2020年深度学习优秀GPU一览,看看哪一款最适合你

深度学习模型越来越强大的同时,也占用了更多的内存空间,但是许多GPU却并没有足够的VRAM来训练它们。
那么如果你准备进入深度学习,什么样的GPU才是最合适的呢?下面列出了一些适合进行深度学习模型训练的GPU,并将它们进行了横向比较,一起来看看吧!
太长不看版
截至2020年2月,以下GPU可以训练所有当今语言和图像模型:
- RTX 8000:48GB VRAM,约5500美元
- RTX 6000:24GB VRAM,约4000美元
- Titan RTX:24GB VRAM,约2500美元
以下GPU可以训练大多数(但不是全部)模型:
- RTX 2080 Ti:11GB VRAM,约1150美元
- GTX 1080 Ti:11GB VRAM,返厂翻新机约800美元
- RTX 2080:8GB VRAM,约720美元
- RTX 2070:8GB VRAM,约500美元
以下GPU不适合用于训练现在模型:
- RTX 2060:6GB VRAM,约359美元。
在这个GPU上进行训练需要相对较小的batch size,模型的分布近似会受到影响,从而模型精度可能会较低。
图像模型
内存不足之前的最大批处理大小:
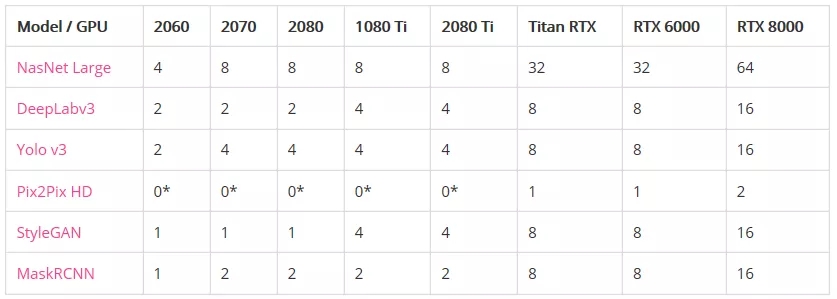
*表示GPU没有足够的内存来运行模型。
性能(以每秒处理的图像为单位):
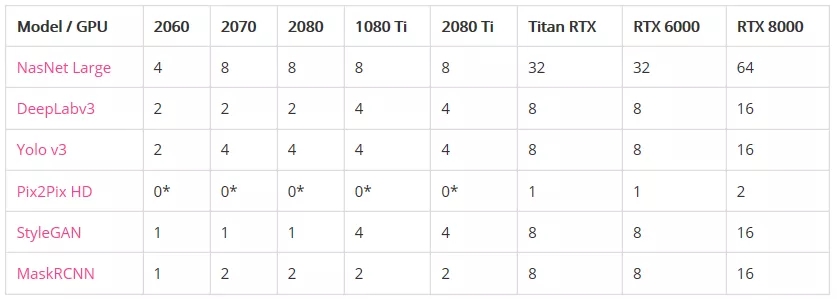
*表示GPU没有足够的内存来运行模型。
语言模型
内存不足之前的最大批处理大小:
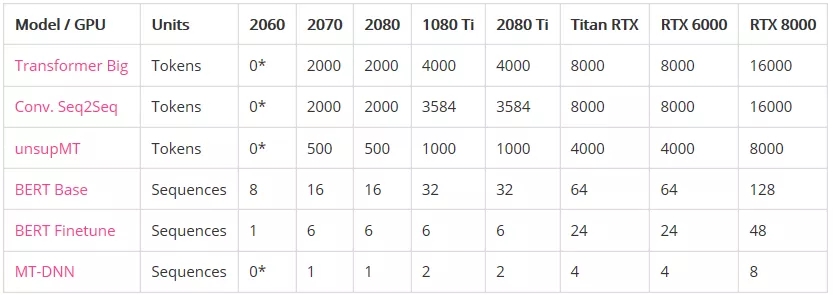
*表示GPU没有足够的内存来运行模型。
性能:
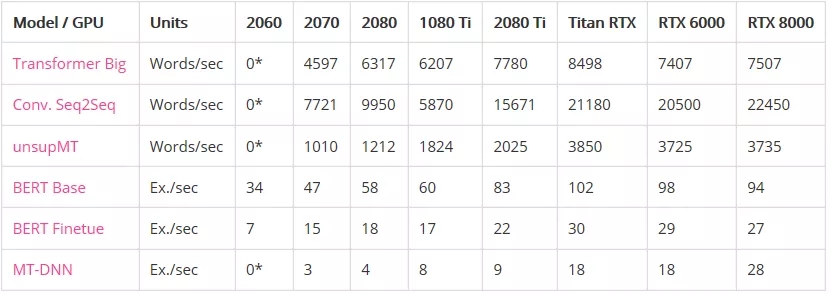
* GPU没有足够的内存来运行模型。
使用Quadro RTX 8000结果进行标准化后的表现
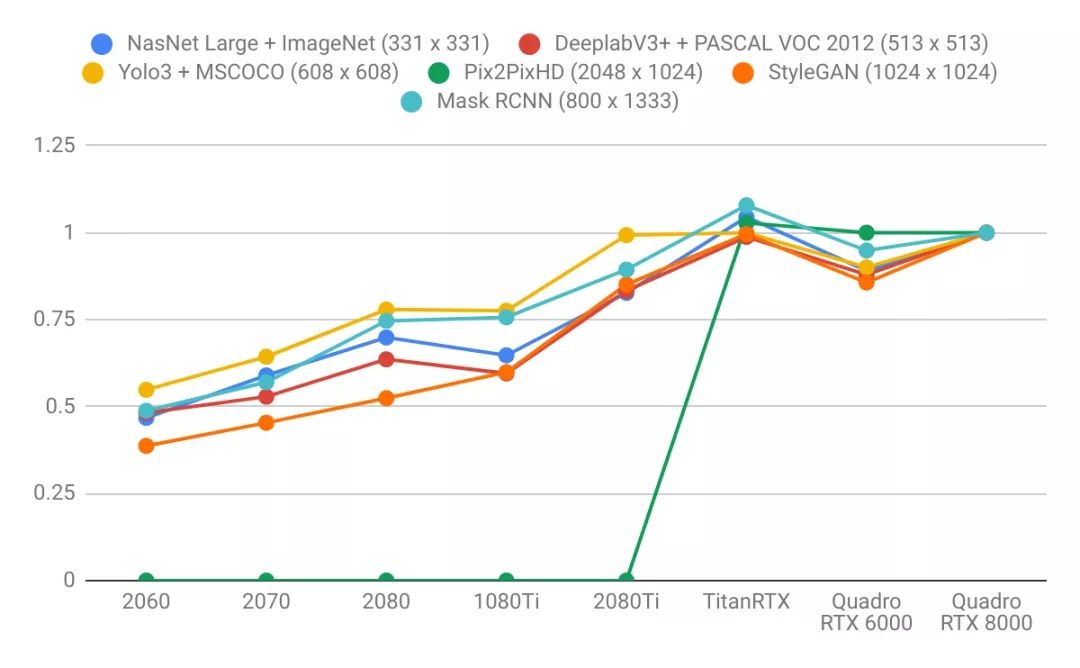
图像模型:
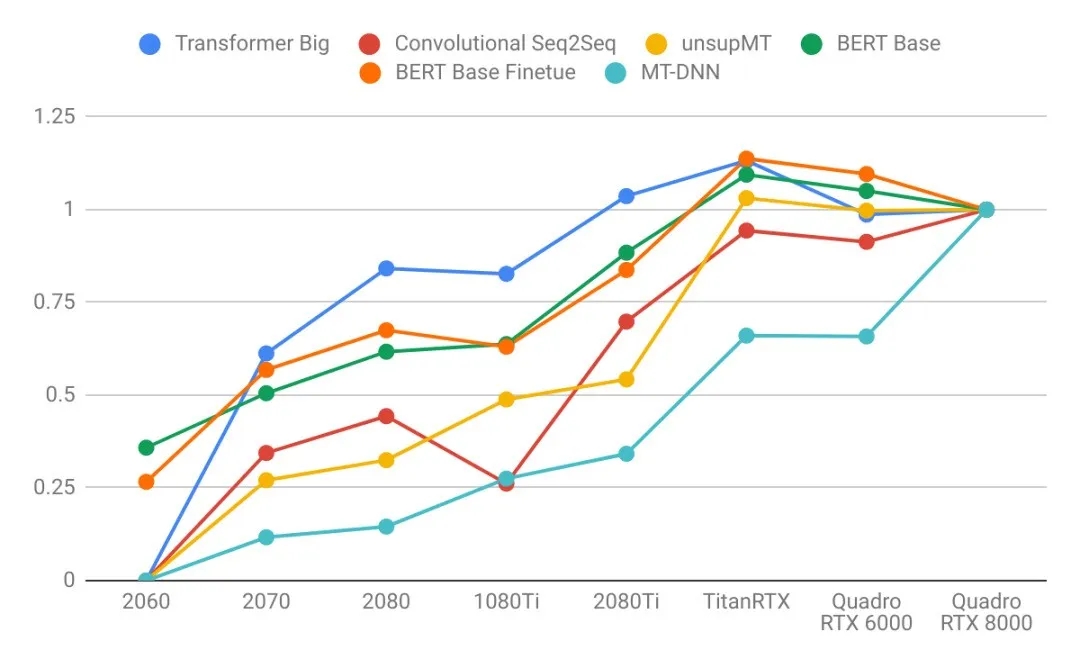
语言模型
结论
- 语言模型比图像模型受益于更大的GPU内存。注意右图的曲线比左图更陡。这表明语言模型受内存大小限制更大,而图像模型受计算力限制更大。
- 具有较大VRAM的GPU具有更好的性能,因为使用较大的批处理大小有助于使CUDA内核饱和。
- 具有更高VRAM的GPU可按比例实现更大的批处理大小。只懂小学数学的人都知道这很合理:拥有24 GB VRAM的GPU可以比具有8 GB VRAM的GPU容纳3倍大的批次。
- 比起其他模型来说,长序列语言模型不成比例地占用大量的内存,因为注意力(attention)是序列长度的二次项。
GPU购买建议
- RTX 2060(6 GB):你想在业余时间探索深度学习。
- RTX 2070或2080(8 GB):你在认真研究深度学习,但GPU预算只有600-800美元。8 GB的VRAM适用于大多数模型。
- RTX 2080 Ti(11 GB):你在认真研究深度学习并且您的GPU预算约为1,200美元。RTX 2080 Ti比RTX 2080快大约40%。
- Titan RTX和Quadro RTX 6000(24 GB):你正在广泛使用现代模型,但却没有足够买下RTX 8000的预算。
- Quadro RTX 8000(48 GB):你要么是想投资未来,要么是在研究2020年最新最酷炫的模型。
附注
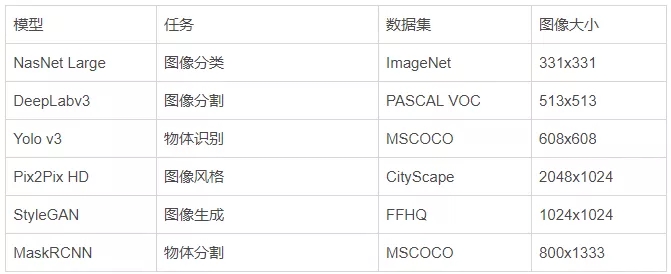
图像模型:
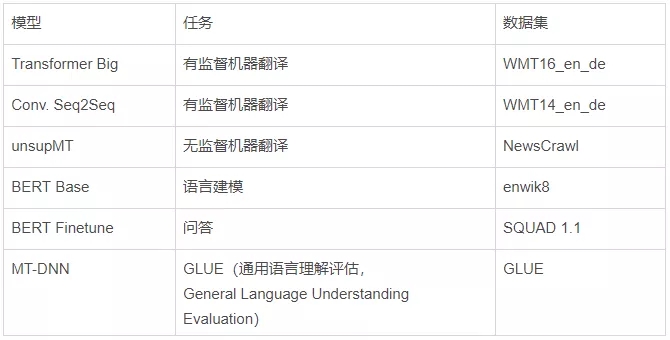
语言模型:
相关报道:https://lambdalabs.com/blog/choosing-a-gpu-for-deep-learning/

时间:2020-04-01 14:14 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
- [机器学习]一文详解深度学习最常用的 10 个激活函数
- [机器学习]增量学习(Incremental Learning)小综述
- [机器学习]盘点近期大热对比学习模型:MoCo/SimCLR/BYOL/SimSi
- [机器学习]深度学习中的3个秘密:集成、知识蒸馏和蒸馏
- [机器学习]【模型压缩】深度卷积网络的剪枝和加速
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]深度学习三大谜团:集成、知识蒸馏和自蒸馏
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]ASML真的那么强大吗?
相关推荐:
网友评论:















