机器学习在马蜂窝酒店聚合中的应用初探
出门旅行,订酒店是必不可少的一个环节。住得干净、舒心对于每个出门在外的人来说都非常重要。
在线预订酒店让这件事更加方便。当用户在马蜂窝打开一家选中的酒店时,不同供应商提供的预订信息会形成一个聚合列表准确地展示给用户。这样做首先避免同样的信息多次展示给用户影响体验,更重要的是帮助用户进行全网酒店实时比价,快速找到性价比最高的供应商,完成消费决策。
酒店聚合能力的强弱,决定着用户预订酒店时可选价格的「厚度」,进而影响用户个性化、多元化的预订体验。为了使酒店聚合更加实时、准确、高效,现在马蜂窝酒店业务中近 80% 的聚合任务都是由机器自动完成。本文将详细阐述酒店聚合是什么,以及时下热门的机器学习技术在酒店聚合中是如何应用的。
Part.1 应用场景和挑战
1. 酒店聚合的应用场景
马蜂窝酒旅平台接入了大量的供应商,不同供应商会提供很多相同的酒店,但对同一酒店的描述可能会存在差异,比如:
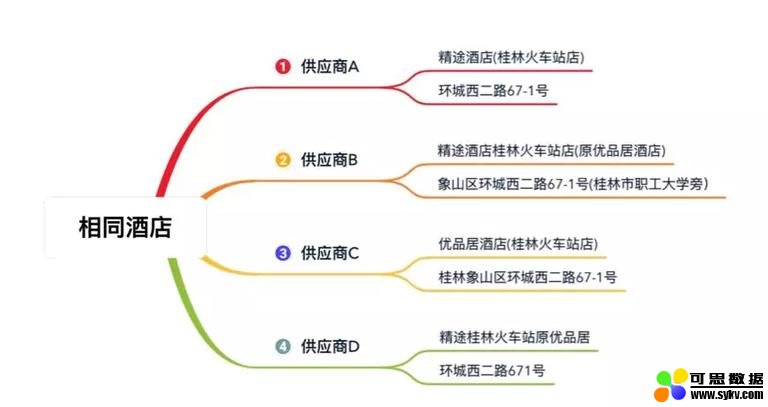
酒店聚合要做的,就是将这些来自不同供应商的酒店信息聚合在一起集中展示给用户,为用户提供一站式实时比价预订服务:
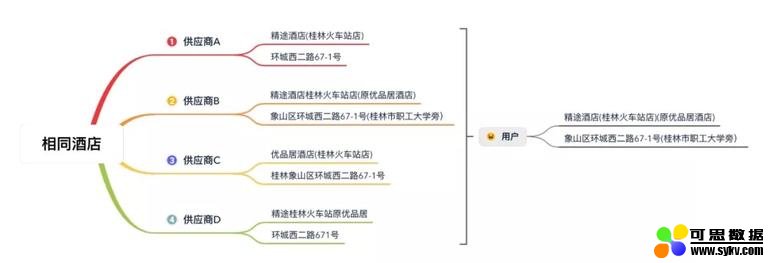
下图为马蜂窝对不同供应商的酒店进行聚合后的展示,不同供应商的报价一目了然,用户进行消费决策更加高效、便捷。
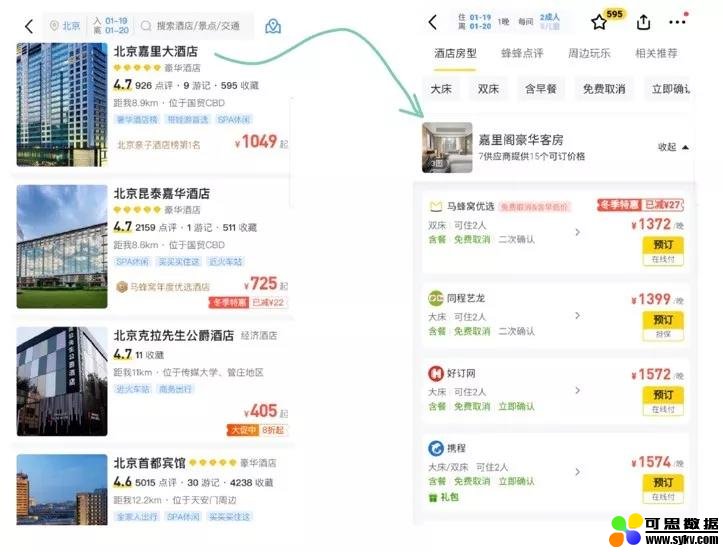
2. 挑战
(1) 准确性
上文说过,不同供应商对于同一酒店的描述可能存在偏差。如果聚合出现错误,就会导致用户在 App 中看到的酒店不是实际想要预订的:
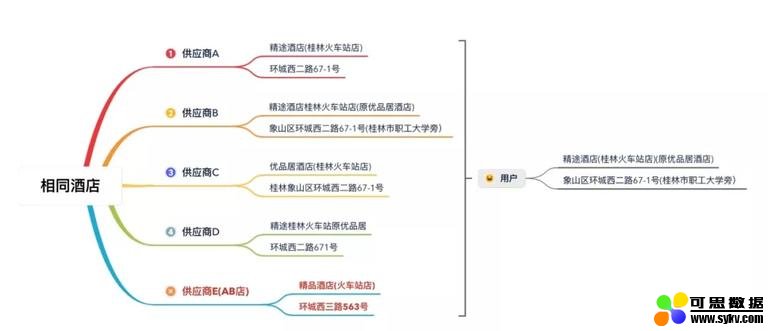
在上图中,用户在 App 中希望打开的是「精途酒店」,但系统可能为用户订到了供应商 E 提供的「精品酒店」,对于这类聚合错误的酒店我们称之为 「AB 店」。可以想象,当到店后却发现没有订单,这无疑会给用户体验造成灾难性的影响。
(2) 实时性
解决上述问题,最直接的方式就是全部采取人工聚合。人工聚合可以保证高准确率,在供应商和酒店数据量还不是那么大的时候是可行的。
但马蜂窝对接的是全网供应商的酒店资源。采用人工的方式聚合处理得会非常慢,一来会造成一些酒店资源没有聚合,无法为用户展示丰富的预订信息;二是如果价格出现波动,无法为用户及时提供当前报价。而且还会耗费大量的人力资源。
酒店聚合的重要性显而易见。但随着业务的发展,接入的酒店数据快速增长,越来越多的技术难点和挑战接踵而来。
Part.2 初期方案:余弦相似度算法
初期我们基于余弦相似度算法进行酒店聚合处理,以期降低人工成本,提高聚合效率。
通常情况下,有了名称、地址、坐标这些信息,我们就能对一家酒店进行唯一确定。当然,最容易想到的技术方案就是通过比对两家酒店的名称、地址、距离来判断是否相同。
基于以上分析,我们初版技术方案的聚合流程为:
-
输入待聚合酒店 A;
-
ES 搜索与 A 酒店相距 5km 范围内相似度最高的 N 家线上酒店;
-
N 家酒店与 A 酒店分别开始进行两两比对;
-
酒店两两计算整体名称余弦相似度、整体地址余弦相似度、距离;
-
通过人工制定相似度、距离的阈值来得出酒店是否相同的结论。
整体流程示意图如下:
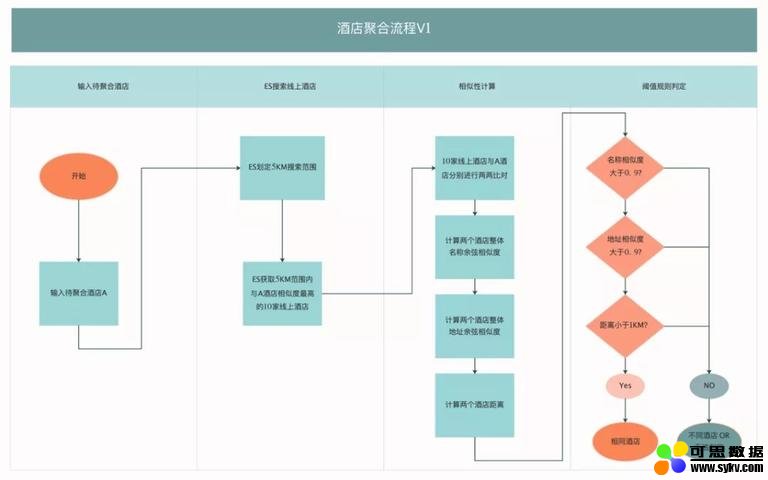
「酒店聚合流程 V1」上线后,我们验证了这个方案是可行的。它最大的优点就是简单,技术实现、维护成本很低,同时机器也能自动处理部分酒店聚合任务,相比完全人工处理更加高效及时。
但也正是因为这个方案太简单了,问题也同样明显,我们来看下面的例子 (图中数据虚构,仅为方便举例):
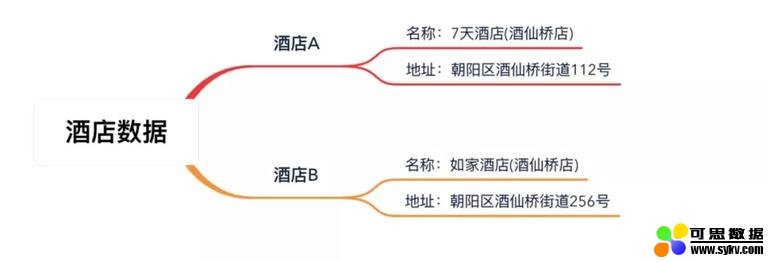
相信我们每个人都可以很快判断出这是两家不同的酒店。但是当机器进行整体的相似度计算时,得到的数值并不低:
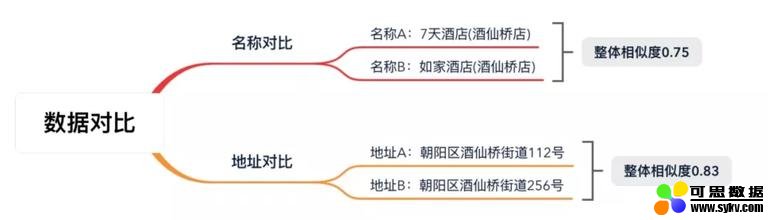
为了降低误差率,我们需要将相似度比对的阈值提升至一个较高的指标范围内,因此大量的相似酒店都不会自动聚合,仍需要人工处理。
最后,此版方案机器能自动处理的部分只占到约 30%,剩余 70% 仍需要人工处理;且机器自动聚合准确率约为 95%,也就是有 5% 的概率会产生 AB 店,用户到店无单,入住体验非常不好。
于是,伴随着机器学习的兴起,我们开始了将机器学习技术应用于酒店聚合中的探索之旅,来解决实时性和准确性这对矛盾。
Part.3 机器学习在酒店聚合中的应用
下面我将结合酒店聚合业务场景,分别从机器学习中的分词处理、特征构建、算法选择、模型训练迭代、模型效果来一一介绍。
3.1 分词处理
之前的方案通过比对「整体名称、地址」获取相似度,粒度太粗。
分词是指对酒店名称、地址等进行文本切割,将整体的字符串分为结构化的数据,目的是解决名称、地址整体比对粒度太粗的问题,同时也为后面构建特征向量做准备。
3.1.1 分词词典
在聊具体的名称、地址分词之前,我们先来聊一下分词词典的构建。现有分词技术一般都基于词典进行分词,词典是否丰富、准确,往往决定了分词结果的好坏。
在对酒店的名称分词时,我们需要使用到酒店品牌、酒店类型词典,如果纯靠人工维护的话,需要耗费大量的人力,且效率较低,很难维护出一套丰富的词典。
在这里我们使用统计的思想,采用机器 + 人工的方式来快速维护分词词典:
-
随机选取 100000+ 酒店,获取其名称数据;
-
对名称从后往前、从前往后依次逐级切割;
-
每一次切割获取切割词且切割词的出现频率 +1;
-
出现频率较高的词,往往就是酒店品牌词或类型词。
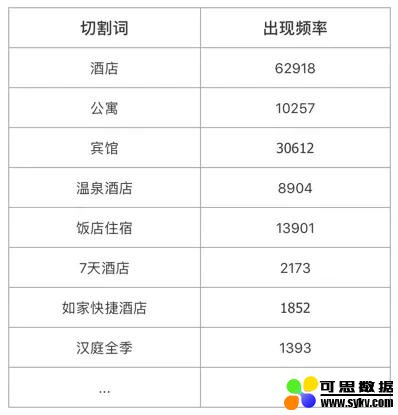
上表中示意的是出现频率较高的词,得到这些词后再经过人工简单筛查,很快就能构建出酒店品牌、酒店类型的分词词典。
3.1.2 名称分词
想象一下人是如何比对两家酒店名称的?比如:
-
A:7 天酒店 (酒仙桥店)
-
B:如家酒店 (望京店)
首先,因为经验知识的存在,人会不自觉地进行「先分词后对比」的判断过程,即:
-
7 天—> 如家
-
酒店—> 酒店
-
酒仙桥店—> 望京店
所以要想对比准确,我们得按照人的思维进行分词。经过对大量酒店名称进行人工模拟分词,我们对酒店名称分为如下结构化字段:
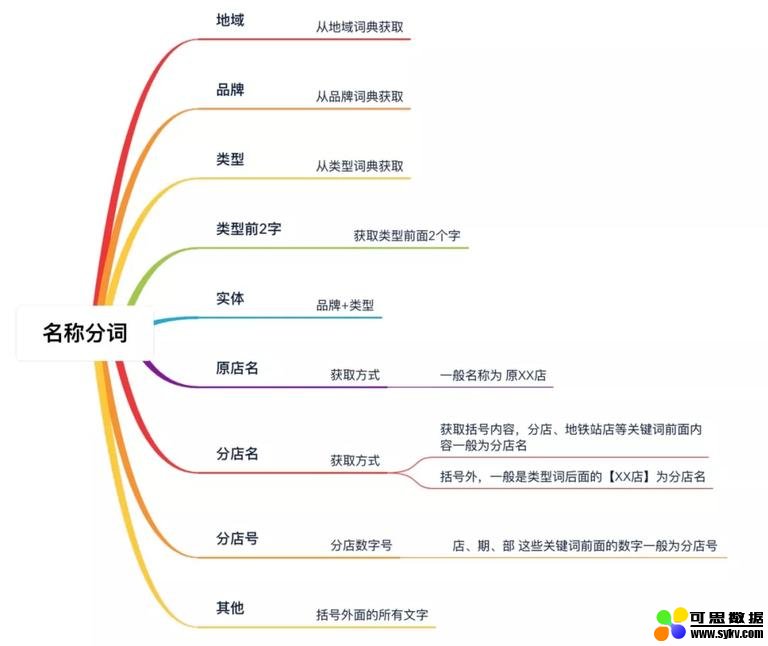
着重说下「类型前 2 字」这个字段。假如我们需要对如下 2 家酒店名称进行分词:
-
酒店 1:龙门南昆山碧桂园紫来龙庭温泉度假别墅
-
酒店 2:龙门南昆山碧桂园瀚名居温泉度假别墅
分词效果如下:
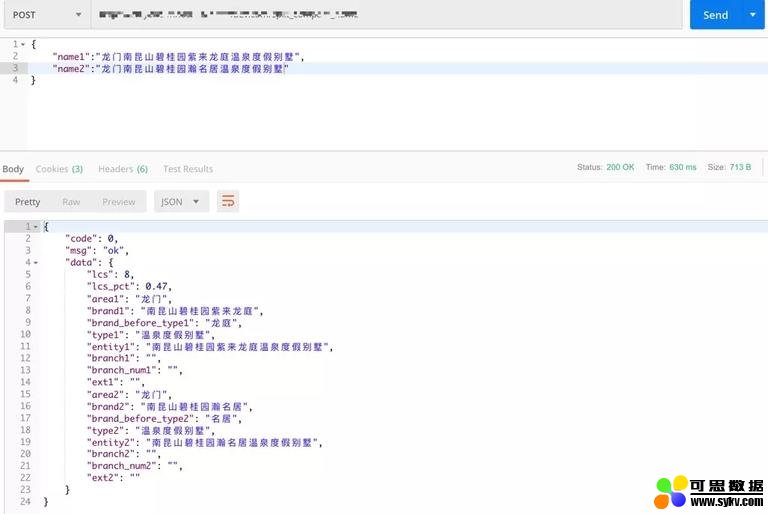
我们看到分词后各个字段相似度都很高。但类型前 2 字分别为:
-
酒店 1 类型前 2 字:龙庭
-
酒店 2 类型前 2 字:名居
这种情况下此字段 (类型前 2 字) 具有极高的区分度,因此可以作为一个很高效的对比特征。
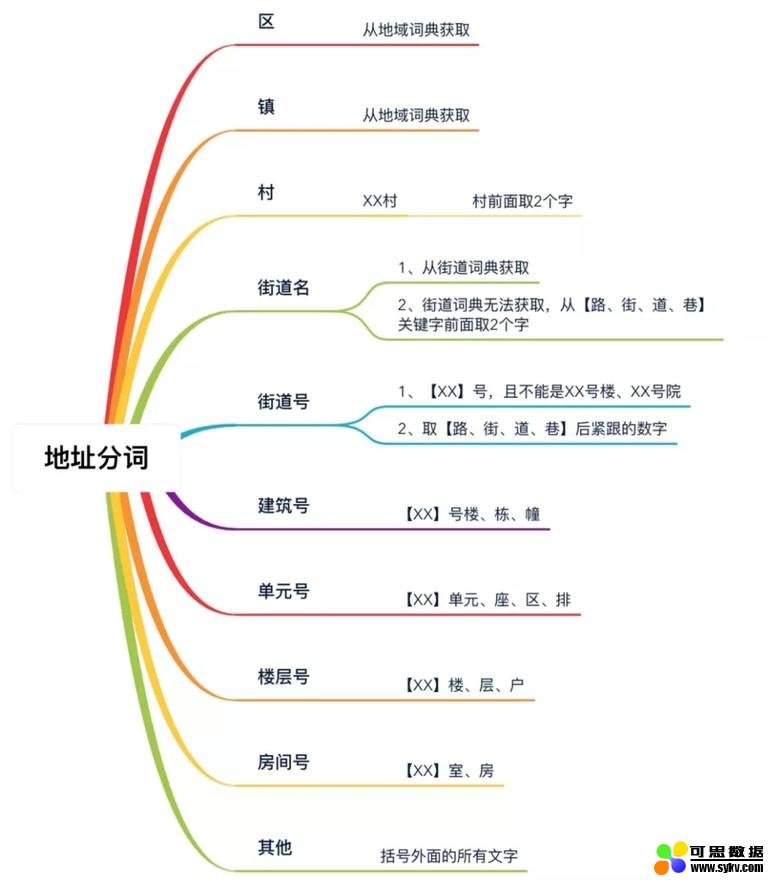
3.1.3 地址分词
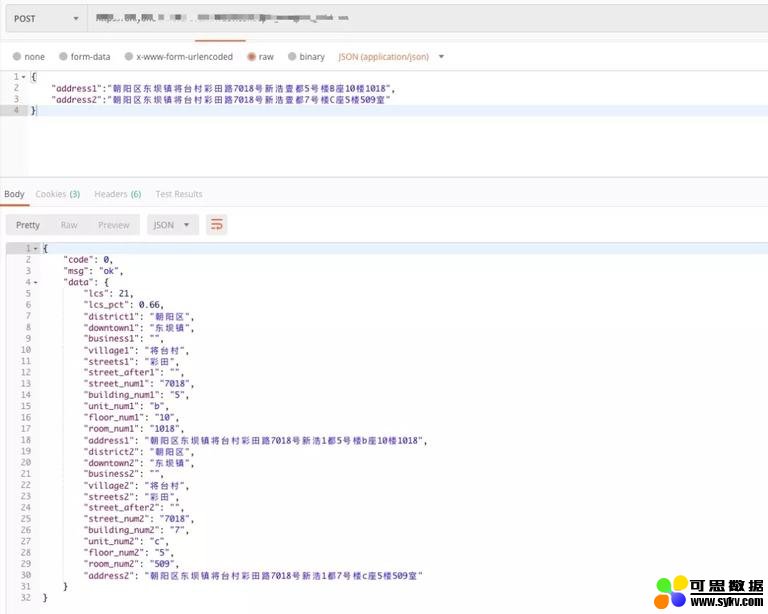
同样,模拟人的思维进行地址分词,使之地址的比对粒度更细更具体。具体分词方式见下图:
下面是具体的分词效果展示如下:
小结
分词解决了对比粒度太粗的缺点,现在我们大约有了 20 个对比维度。但对比规则、阈值怎么确定呢?
- 本文地址:http://www.6aiq.com/article/1579175994783
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
- 知乎专栏 点击关注
人工制定规则、阈值存在很多缺点,比如:
-
规则多变。20 个对比维度进行组合会出现 N 个规则,人工不可能全部覆盖这些规则;
-
人工制定阈值容易受「经验主义」先导,容易出现误判。
所以,对比维度虽然丰富了,但规则制定的难度相对来说提升了 N 个数量级。机器学习的出现,正好可以弥补这个缺点。机器学习通过大量训练数据,从而学习到多变的规则,有效解决人基本无法完成的任务。
下面我们来详细看下特征构建以及机器学习的过程。
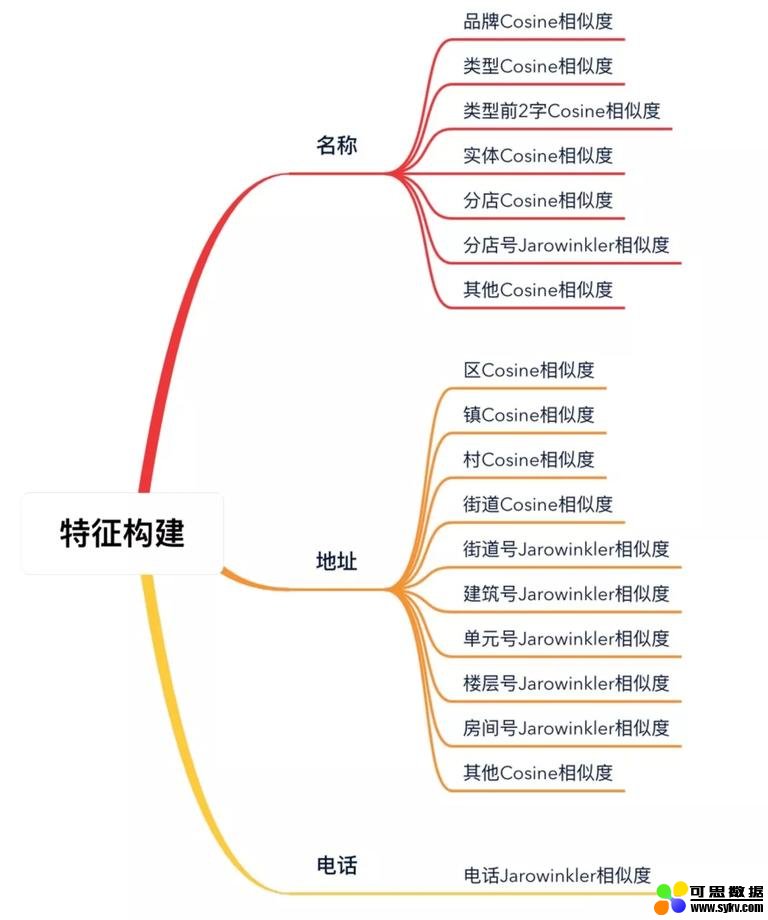
3.2 特征构建
我们花了很大的力气来模拟人的思维进行分词,其实也是为构建特征向量做准备。
特征构建的过程其实也是模拟人思维的一个过程,目的是针对分词的结构化数据进行两两比对,将比对结果数字化以构造特征向量,为机器学习做准备。
对于不同供应商,我们确定能拿到的数据主要包括酒店名称、地址、坐标经纬度,可能获得的数据还包括电话和邮箱。
经过一系列数据调研,最终确定可用的数据为名称、地址、电话,主要是:因为
-
部分供应商经纬度坐标系有问题,精准度不高,因此我们暂不使用,但待聚合酒店距离限制在 5km 范围内;
-
邮箱覆盖率较低,暂不使用。
要注意的是,名称、地址拓展对比维度主要基于其分词结果,但电话数据加入对比的话首先要进行电话数据格式的清洗。
最终确定的特征向量大致如下,因为相似度算法比较简单,这里不再赘述:
3.3 算法选择:决策树
判断酒店是否相同,很明显这是有监督的二分类问题,判断标准为:
-
有人工标注的训练集、验证集、测试集;
-
输入两家酒店,模型返回的结果只分为「相同」或「不同」两类情况。
经过对多个现有成熟算法的对比,我们最终选择了决策树,核心思想是根据在不同 Feature 上的划分,最终得到决策树。每一次划分都向减小信息熵的方向进行,从而做到每一次划分都减少一次不确定性。这里摘录一张图片,方便大家理解:
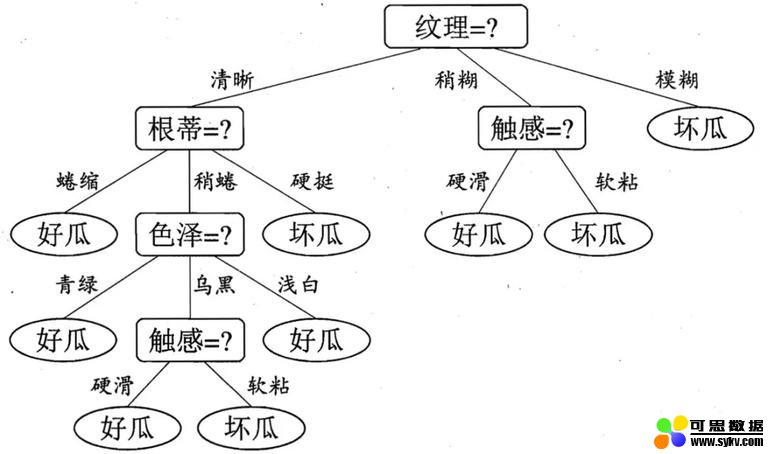
(图源:__《机器学习西瓜书》)
3.3.1 Ada Boosting OR Gradient Boosting
具体的算法我们选择的是 Boosting。「三个臭皮匠,顶过诸葛亮」这句话是对 Boosting 很好的描述。Boosting 类似于专家会诊,一个人决策可能会有不确定性,可能会失误,但一群人最终决策产生的误差通常就会非常小。
Boosting 一般以树模型作为基础,其分类目前主要为 Ada Boosting、Gradient Boosting。Ada Boosting 初次得出来一个模型,存在无法拟合的点,然后对无法拟合的点提高权重,依次得到多个模型。得出来的多个模型,在预测的时候进行投票选择。如下图所示:

Gradient Boosting 则是通过对前一个模型产生的错误由后一个模型去拟合,对于后一个模型产生的错误再由后面一个模型去拟合…然后依次叠加这些模型:
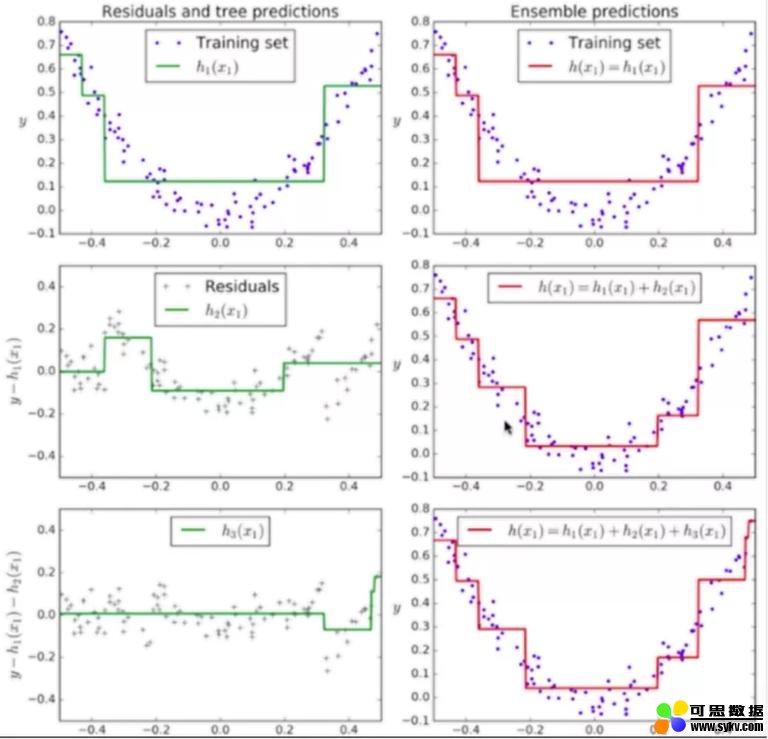
一般来说,Gradient Boosting 在工业界使用的更广泛,我们也以 Gradient Boosting 作为基础。
3.3.2 XGBoost OR LightGBM
XGBoost、LightGBM 都是 Gradient Boosting 的一种高效系统实现。
我们分别从内存占用、准确率、训练耗时方面进行了对比,LightGBM 内存占用降低了很多,准确率方面两者基本一致,但训练耗时却也降低了很多。
内存占用对比:
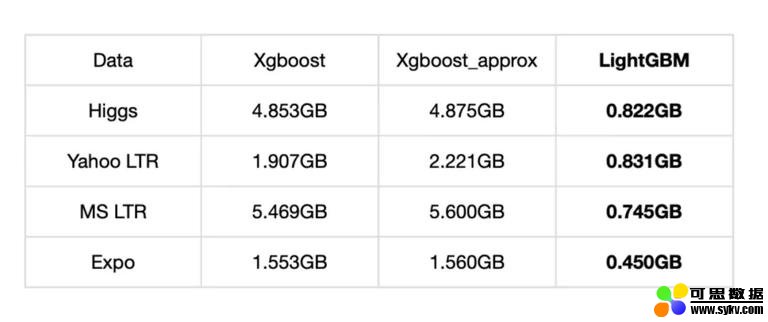
准确率对比:
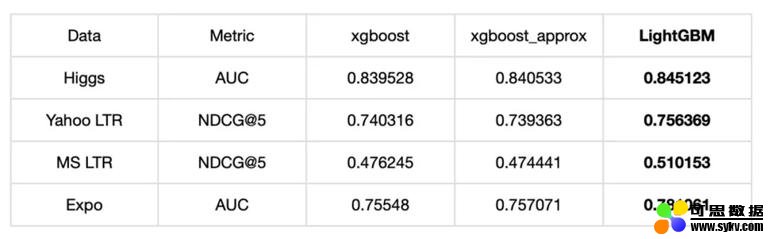
训练耗时对比:
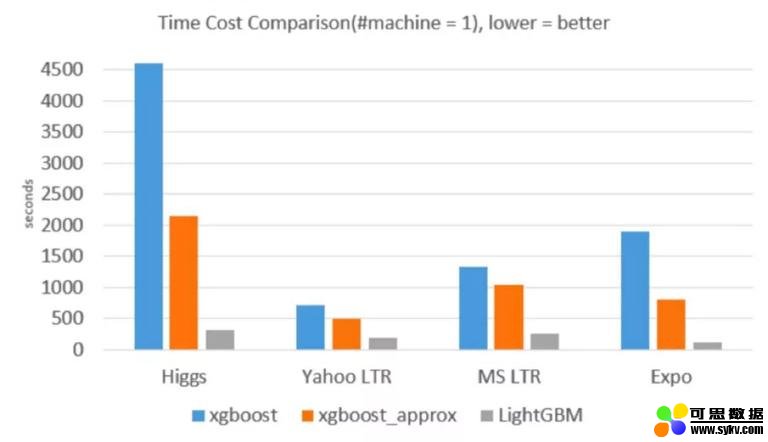
( 图源:微软亚洲研究院)
基于以上对比数据参考,为了模型快速迭代训练,我们最终选择了 LightGBM。
3.4 模型训练迭代
由于使用 LightGBM,训练耗时大大缩小,所以我们可以进行快速的迭代。
模型训练主要关注两方面内容:
-
训练结果分析
-
模型超参调节
3.4.1 训练结果分析
训练结果可能一开始差强人意,没有达到理想的效果,这时需要我们仔细分析什么原因导致的这个结果,是特征向量的问题?还是相似度计算的问题?还是算法的问题?具体原因具体分析,但总归会慢慢达到理想的结果。
3.4.2 模型超参调节
这里主要介绍一些超参数调节的经验。首先大致说一下比较重要的参数:
(1) maxdepth 与 numleaves
maxdepth 与 numleaves 是提高精度以及防止过拟合的重要参数:
-
maxdepth : 顾名思义为「树的深度」,过大可能导致过拟合
-
numleaves 一棵树的叶子数。LightGBM 使用的是 leaf-wise 算法,此参数是控制树模型复杂度的主要参数
(2) feature_fraction 与 bagging_fraction
feature_fraction 与 bagging_fraction 可以防止过拟合以及提高训练速度:
-
feature_fraction : 随机选择部分特征 (0<feature_fraction <1)
-
bagging_fraction 随机选择部分数据 (0<bagging_fraction<1)
(3) lambda_l1 与 lambda_l2
lambda_l1 与 lambda_l2 都是正则化项,可以有效防止过拟合。
-
lambda_l1 :L1 正则化项
-
lambda_l2 :L2 正则化项
3.5 模型效果
经过多轮迭代、优化、验证,目前我们的酒店聚合模型已趋于稳定。
对方案效果的评估通常是凭借「准确率」与「召回率」两个指标。但酒店聚合业务场景下,需要首先保证绝对高的准确率 (聚合错误产生 AB 店影响用户入住),然后才是较高的召回率。
经过多轮验证,目前模型的准确率可以达到 99.92% 以上,召回率也达到了 85.62% 以上:
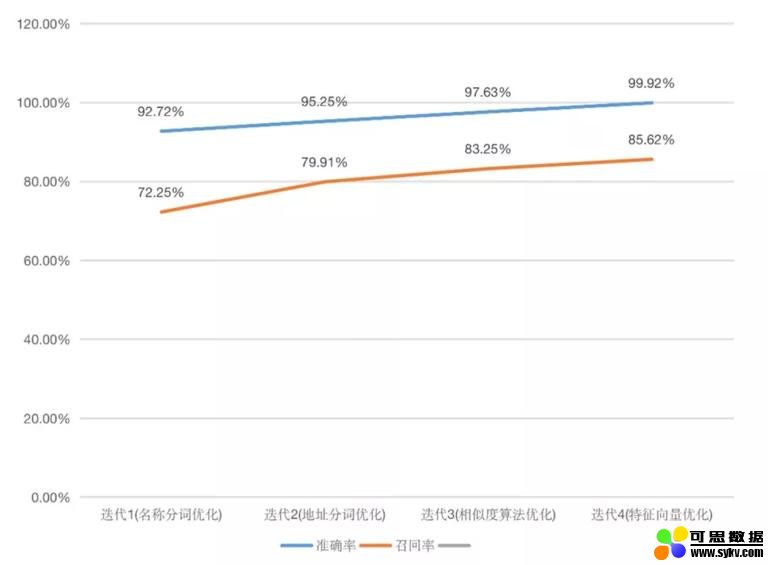
可以看到准确率已经达到一个比较高的水准。但为保险起见,聚合完成后我们还会根据酒店名称、地址、坐标、设施、类型等不同维度建立一套二次校验的规则;同时对于部分当天预订当天入住的订单,我们还会介入人工进行实时的校验,来进一步控制 AB 店出现的风险。
3.6 方案总结
整体方案介绍完后,我们将基于机器学习的酒店聚合流程大致示意为下图:
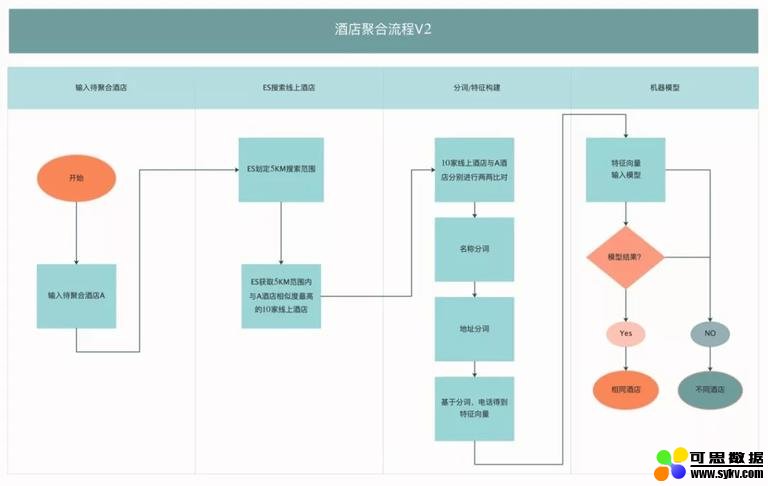
经过上面的探索,我们大致理解了:
-
解决方案都是一个慢慢演进的过程,当发现满足不了需求的时候就会进行迭代;
-
分词解决了对比粒度太粗的缺点,模拟人的思维进行断句分词;
-
机器学习可以得到复杂的规则,通过大量训练数据解决人无法完成的任务。
Part 4 写在最后
新技术的探索充满挑战也很有意义。未来我们会进一步迭代优化,高效完成酒店的聚合,保证信息的准确性和及时性,提升用户的预订体验,比如:
-
进行不同供应商国内酒店资源的坐标系统一。坐标对于酒店聚合是很重要的 Feature,相信坐标系统一后,酒店聚合的准确率、召回率会进一步提高。
-
打通风控与聚合的闭环。风控与聚合建立实时双向数据通道,从而进一步提高两个服务的基础能力。
上述主要讲的是国内酒店聚合的演进方案,对于「国外酒店」数据的机器聚合,方法其实又很不同,比如国外酒店名称、地址如何分词,词形还原与词干提取怎么做等,我们在这方面有相应的探索和实战,总体效果甚至优于国内酒店的聚合,后续我们也会通过文章和大家分享,希望感兴趣的同学持续关注。
** 本文作者:** 刘书超,交易中心 - 酒店搜索研发工程师;贺夏龙、康文云,智能中台 - 内容挖掘工程师。

时间:2020-01-19 00:00 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
- [机器学习]一文详解深度学习最常用的 10 个激活函数
- [机器学习]增量学习(Incremental Learning)小综述
- [机器学习]盘点近期大热对比学习模型:MoCo/SimCLR/BYOL/SimSi
- [机器学习]深度学习中的3个秘密:集成、知识蒸馏和蒸馏
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]深度学习三大谜团:集成、知识蒸馏和自蒸馏
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]“狂欢”的半导体设备
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
相关推荐:
网友评论:















