了源代码。有兴趣的同学不妨前往一试究竟。
加法器网络简介
加法器网络的核心在于:用L1距离代替欧氏距离。
L1距离是求两点之间坐标差值的绝对值之和,因此全程不涉及乘法。
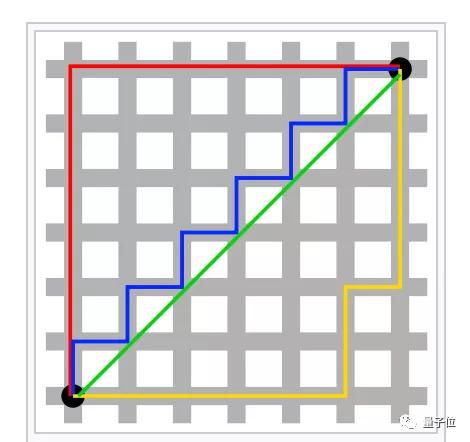
在这种新的定义下,反向传播中用到的求偏导数运算也变成了求减法。梯度下降的优化过程也被叫做符号SGD(signSGD)。
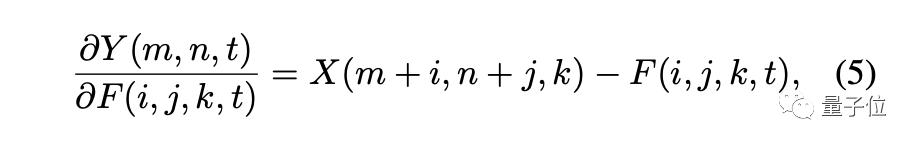
在加法器网络的新定义下,特征向量的空间分布也和CNN有很大的不同。
那么AdderNet的实际效果如何呢?
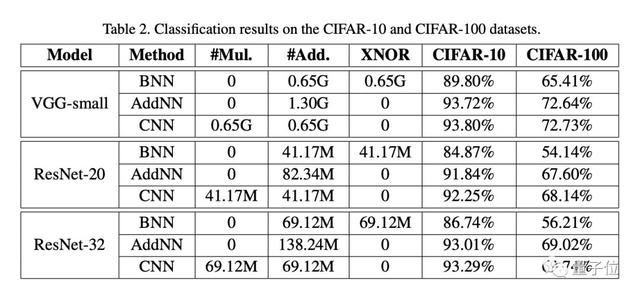
在CIFAR-10的图像分类任务中,AdderNet相比当初Bengio等人提出的加法神经网络BNN性能有大幅提升,并且已经接近了传统CNN的结果。
开源代码
官方的AdderNet基于Python3和PyTorch。
先按照PyTorch的官方文档准备ImageNet数据集,运行程序评估它在验证集上的效果:
- python test.py —data_dir 'path/to/imagenet_root/'
AdderNet可以在ImageNet数据集上达到74.9%的Top-1准确度和91.7%的Top-5准确度。
或者将CIFAR-10数据集下载到本地,测试一下它在CIFAR-10上的效果
- python test.py —dataset cifar10 —model_dir models/ResNet20-AdderNet.pth —data_dir 'path/to/cifar10_root/'
不过AdderNet仍需自己训练,官方表示将很快发布预训练模型。
现阶段的AdderNet并非没有缺陷,作者在项目主页中说,由于AdderNet是用加法过滤器实现的,因此推理速度较慢,需要用CUDA编写才能提高速度。
这与作者希望提高神经网络运算速度的初衷还有一段距离。
但这篇论文的作者表示,今后还会继续加法器神经网络的研究,发表更多的成果,让我们一起期待这项研究取得新的进展吧。
华为诺亚实验室实习生领衔打造
AdderNet这篇文章的一作名叫陈汉亭,毕业于同济大学数学系,现在在北京大学信息科学技术学院攻读博士学位,同时在华为诺亚方舟实验室实习。
在硕博连读的前三年中,他已经以一作身份发表了5篇论文,其中一篇《Data-Free Learning of Student Networks》被ICCV 2019收录,另外它参与多篇论文还被NeurIPS、IJCAI、ICML等顶会收录。
传送门
源代码:https://github.com/huawei-noah/AdderNet
论文地址:https://arxiv.org/abs/1912.13200

时间:2020-04-13 18:35 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]微软和谷歌分别开源分布式深度学习框架,各自
- [机器学习]阿里开源3D-FUTURE数据集 建模时间可从3小时降至10秒
- [机器学习]华为要进军光刻机?
- [机器学习]港中文-商汤OpenMMLab开源全景图!
- [机器学习]Uber正式开源分布式机器学习平台:Fiber
- [机器学习]Facebook 开源聊天机器人Blender,经94 亿个参数强化
- [机器学习]Manning大神牵头,斯坦福开源Python版NLP库Stanza:涵
- [机器学习]搞定千亿参数,训练时间只用1/3,微软全新工具
- [机器学习]发布 TensorFlow Quantum:用于量子机器学习的开源库
- [机器学习]这个开源项目用Pytorch实现了17种强化学习算法
相关推荐:
网友评论:















